







简介:《Microsoft.Press Inside Microsoft SQL Server 2005 Storage Engine》详细探讨了SQL Server 2005存储引擎的内部机制,覆盖了数据页、事务管理、查询优化、并发控制、备份与恢复等关键概念。本书为数据库管理员和开发人员提供深入理解存储引擎的工作原理、性能优化和数据管理的实践指导。书中还介绍了分区、内存管理、文件组织、临时存储结构以及性能监控与调优等方面的技术要点。 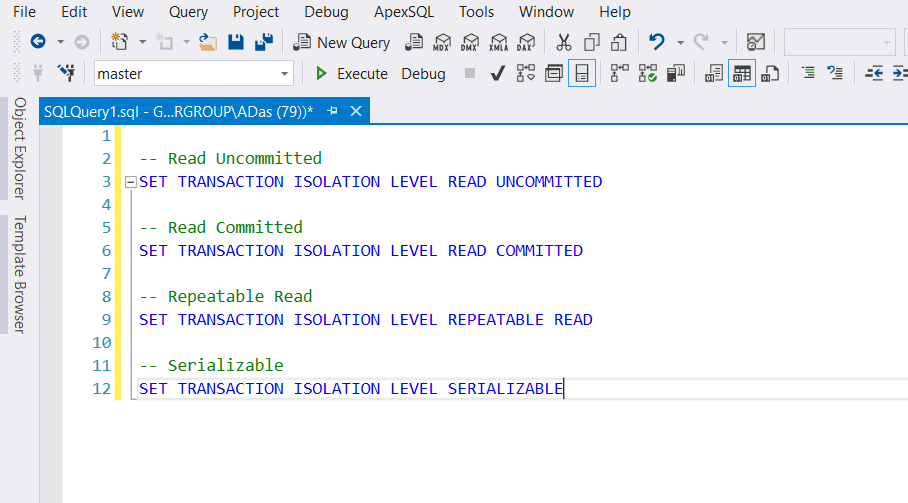
1. 深入理解SQL Server 2005存储引擎
1.1 存储引擎的角色与功能
SQL Server存储引擎是数据库管理系统的核心,负责数据的存储、检索、事务处理及并发控制。作为数据管理的基础,存储引擎实现了SQL Server的高性能和可靠性。
1.2 存储引擎的历史演变
从早期版本到SQL Server 2005,存储引擎经历了重大改革。SQL Server 2005存储引擎不仅提供了增强的性能和稳定性,还引入了对.NET框架的支持,为数据库管理提供了更多的灵活性。
1.3 SQL Server 2005存储引擎的特性
SQL Server 2005的存储引擎通过一系列新特性,如分区表、在线索引操作、以及对全文搜索的改进,提升了数据库的可维护性和性能。这些特性在现代数据库管理中仍然发挥着重要作用。
本章我们将探索SQL Server 2005存储引擎的基础结构,并对其关键特性进行深入分析。理解这些信息对于数据库管理员在维护和优化SQL Server 2005环境时至关重要。
2. 数据页与索引结构的探索
数据页和索引结构是SQL Server存储引擎的核心组件,它们共同支撑着数据库查询的效率和数据的持久化。在这一章节中,我们将深入分析数据页的结构组成、内部数据的组织方式,同时探讨索引的类型及其选择,以及索引碎片整理和重建策略。
2.1 数据页结构分析
2.1.1 数据页的组成和作用
数据页是SQL Server存储数据的基本单位,是8KB大小的块,它可以存储表中的数据行或索引的节点。数据页的组成可以细分为页头、数据行、行偏移数组和空闲空间。
- 页头(Page Header) :存储页的元数据,如页ID、页类型、行计数器等。
- 数据行(Row Data) :实际存储用户数据的部分。
- 行偏移数组(Row Offset Array) :记录数据行在页中的位置,便于SQL Server进行数据检索。
- 空闲空间(Free Space) :用于新数据插入或现有数据更新时的空间扩展。
在SQL Server中,数据页的作用远不止存储数据那么简单。它还是实现数据快速读写的基石,通过页的链接和索引指针,SQL Server能够高效地在磁盘上定位和检索数据。
2.1.2 数据页内部数据的组织方式
数据页内部数据的组织方式对于数据库的性能有显著影响。SQL Server使用行溢出和行链等技术来存储大型数据或当一行数据过于庞大时。
- 行溢出(Row Overflow) :当数据行超出8KB限制时,SQL Server将该行的某些列移动到另一个特殊的页中。
- 行链(Row Chaining) :如果数据行由于长度原因不能完全放入单个数据页中,则会跨越多个页。
在理解了数据页结构和组织方式后,我们可以更有效地进行索引设计和数据访问优化。数据页的合理使用和优化是保证数据库性能的关键因素。
2.2 索引结构及其优化
2.2.1 索引的类型与选择
索引是数据库查询优化的重要手段,它能够显著提高数据检索的速度。SQL Server提供了多种索引类型,包括聚集索引(Clustered Index)、非聚集索引(Nonclustered Index)、唯一索引(Unique Index)、全文索引(Full-text Index)和空间索引(Spatial Index)。
- 聚集索引 :决定了表中数据行的物理顺序。
- 非聚集索引 :具有自己的索引结构,数据行的物理顺序与聚集索引或表中的顺序无关。
- 唯一索引 :确保表中每一行都有一个唯一值。
- 全文索引 :用于全文搜索。
- 空间索引 :用于对空间数据类型列进行索引。
索引的选择需要根据实际的应用场景和查询需求来决定。一般来说,聚集索引最好用于主键列,而非聚集索引适用于经常出现在查询条件中的列。
2.2.2 索引碎片整理和重建策略
随着数据库的持续操作,如插入、删除和更新,索引可能会产生碎片。索引碎片会影响查询性能,因此需要定期进行整理或重建。
- 索引碎片整理 :通过重新排列物理页,使得索引数据更加连续。
- 索引重建 :重建索引是重新构建索引的过程,可以将数据重新组织到新的数据页中。
对于碎片的处理,可以使用系统存储过程 sp_helpindex 来检查索引碎片情况,并根据碎片程度选择碎片整理或重建索引的操作。在高并发的生产环境中,应该谨慎选择索引维护的时间窗口,以避免影响到业务操作。
-- 示例:使用系统存储过程检查表的索引碎片情况
EXEC sp_helpindex 'YourTableName';
整理索引时,可以使用 DBCC INDEXDEFRAG 命令来减少索引碎片。而重建索引则可以使用 ALTER INDEX 命令或 CREATE INDEX 命令。
-- 示例:整理表的聚集索引碎片
DBCC INDEXDEFRAG (DatabaseName, YourTableName, YourIndexName);
通过上述代码和解释,我们可以看到,索引的维护是一个重要的任务,需要根据数据库的操作状况和性能要求进行合理的安排和调整。
在本章中,我们深入探讨了SQL Server中的数据页和索引结构,理解了数据页的内部组成和作用以及索引的类型和选择。通过分析索引碎片整理和重建的策略,我们学会了如何优化索引以提升数据库性能。这些都是提升数据库管理技能和优化数据库性能的重要组成部分。在下一章中,我们将继续探讨事务管理与ACID属性的实现,深入了解事务的机制和保证数据库一致性的核心原则。
3. 事务管理与ACID属性的实现
3.1 事务管理的机制
3.1.1 事务的定义和属性
事务是数据库管理系统执行过程中的一个逻辑单位,由一个或多个操作序列组成,这些操作要么全部执行,要么全部不执行,是恢复和并发控制的基本单位。事务具有四个基本属性,通常称为ACID属性,即原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)。
原子性保证了事务内的操作要么全部完成,要么全部不完成。一致性确保事务将数据库从一个一致状态转换到另一个一致状态。隔离性指的是在并发环境中,当多个事务同时存取数据库时,每个事务应该不受其他事务的干扰。持久性表示一旦事务完成,它的结果就是永久性的,即使数据库崩溃也不会丢失数据。
3.1.2 事务的生命周期和隔离级别
事务的生命周期包括以下几个阶段:开始事务、执行操作、提交事务或回滚事务。在SQL Server中,事务的开始可以隐式发生,也可以显式通过BEGIN TRANSACTION语句开始。
为了平衡隔离性和并发性,SQL Server提供了四个事务隔离级别:读未提交(READ UNCOMMITTED)、读已提交(READ COMMITTED)、可重复读(REPEATABLE READ)和可串行化(SERIALIZABLE)。每个级别对应不同级别的锁机制和对其他事务的影响。
-- 设置事务隔离级别为读已提交
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
隔离级别的选择依赖于应用对数据一致性和性能的要求。较高的隔离级别能够保证更好的数据一致性,但可能会降低并发性能。
3.2 ACID属性的保证
3.2.1 原子性、一致性、隔离性和持久性深入解析
原子性是通过事务日志来实现的。事务日志记录了事务中的每个操作,一旦事务执行失败需要回滚,SQL Server会利用事务日志将数据库状态恢复到事务执行前的状态。
一致性是通过事务中的数据完整性约束、触发器和规则来维护的。任何违反约束的操作都将导致事务失败。
隔离性则涉及到锁机制。SQL Server使用不同类型的锁(如共享锁、排他锁)来防止并发事务之间的冲突,同时提供了不同级别的隔离来平衡性能和隔离性需求。
持久性通过将事务日志写入到非易失性存储来实现。即使发生故障,事务日志也确保了事务的改变能够被恢复。
3.2.2 错误处理和事务日志的管理
在事务执行中可能会遇到错误,SQL Server提供了事务回滚和保存点机制来处理这些错误。事务可以通过ROLLBACK语句或设置保存点来回滚到某个特定点。
事务日志管理是保证数据库恢复的关键。定期备份事务日志并进行日志文件的维护是重要的管理任务。日志文件满了之后,事务将不能继续执行,这将导致数据库操作的阻塞。
-- 创建一个保存点
SAVE TRANSACTION SavePointName;
-- 如果出现错误,回滚到保存点
ROLLBACK TRANSACTION SavePointName;
日志管理和维护涉及到一系列的SQL Server配置和管理任务,包括设置日志文件大小、增长率、备份策略等,确保系统稳定运行和快速恢复。
4. 查询优化器工作原理及实践
4.1 查询优化器的核心功能
4.1.1 查询处理流程
SQL Server查询优化器是一个复杂的组件,负责将用户的查询请求转换为高效的执行计划。查询处理流程可以分为以下几个步骤:
-
解析阶段 :查询优化器首先分析SQL语句的语法,创建一个查询树(query tree)或查询图(query graph),这是一个内部表示,用于表达SQL语句的结构。
-
绑定阶段 :优化器将查询树中的各个元素与数据库中的实际对象(如表、视图、存储过程)进行绑定。
-
标准化阶段 :为了简化优化过程,查询树可能会被转换成标准化形式。标准化的目的是确保查询优化器可以识别各种等价查询,并选择出最优的查询计划。
-
优化阶段 :查询优化器的核心阶段。优化器尝试生成多种可能的查询计划,通过成本估算模型,选择成本最低的计划。这个过程涉及索引选择、连接算法、并行策略等众多因素。
-
执行阶段 :生成的查询执行计划被传送到执行引擎,执行引擎将计划中的操作转换为操作数据库的实际命令。
4.1.2 查询计划的生成和评估
查询计划的生成基于一系列复杂的算法和启发式规则。优化器生成查询计划时通常考虑以下因素:
-
成本模型 :SQL Server使用成本估算模型来预测执行计划中各个操作的成本。这些成本考虑了I/O操作、CPU周期和内存使用等资源消耗。
-
索引覆盖 :当一个查询可以仅使用索引中的数据来满足时,称为索引覆盖查询。这种查询可以显著减少数据页的读取量,从而提高查询性能。
-
统计信息 :统计信息提供了关于表和索引列分布的重要数据,帮助优化器评估不同查询计划的成本,从而选择最佳计划。
查询优化器还使用了多种策略来评估查询计划,包括启发式策略和动态规划策略。查询优化器需要在计算时间和计划质量之间找到一个平衡点。
4.2 查询优化技巧
4.2.1 索引选择对查询性能的影响
索引是影响查询性能的关键因素之一。正确选择和创建索引可以显著提高查询的响应速度。以下是索引选择的一些最佳实践:
-
避免过多索引 :创建过多索引会增加数据更新操作的负担,因为每个索引都需要维护。索引优化的目标是找到最佳的索引组合,以最小化存储和更新成本,同时最大化查询性能。
-
覆盖索引 :如果一个查询可以通过索引来获取所有需要的数据,那么这个索引被称为“覆盖索引”。覆盖索引可以减少对数据页的读取次数,从而提高查询性能。
-
索引碎片整理和重建 :随着时间的推移,数据的插入、删除和修改操作会导致索引碎片的产生,这会降低查询性能。定期进行索引碎片整理或重建可以帮助保持索引性能。
4.2.2 统计信息在查询优化中的作用
统计信息对查询优化至关重要,因为它们提供了有关数据分布的准确信息。这些信息被查询优化器用来估计查询计划中的操作成本,并选择最优的执行路径。以下是统计信息相关的一些重要概念:
-
统计信息的创建和更新 :当表中的数据发生变化时,统计信息可能变得过时。SQL Server提供了一些命令来手动创建或更新统计信息。
-
统计信息的维护 :定期检查和维护统计信息是数据库管理员的重要任务。数据库维护计划可以自动化统计信息的维护过程。
-
查询优化器如何使用统计信息 :优化器使用统计信息来估算条件表达式返回的行数,选择最佳的连接顺序,以及确定是否使用索引等。
通过理解查询优化器的工作原理和实践技巧,数据库管理员和开发人员可以更好地管理数据库性能,确保查询以最高效率执行。接下来的章节,我们将探讨如何使用锁定机制和并发控制策略来进一步提高SQL Server的性能。
5. 锁定机制和并发控制策略
在数据库系统中,为了保持数据的一致性和完整性,锁定机制是不可或缺的。当多个用户或事务尝试同时访问和修改同一数据时,锁定机制可以防止数据访问冲突。本章将深入探讨SQL Server中的锁定机制,以及并发控制策略,帮助开发者和DBA(数据库管理员)优化性能和确保事务的顺利进行。
5.1 锁的类型与应用场景
5.1.1 共享锁与排他锁的理解
在SQL Server中,锁的类型主要分为共享锁(Shared Locks)和排他锁(Exclusive Locks)。共享锁允许并发读取,而排他锁则是事务独占资源,防止其他事务读取或修改。
-- 申请共享锁的示例代码
SELECT * FROM mytable WITH (SHARED_LOCK);
在上面的代码中, WITH (SHARED_LOCK) 指示数据库引擎对查询结果应用共享锁。如果其他事务已经获取了相应的资源锁,当前事务会等待直到资源可用。
-- 申请排他锁的示例代码
SELECT * FROM mytable WITH (TABLOCKX);
使用 WITH (TABLOCKX) 将会对该表施加一个排他锁,其他任何事务都不可以获取该表上的锁,直到当前事务完成。
5.1.2 死锁的预防和解决
死锁发生在两个或多个事务互相等待对方释放资源的情况下。当这种情况发生时,SQL Server会选择一个事务终止,以释放资源。
为了预防死锁,数据库管理员和开发者需要设计良好的事务逻辑:
- 保证事务尽可能短且高效。
- 减少事务之间的依赖关系,合理安排操作顺序。
- 尽可能使用较低的隔离级别。
在监测到死锁的情况下,DBA可以通过SQL Server提供的工具,比如 sp_lock 和 sys.dm_tran_locks ,分析死锁的详细信息,并据此修改事务逻辑。
5.2 并发控制的高级技术
5.2.1 隔离级别与并发性能的权衡
SQL Server提供了四种事务隔离级别:
- 读未提交(Read Uncommitted)
- 读已提交(Read Committed)
- 可重复读(Repeatable Read)
- 可串行化(Serializable)
隔离级别越高,一致性越强,但并发性能就越低。开发者和DBA需要根据应用需求进行权衡。
5.2.2 锁升级和阻塞管理
锁升级是指当一个事务中的锁的数量超过了配置阈值时,SQL Server自动将行锁升级为更高级别的表锁。过多的锁升级可能会降低并发性能,因此DBA需要通过监控和适当的配置来管理锁升级。
阻塞管理是关于如何识别和解决阻塞问题。通常使用动态管理视图 sys.dm_exec_requests 来检查阻塞的事务,并结合 KILL 命令解决阻塞。
总结而言,理解并管理好SQL Server的锁定机制和并发控制对于确保数据库系统能够高效运行至关重要。在实践中,这通常要求深入理解SQL Server的工作原理,并结合性能监控工具进行细致的调优。
6. 备份与恢复策略的多种选择
数据库备份与恢复是数据管理中的关键任务,确保数据安全和业务连续性。在本章中,我们将深入探讨SQL Server 2005提供的不同备份和恢复策略,并分析在不同业务场景下的选择与应用。
6.1 数据备份的方法与策略
在面对数据丢失风险时,合理的备份策略至关重要。SQL Server 2005提供了多种备份方法,包括全备份、差异备份以及日志备份。每种备份类型都有其特定的使用场景和优势。
6.1.1 全备份、差异备份与日志备份
全备份 涉及到备份数据库的所有数据和事务日志,是最全面的备份形式,适合在数据库完全重置或者灾难恢复时使用。它能够确保数据的一致性并减少数据恢复的时间,但由于需要复制整个数据库,全备份可能对性能产生较大影响,并且需要更多的存储空间。
差异备份 则只备份自上次全备份后发生更改的数据。它大大减少了备份数据量,并且缩短备份时间,是一种在全备份之间进行快速备份的有效方法。差异备份保留了数据的最新状态,适合于日常备份,易于恢复,但其无法单独进行恢复,需要配合全备份使用。
日志备份 记录了数据库的所有事务日志活动。事务日志备份是一种增量备份方法,它允许数据库管理员恢复数据库到最近的日志备份时间点,这为精确的数据恢复提供了可能。它适用于频繁更新和数据一致性要求高的场景。如果数据库频繁发生更改,日志备份也可能消耗较多的存储资源。
6.1.2 备份验证和恢复测试
对备份的验证是数据保护中不可或缺的环节。SQL Server 2005 提供了验证备份完整性的机制。管理员应该定期验证备份的有效性,确保在需要时可以成功恢复数据。这通常通过执行恢复操作并将数据库还原到另一个实例来完成。这样的测试可以发现问题并确保数据的可靠性。
此外,进行恢复测试可以帮助管理员确定最佳的备份策略。例如,通过模拟各种故障场景,可以评估从不同备份类型恢复数据所需的时间。这些测试还可以揭示在灾难恢复计划中可能忽视的步骤,从而增强整体的数据保护策略。
6.2 恢复模型与数据恢复
选择正确的恢复模型是优化备份和恢复过程的关键。SQL Server 2005 提供了简单恢复模型和完整恢复模型两种主要的恢复模型,每种模型都有其特点和适用场景。
6.2.1 简单恢复模型与完整恢复模型
简单恢复模型 通常用于小型数据库或对数据恢复要求不高的情况。在这种模式下,SQL Server 会自动处理事务日志的截断,因此管理员不需要进行日志备份。数据恢复通常局限于最近的全备份,这意味着数据丢失可能是不可逆的,且丢失的数据可能包括自上次全备份以来的最新更改。
完整恢复模型 则提供了最大的数据保护级别。在这种模式下,事务日志不会自动截断,管理员必须定期进行日志备份。数据恢复可以非常精确,甚至可以恢复到数据丢失前的那一刻。然而,这种模式需要更严格的管理,包括定期执行日志备份和空间管理。
6.2.2 恢复过程中的关键点与注意事项
在执行数据恢复时,有几个关键点需要考虑。首先,了解数据丢失的范围和原因至关重要,这将决定是进行全备份恢复、差异备份恢复还是日志备份恢复。例如,如果数据丢失是由于存储故障导致的,那么可能需要从全备份开始恢复。
其次,需要确保在恢复过程中数据库的完整性。SQL Server 提供了一系列的工具和日志来检查数据页的一致性,确保在恢复过程结束后数据库能够正常启动和运行。
最后,对于生产环境的数据库,建议在非高峰时段进行恢复操作,以减少对业务的影响。此外,应该制定明确的灾难恢复计划,并定期进行演练,以确保在真正发生数据丢失时能够迅速有效地执行恢复策略。
总结与思考
在本章中,我们讨论了SQL Server 2005的不同备份和恢复策略,并展示了它们在不同业务场景下的应用。通过合理选择备份类型、验证备份的有效性以及制定有效的灾难恢复计划,可以极大地减少数据丢失的风险并提高系统的整体可靠性。作为一名数据库管理员,理解并掌握这些备份和恢复的策略,是确保业务连续性的基石。
7. 高效管理内存与文件配置
数据库管理系统需要对内存和磁盘文件进行有效管理,以确保数据的快速访问和高效运行。SQL Server 2005通过优化内存管理以及提供灵活的文件配置选项,使得数据库性能和可靠性达到最优。
7.1 内存资源的管理
7.1.1 缓冲池的作用和优化
缓冲池是SQL Server用来缓存数据页和索引页的主要内存区域。通过对缓冲池的有效管理,SQL Server可以减少磁盘I/O操作,显著提高数据库的性能。
- 缓冲池作用 :
- 数据缓存:存储频繁访问的数据页,减少物理读取次数。
- 键值缓存:缓存索引节点,加快查询速度。
-
批量读写:优化顺序I/O操作,提供快速数据加载和备份。
-
优化策略 :
- 配置足够大的缓冲池 :通过
sp_configure存储过程调整max server memory参数,为SQL Server分配足够的内存。 - 监控和调整 :使用DMVs(动态管理视图)监控缓冲池命中率,如
sys.dm_os_buffer_descriptors,并在必要时进行调整。 - 工作负载分析 :根据工作负载特性优化缓冲池大小,例如对于读密集型负载,可适当增加缓冲池大小。
7.1.2 内存管理对性能的影响
- 内存分配策略 :SQL Server使用多种内存管理技术,包括预分配和按需分配内存。合理配置内存能够减少内存碎片,提高内存使用效率。
- 内存压力和资源瓶颈 :内存资源不足会导致系统频繁进行磁盘交换,降低系统性能。通过监控工具如
sys.dm_os_memory_clerks和sys.dm_os_memory_objects,可以识别内存压力问题。 - 操作系统级别优化 :为了提升SQL Server性能,应确保操作系统级的内存配置得当,例如调整操作系统的虚拟内存设置。
7.2 文件组与文件的高级配置
7.2.1 文件组的使用场景和好处
SQL Server允许数据库被划分为多个文件组,这为数据管理提供了灵活性。
- 文件组好处 :
- 数据组织 :文件组可以根据数据访问模式和事务日志分离,优化性能。
- 备份和恢复 :可以对文件组进行独立备份和恢复操作,实现更细致的数据保护策略。
-
并发控制 :不同的文件组可以在不同的事务中并发访问,从而提高并发性。
-
使用场景 :
- 数据分区 :对于大型表,可以使用分区表和分区视图来管理数据,每个分区可以放在不同的文件组上。
- 数据库增长控制 :通过增加新文件到特定文件组中,可以灵活控制数据库的增长。
7.2.2 文件配置对性能的潜在影响
- 文件大小和增长设置 :正确配置数据文件和日志文件的初始大小及自动增长设置,可以防止在高负载下出现性能下降的问题。
- 文件放置策略 :文件应放置在不同的磁盘上,以平衡I/O负载,提高整体吞吐量。
- 读写分离 :将数据文件和日志文件放在不同的磁盘上,可以减少I/O争用,提升性能。
通过精确的内存和文件配置,数据库管理员可以极大地提高SQL Server 2005的性能和稳定性。本章节详细介绍了内存和文件配置的重要性,以及如何进行有效的管理和优化,从而保证数据库系统在处理大量数据和高并发请求时,仍能够保持最佳性能。
简介:《Microsoft.Press Inside Microsoft SQL Server 2005 Storage Engine》详细探讨了SQL Server 2005存储引擎的内部机制,覆盖了数据页、事务管理、查询优化、并发控制、备份与恢复等关键概念。本书为数据库管理员和开发人员提供深入理解存储引擎的工作原理、性能优化和数据管理的实践指导。书中还介绍了分区、内存管理、文件组织、临时存储结构以及性能监控与调优等方面的技术要点。















 1506
1506

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









