






from bs4 import BeautifulSoup
import pandas as pd
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36'}
获取一级代码、名称、下一级链接
通过设置参数originUrl来调整爬取的年份
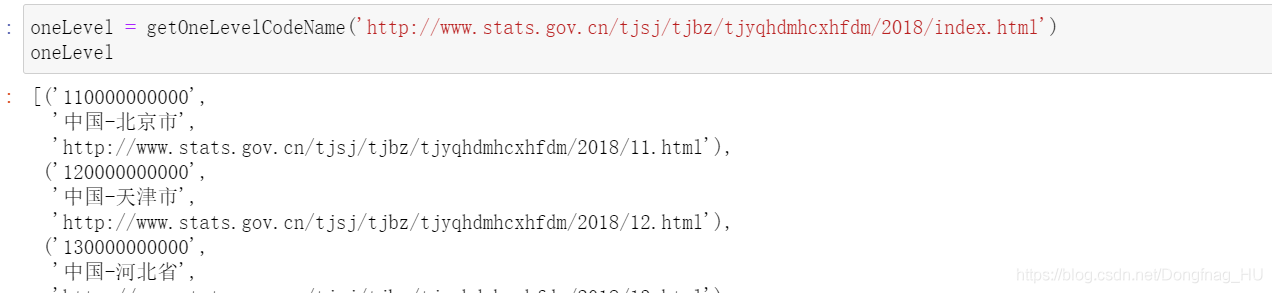
def getOneLevelCodeName(originUrl = 'http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2019/index.html'):
web = requests.get(originUrl,headers=headers) #获取网页
web.encoding = web.apparent_encoding #设置编码
soup = BeautifulSoup(web.text,'html.parser') #解析网页
provinceList = soup.select('.provincetr') #查找类名为provincetr的内容
oneLevelWeb = []
for table in provinceList:
for province in table.select('a'):
oneLevelWeb.append((province['href'],province.text))#获取下一级短链接、获取省名
oneLevelWebUrl = [(url[0][0:2]+'0000000000','中国-'+url[1],originUrl[0:54]+url[0]) for url in oneLevelWeb] #构建区划代码、省名、下一级链接
return oneLevelWebUrl
获取二级代码、名称、下一级链接
#根据一级链接,获取下一级
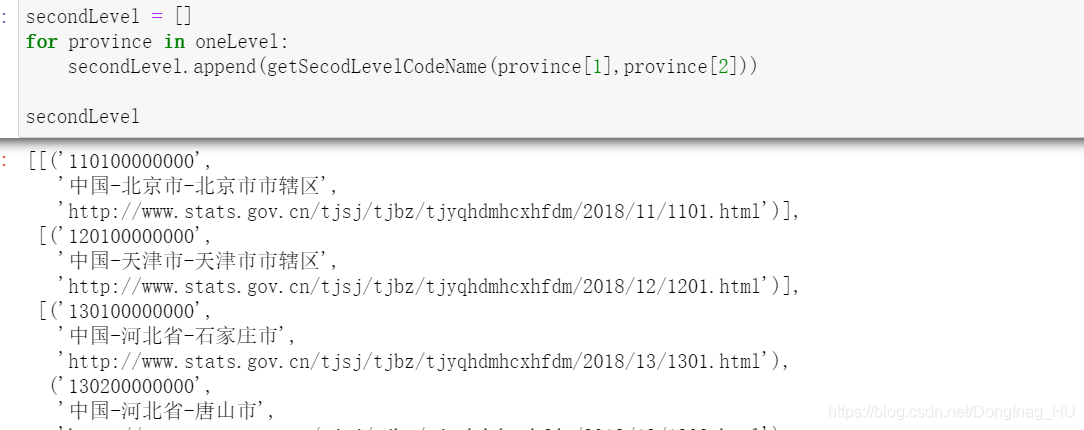
def getSecodLevelCodeName(proLevelName=None,url='None'):
if proLevelName is None or url == 'None':
pass
else:
web = requests.get(url,headers=headers)
web.encoding = web.apparent_encoding
soup = BeautifulSoup(web.text,'html.parser')
secondLevelCodeNameList = soup.select('.citytr')
retList = []
for tag in secondLevelCodeNameList:
if tag.text[12:] == '市辖区':
retList.append((tag.text[0:12],proLevelName+'-'+proLevelName.split('-')[-1]+tag.text[12:],url[0:54]+tag.select('a')[0]['href']))
else:
retList.append((tag.text[0:12],proLevelName+'-'+tag.text[12:],url[0:54]+tag.select('a')[0]['href']))
return retList
获取三级代码、名称、下一级链接
#根据二级链接,获取下一级
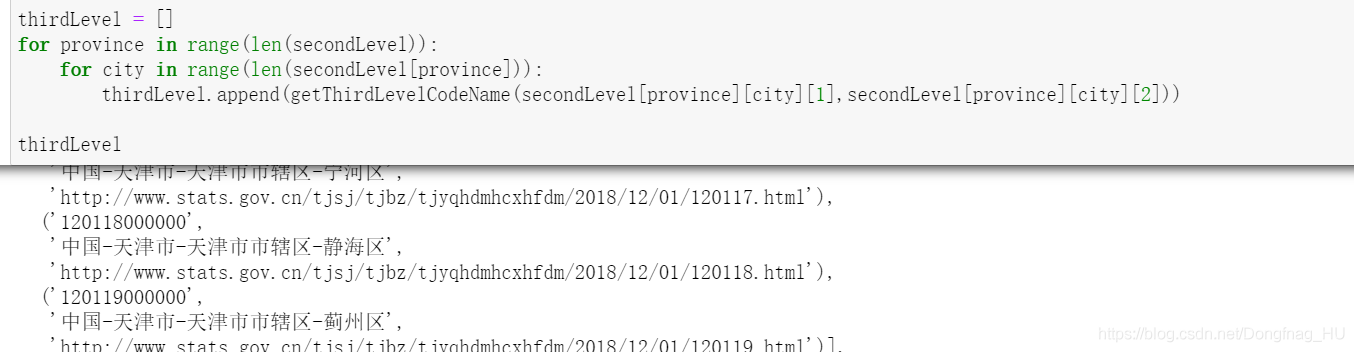
def getThirdLevelCodeName(proLevelName=None,url='None'):
if proLevelName is None or url == 'None':
pass
else:
web = requests.get(url,headers=headers)
web.encoding = web.apparent_encoding
soup = BeautifulSoup(web.text,'html.parser')
thirdLevelCodeNameList = soup.select('.countytr')
retList = []
for tag in thirdLevelCodeNameList:
try:
retList.append((tag.text[0:12],proLevelName+'-'+tag.text[12:],url[0:56]+'/'+tag.select('a')[0]['href']))
except:
retList.append((tag.text[0:12],proLevelName+'-'+proLevelName.split('-')[-1]+tag.text[12:],'None'))
return retList
获取四级代码、名称、下一级链接
#根据三级链接,获取下一级
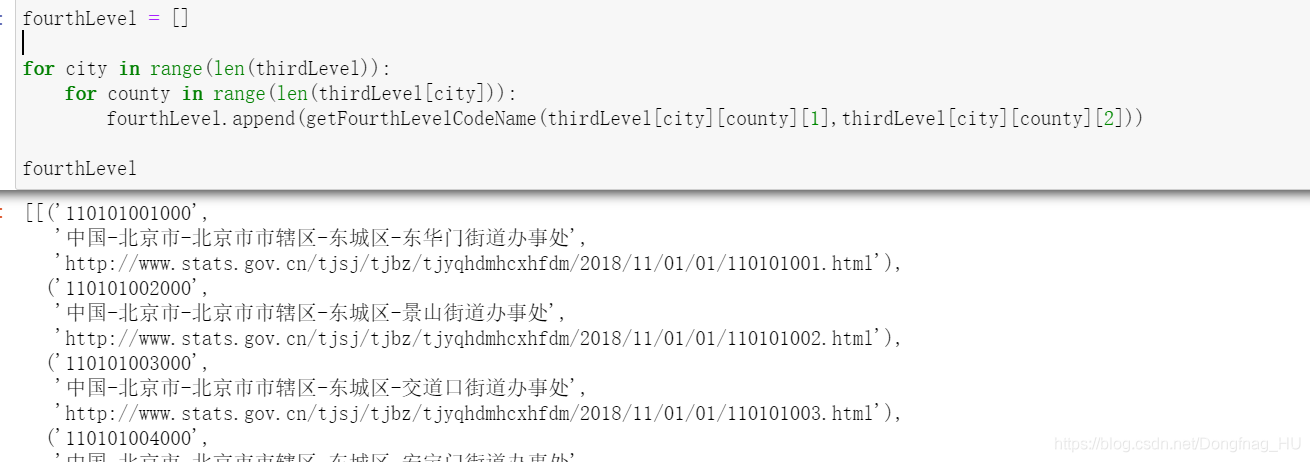
def getFourthLevelCodeName(proLevelName=None,url='None'):
if proLevelName is None or url == 'None':
pass
else:
web = requests.get(url,headers=headers)
web.encoding = web.apparent_encoding
soup = BeautifulSoup(web.text,'html.parser')
fourthLevelCodeNameList = soup.select('.towntr')
retList = []
for tag in fourthLevelCodeNameList:
retList.append((tag.text[0:12],proLevelName+'-'+tag.text[12:],url[0:60]+tag.select('a')[0]['href']))
return retList
转为DataFrame,输出excel文件
pd_oneLevel = pd.DataFrame(oneLevel)
pd_oneLevel
pd_secondLevel = pd.concat([pd.DataFrame(data) for data in secondLevel])
pd_secondLevel
pd_thirdLevel = pd.concat([pd.DataFrame(data) for data in thirdLevel])
pd_thirdLevel
pd_fourthLevel = pd.concat([pd.DataFrame(data) for data in fourthLevel])
pd_fourthLevel
pd_allLevel = pd.concat([pd_oneLevel,pd_secondLevel,pd_thirdLevel,pd_fourthLevel],ignore_index=True)
pd_allLevel.columns = ['区划代码','名称','下一级网址']
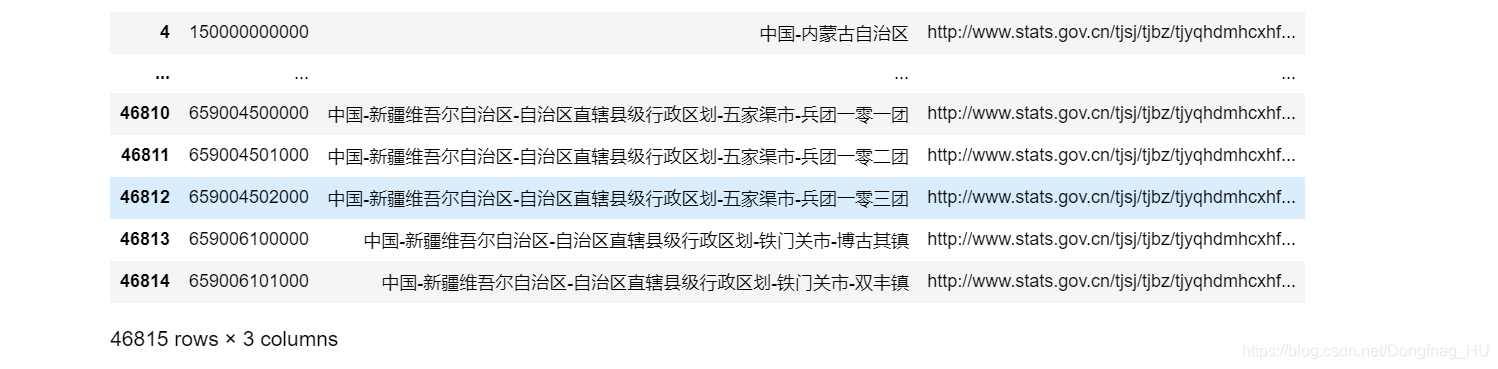
pd_allLevel
保存到当前目录
import os
pd_allLevel.to_excel(r''+os.path.realpath('__file__')[0:-8]+'2018区划代码及名称.xlsx',index=False)















 616
616











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









