






# 1.列的基本查询
基本用法:
/* distinct 可选,剔除重复数据,* 所有列,或可指定列 */
SELECT distinct */(column1,column2...)
FROM table_name;
# 2. 列的别名和列运算
基本用法:
/* 在select时 可以进行列运算,并将运算结果传递给指定别名列显示 */
SELECT column_name AS别名 FROM table_name;
如:select stu_name,stu_score +23 as new_score from stu;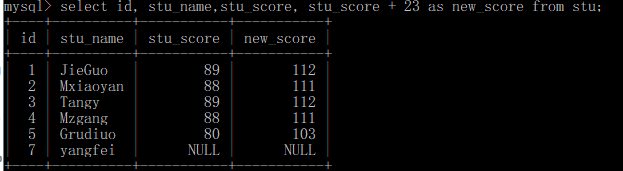 stu_score + 23
stu_score + 23
# 3. select 的where 子句使用
基本用法:
/* where 后面的子句是限定条件,可以理解为表达式,表达式为真则执行select语句 */
SELECT * FROM table_name
WHERE expr;
如:select * from stu where stu_score in (52,92,23,10); where子句的表达式条件
where子句的表达式条件
# 4. order by
基本用法:
SELECT * FROM table_name
WHERE expr
ORDER BYcolumn ASC(升)/DESC(降);
# 5.count 统计
基本用法:
/* count统计列表行记录的 */
SELECT COUNT(*)/COUNT(column_name) FROM table_name
WHERE expr;
如:select count(distinct(stu_score))from stu where stu_score >0;
1> COUNT(*) 和COUNT(column_name) 的区别
COUNT(*) :会将含 null 的所有记录统计进来;
COUNT(column_name) :会统计出有效的数据记录;
# 6. sum 合计
基本用法:
/* sum统计列表某列的总和 */
SELECT SUM(column_name) FROM table_name
WHERE expr;
# 7. avg 合计
/* 平均值的计算 */
SELECT AVG(column_name1) ,AVG(column_name2)
FROM table_name;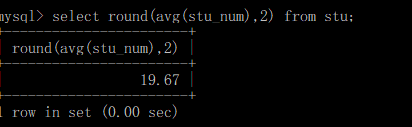 round(expr,x)精度计算
round(expr,x)精度计算
# 8. group by 和 having
基本用法:
/* group by进行分组,having 在group by 分组统计的结果中筛选 */
SELECT column1,column2,column3...
FROM table_name
GROUP BY column_name
HAVING expr;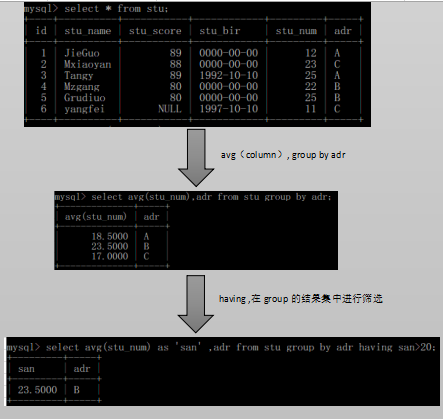 having 进行筛选结果集
having 进行筛选结果集















 544
544











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









