






元素定位是web自动化测试的基础。只有先从页面众多元素中唯一定位到元素,我们才能进行后续操作。本文总结了八大元素定位策略和python selenium 18种定位方法。
一、元素定位前的准备
1、以百度首页为实例。我们需要先打开页面。
#引入webdriver模块
from selenium importwebdriver
?#创建一个Chrom浏览器对象
driver =webdriver.Chrome()
?#打开百度首页
driver.get("https://www.baidu.com/")
2、我们借助Chrome定位工具查看页面元素。
方法(1)在浏览器中按F12会弹出开发者工具选项。选择Elements,鼠标单击最左上角的
 后,划动到页面中要操作的元素,单击一下,对应的html元素就会突出显示。
后,划动到页面中要操作的元素,单击一下,对应的html元素就会突出显示。
方法(2)通过右击页面元素,选择菜单检查。就会弹出开发者工具选项,并自动突出显示对应的html元素。
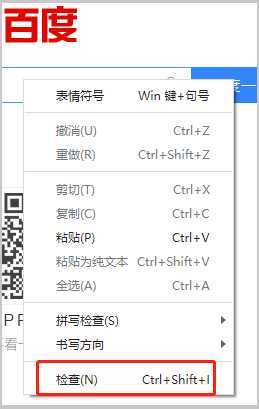
(图1)
二、八大定位策略
1、ID定位
id是指页面元素的属性名id值,因为元素id在整个页面中是唯一的,所以如果元素有id属性,通过id定位是首选的方式。
如下图,可以看到百度搜索框的id为kw。

(图2)
driver.find_element_by_id("kw")
注意:id值也有可能是动态变化的,如果id带数字或者使用不太规则的字符串,那么很可能每次访问这个页面,id都会不一样。这种情况下,不适合通过id来定位元素。
2、name定位
通过元素的name属性进行定位。如上图(图2),百度搜索框的name为wd。
driver.find_element_by_name("wd") #1个元素 - 匹配到的第一个元素
driver.find_elements_by_name("wd") #多个元素,放在列表
3、Class name定位
通过元素的class属性进行定位。如图2所示,百度搜索框的class_name为s_ipt。
driver.find_element_by_class_name("s_ipt")
driver.find_elements_by_class_name("s_ipt")
注意:class属性可能有空格隔开多个class值,但find_element_by_class_name方法的参数只能是一个class值
4、Tag name定位
通过元素的标签名进行定位。如input是一个标签名称。
driver.find_element_by_tag_name("input")
driver.find_elements_by_tag_name("input")
备注:标签名定位的方法基本不用,因为相同标签的元素太多了。
5&6、Link定位和Partial link定位
针对页面的链接(a标签)提供的两种定位方式

(图3)
如上图,以百度首页右上角的登录链接为例
1)link定位--链接文本内容全匹配
driver.find_element_by_link_text("登录")
driver.find_elements_by_link_text("登录")
2)partial link定位--链接文本内容部分匹配(包含)
driver.find_element_by_partial_link_text("登")
driver.find_elements_by_partial_link_text("登")
以上6种定位策略都是针对元素的单一特征来定位元素。而接下来介绍的css定位和Xpath定位可以实现各种组合,基本可以覆盖所有元素的定位。
7、css定位(css_selector)
#driver.find_elements_by_css_selector(css表达式)
driver.find_elements_by_css_selector(‘input#kw.s-plit‘)
备注:css定位表达式还没深入学习,暂不做详细总结。
8、Xpath定位
driver.find_elements_by_xpath(xpath定位表达式)
xpath定位表达式可以通过工具获取,在F2开发者工具中,鼠标邮件点击html代码选择copy,可以Copy Full Xpath、Copy Xpath。前者得到的是绝对路径,后者得到的可能是相对路径混合绝对路径。
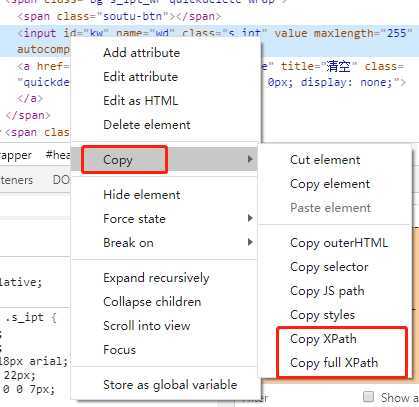
(图4)
备注:不建议使用工具copy,建议手动写。因为copy到的大部分是绝对定位(后文会介绍绝对定位方式的劣势)
小技巧:
在Element区域,按Ctrl+F就会弹出元素查找框,输入定位表达式,就可以检测定位表达式是否正确,是否唯一。
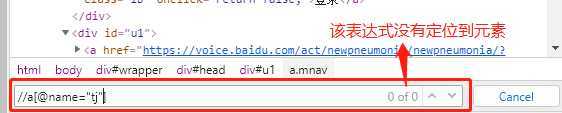
(图5)
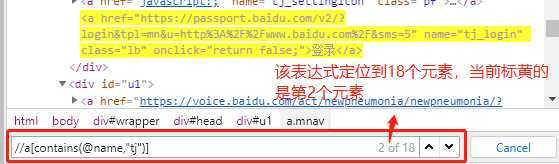
(图6)

(图7)
8.1 xpath基本定位语法
/ 绝对定位,从根节点选取
// 相对定位,从匹配选择的当前节点选择文档中的节点,而不考虑他们的位置。
. 选取当前节点
.. 选取当前节点的父
@ [email protected]="xxx" @id="xxx"。属性放在中括号[]中
* 通配符。匹配所有标签
@* 匹配所有属性
8.2 绝对定位和相对定位
8.2.1绝对定位
特点:
以单斜杆(/)开头
从页面根元素(html标签)开始,严格按照元素在html页面中的位置和顺序向下查找
单斜杆(/)左边的元素为父元素,右边的元素为直系子元素
劣势:
页面元素一旦发生变化,绝对路径就会失效。所以一般不适用绝对路径来定位元素。
表达式:
/html/body/div[1]/div[1]/div[4]/div[1]/div/form/span[1]/input
8.2.2相对定位
特点:
两个斜杆(//)开头代表相对路径。
不考虑元素在页面当中的绝对路径和位置
考虑页面是否存在符合表达式的元素即可
表达式:
(相对定位有多种表达式)
1、使用标签名+节点属性定位
语法://标签名[@属性名=值]
实例:
//i[@class="ing"]
//*[@*="ing"]
2、使用文本匹配定位
语法://标签名[text()=值]
实例:
//a[text()="公告"]
3、模糊匹配(包含)
语法:
//标签名[contains(@属性,值)]
//标签名[contains(text(),值)]
实例:
//a[contains(@href,"/Notify/index/courseid/")]
//a[contains(text(),"公告")]
4、逻辑运算 来组合更多的元素特征,and or
语法:
//标签名[@属性=值 and contains(@属性,值) and text()=值]?
//标签名[@属性=值 or @属性=值]
实例:
//a[text()="公告" and contains(@href,"/Notify/index/courseid/")]
5、层级定位
语法://一级元素//二级元素//N级元素
实例:
//div[@id="number-attend"]//i[@class="ing"]
6、组合元素索引(下标)定位
实例:
//li[@class="num"][2]//img
注意:下标是从1开始
7、轴定位
分析元素之间的关系
1)通过兄弟找到自己
2)通过后代元素找到祖先元素
备注:轴定位跟层级定位不同,层级定位是根据祖先元素找后代元素
轴运算:
ancestor:祖先节点 包括父
parent:父节点
preceding:当前元素节点表圈之前的所有节点(html页面先后顺序)
preceding-sibling:当前元素节点标签之前的所有兄弟节点(同级)
following:当前元素节点标签之后的所有节点(html页面先后顺序)
following-sibling:当前元素节点标签之后的所有兄弟节点(同级)
语法:已知的元素/轴名称::标签名称[@属性=值]
实例:
//a[contains(@title,"元素定位")]/ancestor::div[@class="work-new-l fl"]/following-sibling::div
备注:轴定位较多的应用场景是页面显示为一个表格样式的数据列,通常需要通过轴运算组合来定位元素。
三、selenium webdriver的18种元素定位方法
细心的朋友可能发现了,前面8种定位策略,webdriver都提供了2个方法,一个方法return的是一个WebElement(元素对象),另一个return的是一个list of WebElement(元素对象的列表)。
总结下来,对应有16个webdriver方法:
1.id定位:find_element_by_id(self, id_)2.name定位:find_element_by_name(self, name)3.class定位:find_element_by_class_name(self, name)4.tag定位:find_element_by_tag_name(self, name)5.link定位:find_element_by_link_text(self, link_text)6.partial_link定位:find_element_by_partial_link_text(self, link_text)7.xpath定位:find_element_by_xpath(self, xpath)8.css定位:find_element_by_css_selector(self, css_selector)9.id复数定位:find_elements_by_id(self, id_)10.name复数定位:find_elements_by_name(self, name)11.class复数定位:find_elements_by_class_name(self, name)12.tag复数定位:find_elements_by_tag_name(self, name)13.link复数定位:find_elements_by_link_text(self, text)14.partial_link复数定位:find_elements_by_partial_link_text(self, link_text)15.xpath复数定位:find_elements_by_xpath(self, xpath)16.css复数定位:find_elements_by_css_selector(self, css_selector)
另外2种是参数化的方法
17.find_element(self, by=By.ID, value=None)18.find_elements(self, by=By.ID, value=None)
参数by是定位的类型,包括By.ID,By.NAME,By.CLASS_NAME,By.TAG_NAME,By.LINK_TEXT,By.PARTIAL_LINK_TEXT,By.XPATH,By.CSS_SELECTOR,对应上面的8种定位策略
参数value是具体定位方式
实例:
element = driver.find_element(By.ID,‘kw‘)
elements = driver.find_elements(By.ID,‘kw‘)
注意:使用By定位方式,需先导入By类。
from selenium.webdriver.common.by import By
ps:有兴趣的朋友查看底层源码,会发现前8个方法调用了第17个方法find_element,第9-16个方法调用了第18个方法find_elements。
原文:https://www.cnblogs.com/malus-fish/p/12441849.html















 1216
1216











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









