








子查询(Subquery)的优化一直以来都是 SQL 查询优化中的难点之一。关联子查询的基本执行方式类似于 Nested-Loop,但是这种执行方式的效率常常低到难以忍受。当数据量稍大时,必须在优化器中对其进行去关联化(Decoorelation 或 Unnesting),将其改写为类似于 Semi-Join 这样的更高效的算子。
前人已经总结出一套完整的方法论,理论上能对任意一个查询进行去关联化。本文结合 SQL Server 以及 HyPer 的几篇经典论文,由浅入深地讲解一下这套去关联化的理论体系。它们二者所用的方法大同小异,基本思想是想通的。
本文的例子都基于 TPC-H 的表结构。
子查询简介
子查询是定义在 SQL 标准中一种语法,它可以出现在 SQL 的几乎任何地方,包括 SELECT, FROM, WHERE 等子句中。
总的来说,子查询可以分为关联子查询(Correlated Subquery)和非关联子查询(Non-correlated Subquery)。后者非关联子查询是个很简单的问题,最简单地,只要先执行它、得到结果集并物化,再执行外层查询即可。下面是一个例子:
|
|
▲ TPCH-13 是一个非关联子查询
非关联子查询不在本文讨论范围之列,除非特别声明,以下我们说的子查询都是指关联子查询。
关联子查询的特别之处在于,其本身是不完整的:它的闭包中包含一些外层查询提供的参数。显然,只有知道这些参数才能运行该查询,所以我们不能像对待非关联子查询那样。
根据产生的数据来分类,子查询可以分成以下几种:
标量(Scalar-valued)子查询:输出一个只有一行一列的结果表,这个标量值就是它的结果。如果结果为空(0 行),则输出一个 NULL。但是注意,超过 1 行结果是不被允许的,会产生一个运行时异常。
标量子查询可以出现在任意包含标量的地方,例如 SELECT、WHERE 等子句里。下面是一个例子:
SELECT c_custkey
FROM CUSTOMER
WHERE 1000000 < (
SELECT SUM(o_totalprice)
FROM ORDERS
WHERE o_custkey = c_custkey
)
▲ Query 1: 一个出现在 WHERE 子句中的标量子查询,关联参数用红色字体标明了
SELECT o_orderkey, (
SELECT c_name
FROM CUSTOMER
WHERE c_custkey = o_custkey
) AS c_name FROM ORDERS
▲ Query 2: 一个出现在 SELECT 子句中的标量子查询
存在性检测(Existential Test)子查询:特指 EXISTS 的子查询,返回一个布尔值。如果出现在 WHERE 中,这就是我们熟悉的 Semi-Join。当然,它可能出现在任何可以放布尔值的地方。
SELECT c_custkey
FROM CUSTOMER
WHERE c_nationkey = 86 AND EXISTS(
SELECT * FROM ORDERS
WHERE o_custkey = c_custkey
)
▲ Query 3: 一个 Semi-Join 的例子
集合比较(Quantified Comparision)子查询:特指 IN、SOME、ANY 的查询,返回一个布尔值,常用的形式有:x = SOME(Q) (等价于 x IN Q)或 X <> ALL(Q)(等价于 x NOT IN Q)。同上,它可能出现在任何可以放布尔值的地方。
SELECT c_name
FROM CUSTOMER
WHERE c_nationkey <> ALL (SELECT s_nationkey FROM SUPPLIER)
▲ Query 4: 一个集合比较的非关联子查询
原始执行计划
我们以 Query 1 为例,直观地感受一下,为什么说关联子查询的去关联化是十分必要的。
下面是 Query 1 的未经去关联化的原始查询计划(Relation Tree)。与其他查询计划不一样的是,我们特地画出了表达式树(Expression Tree),可以清晰地看到:子查询是实际上是挂在 Filter 的条件表达式下面的。
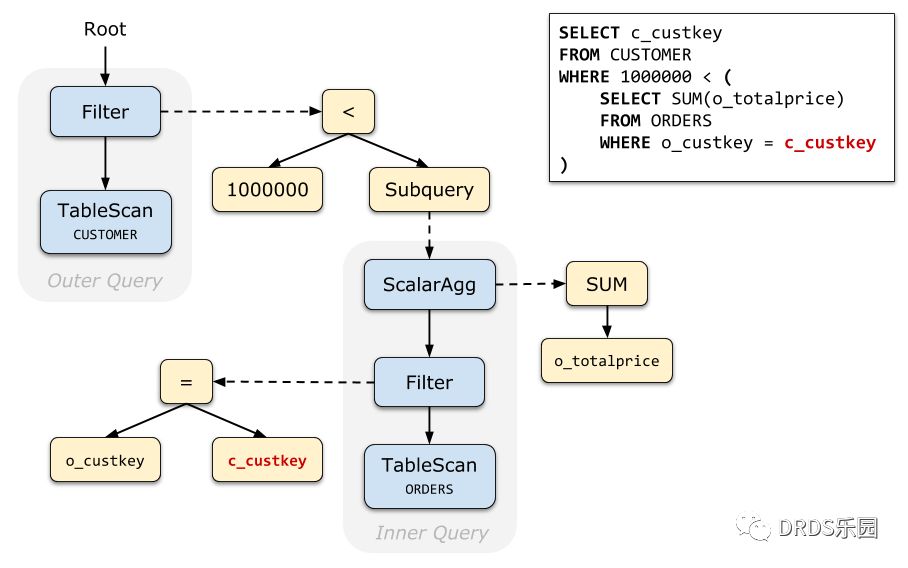
实际执行时,查询计划执行器(Executor)在执行到 Filter 时,调用表达式执行器(Evaluator);由于这个条件表达式中包含一个标量子查询,所以 Evaluator 又会调用 Executor 计算标量子查询的结果。
这种 Executor - Evaluator - Executor 的交替调用十分低效!考虑到 Filter 上可能会有上百万行数据经过,如果为每行数据都执行一次子查询,那查询执行的总时长显然是不可接受的。
Apply 算子
上文说到的 Relation - Expression - Relation 这种交替引用不仅执行性能堪忧,而且,对于优化器也是个麻烦的存在——我们的优化规则都是在匹配并且对 Relation 进行变换,而这里的子查询却藏在 Expression 里,令人无从下手。
为此,在开始去关联化之前,我们引入 Apply 算子:
Apply 算子(也称作 Correlated Join)接收两个关系树的输入,与一般 Join 不同的是,Apply 的 Inner 输入(图中是右子树)是一个带有参数的关系树。
Apply 的含义用下图右半部分的集合表达式定义:对于 Outer Relation R" role="presentation" style="display: inline-block; line-height: 0; font-size: 15.96px; overflow-wrap: normal; word-spacing: normal; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border-width: 0px; border-style: initial; border-color: initial; padding-top: 1px; padding-bottom: 1px;">RR 中的每一条数据 r" role="presentation" style="display: inline-block; line-height: 0; font-size: 15.96px; overflow-wrap: normal; word-spacing: normal; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border-width: 0px; border-style: initial; border-color: initial; padding-top: 1px; padding-bottom: 1px;">rr,计算 Inner Relation E(r)" role="presentation" style="display: inline-block; line-height: 0; font-size: 15.96px; overflow-wrap: normal; word-spacing: normal; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border-width: 0px; border-style: initial; border-color: initial; padding-top: 1px; padding-bottom: 1px;">E(r)E(r),输出它们连接(Join)起来的结果 r⊗E(r)" role="presentation" style="display: inline-block; line-height: 0; font-size: 15.96px; overflow-wrap: normal; word-spacing: normal; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border-width: 0px; border-style: initial; border-color: initial; padding-top: 1px; padding-bottom: 1px;">r⊗E(r)r⊗E(r)。Apply 的结果是所有这些结果的并集(本文中说的并集指的是 Bag 语义下的并集,也就是 UNION ALL)。
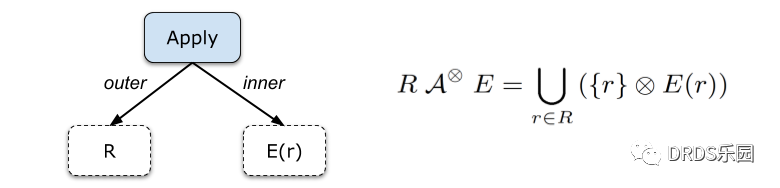
Apply 是 SQL Server 的命名,它在 HyPer 的文章中叫做 Correlated Join。它们是完全等价的。考虑到 SQL Server 的文章发表更早、影响更广,本文中都沿用它的命名。
根据连接方式(⊗" role="presentation" style="display: inline-block; line-height: 0; font-size: 15.96px; overflow-wrap: normal; word-spacing: normal; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border-width: 0px; border-style: initial; border-color: initial; padding-top: 1px; padding-bottom: 1px;">⊗⊗)的不同,Apply 又有 4 种形式:
Cross Apply A×" role="presentation" style="display: inline-block; line-height: 0; font-size: 15.96px; overflow-wrap: normal; word-spacing: normal; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border-width: 0px; border-style: initial; border-color: initial; padding-top: 1px; padding-bottom: 1px;">A×A×:这是最基本的形式,行为刚刚我们已经描述过了;
Left Outer Apply ALOJ" role="presentation" style="display: inline-block; line-height: 0; font-size: 15.96px; overflow-wrap: normal; word-spacing: normal; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 84
84











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









