







简介:《无废话XML》是一本系统介绍XML的书籍,它从基础概念出发,详细阐述了XML的结构、语法规则和解析技术。本书深入讨论了DOM和SAX两种XML解析器的原理和应用场景,以及如何利用XSLT和XPath进行数据样式转换和信息检索。此外,它还涉及了XML在Web服务中的应用,包括SOAP消息、RESTful API的数据交换,以及XML Schema定义。书中提供了对XML文件处理的编程语言库的介绍,目的是让读者能够高效地理解和运用XML这一核心标记语言。 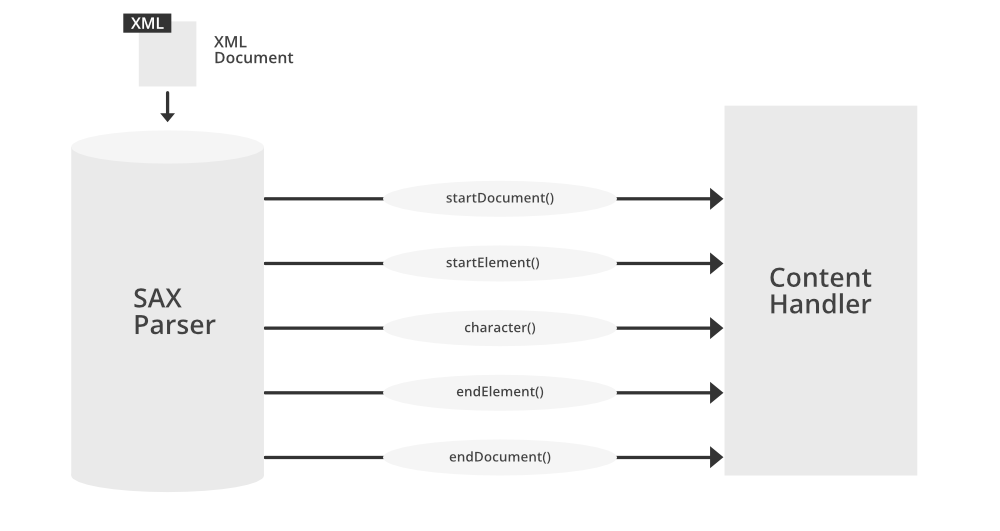
1. XML基础结构与核心概念
1.1 XML的定义和用途
XML(Extensible Markup Language)是一种可扩展标记语言,它允许开发者创建自己的标签,定义数据元素。XML被广泛用于Web服务中的数据交换、配置文件管理、文档描述等多种场景。与HTML相比,XML不固定标签的定义,允许在数据表示上具有更强的适应性和灵活性,其主要目的是在不同系统之间传递数据,确保数据的独立性和兼容性。
1.2 XML文档的组成
一个XML文档主要由三个部分组成:序言(Prolog)、元素(Elements)和处理指令(Processing Instructions)。序言包含了XML声明,用来说明文档是XML格式,以及字符编码等信息。元素则是XML文档的骨架,由开始标签、内容和结束标签组成。处理指令用来向处理XML的应用程序提供指令。XML通过这种方式结构化地组织信息,支持文档的自描述性。
1.3 XML与数据交换
在数据交换中,XML扮演了一个非常重要的角色。它可以将数据以结构化的方式从一方传输到另一方,而不关心数据的具体表现形式。由于XML文档具有自我描述性,任何一方都能解析这些文档,即使他们对数据的具体内容一无所知。XML的数据交换功能使得跨平台、跨语言的应用程序能够轻松地共享和传递数据,是许多Web服务和APIs选择XML作为消息格式的原因。
2. XML语法和文档规则
2.1 XML文档的基本结构
2.1.1 XML声明和根元素
一个XML文档的开始通常是由XML声明开始的。XML声明用来指明文档的类型是XML,它可以包含版本信息、字符编码以及独立性声明。声明形式如下:
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
这里的 version 指定了XML文档所使用的XML规范的版本; encoding 指定了文档所使用的字符编码; standalone 属性指示文档是否是独立的,即是否依赖于外部实体,其值为"yes"或"no"。
紧随XML声明之后的是根元素,也就是XML文档中的最外层元素。它包含了文档中所有的内容,并且必须正确关闭,这标志着整个文档的结束。
<rootElement>
<!-- Content goes here -->
</rootElement>
2.1.2 元素和标签的规则
XML元素是由起始标签、内容和结束标签组成的,标签名称区分大小写,并且必须成对出现。例如:
<elementName>Content of the element</elementName>
一些特殊的字符如 < 、 > 、 & 和引号等,在XML中用作标签或属性值的一部分时,必须使用字符实体进行转义,如 < 用 < 表示, > 用 > 表示等。
一个XML文档可以包含任何数量的元素,但根元素必须只有一个,并且其他所有元素都必须位于根元素内部。元素可以包含其他元素、文本内容、属性或者混合内容。
2.2 XML命名空间的应用
2.2.1 命名空间的定义和作用
XML命名空间是一个可以用来区分同一XML文档中不同元素和属性名称的机制。它通过在元素名称前添加前缀来工作,前缀与命名空间URI关联,URI作为命名空间的唯一标识。
命名空间可以定义如下:
<element xmlns:prefix="namespaceURI">
<!-- Content -->
</element>
其中, xmlns:prefix 是声明命名空间的属性, prefix 是命名空间的前缀, namespaceURI 是一个URI,用来唯一标识命名空间。
2.2.2 命名空间在文档中的使用实例
命名空间在复杂文档中十分有用,它可以帮助文档的读者区分来自不同源的元素。例如,下面的文档使用了两个不同的命名空间:
<catalog xmlns:books="***"
xmlns:cds="***">
<books:book>
<books:title>1984</books:title>
<books:author>George Orwell</books:author>
</books:book>
<cds:compact-disc>
<cds:title>The Dark Side of the Moon</cds:title>
<cds:artist>Pink Floyd</cds:artist>
</cds:compact-disc>
</catalog>
在这个实例中, books 前缀关联了书籍信息的命名空间,而 cds 前缀关联了CD信息的命名空间。
2.3 XML属性的定义和限制
2.3.1 属性的作用和命名规则
XML元素可以包含属性,属性提供了关于元素的附加信息。在XML文档中,属性对于定义元素的某些特性非常有用,但应谨慎使用,以避免过度依赖属性。
属性命名应遵循XML命名规则,即它们必须以字母、下划线或冒号开头,并且可以包含字母、数字、下划线、连字符、点和冒号。虽然冒号可以出现在属性名中,但是由于冒号在XML命名空间中具有特殊含义,所以在属性命名中应避免使用冒号。
<element attribute="value">
<!-- Content -->
</element>
在上述代码片段中, attribute 是属性的名称, value 是属性的值。
2.3.2 CDATA段的使用和解析
CDATA段是一个特殊的区域,它告诉解析器不应当将该区域内的内容视为XML标记。CDATA段由 <![CDATA[ 开始,以 ]]> 结束。
使用CDATA段的常见情景是包含需要转义的特殊字符,或者代码块,如下所示:
<code>
<![CDATA[
int main() {
printf("Hello, World!\n");
return 0;
}
]]>
</code>
在这个例子中, CDATA 标记之间的文本是原样处理的,不会解析为XML标记。注意,CDATA段中不能包含 ]]> ,因为这是CDATA的结束标记。
3. XML解析器类型与使用场景
3.1 解析器的工作原理
3.1.1 解析器的任务和类型
XML解析器的主要任务是读取XML文档,并将其转换为程序可以操作的数据结构。解析器可以看作是XML文档和应用程序之间的中介,负责处理XML文档的结构、语法以及文档中的内容。解析器可以分为两大类:基于树的解析器(Tree-based Parsers)和基于事件的解析器(Event-based Parsers)。
基于树的解析器(如DOM解析器)会构建整个文档的树形结构,这样用户可以方便地导航并访问树中的各个节点。相反,基于事件的解析器(如SAX解析器)读取XML文档,并在遇到特定的XML元素时触发事件,这样应用程序就可以响应这些事件,并执行相应的代码。
解析器可以进一步细分为:
- DOM解析器:构建文档的树形结构,通过DOM API访问节点。
- SAX解析器:事件驱动模型,处理XML文档流时触发事件。
- StAX解析器:流式API,允许应用程序读取或写入XML数据流。
- Pull解析器:类似于StAX,但通常用于小型或特定语言。
3.1.2 常见的XML解析器介绍
在本节中,我们将介绍一些广泛使用的XML解析器:
Java中DOM和SAX的实现
-
javax.xml.parsers包中的DocumentBuilder是一个DOM解析器的示例,它遵循DOM Level 2规范。 -
org.xml.sax包中的XMLReader是SAX解析器的接口,需要一个实现了此接口的类如org.apache.xerces.parsers.SAXParser。
.NET中的XML解析器
-
System.Xml.XmlDocument在.NET中提供DOM解析功能。 -
System.Xml.XmlReader和System.Xml.XmlWriter提供基于事件的读写功能。
Python中的XML解析器
-
xml.dom.minidom是一个轻量级的DOM实现。 -
xml.etree.ElementTree提供了一个灵活且高效的接口,它既不是严格的DOM也不是SAX。 -
xml.sax提供了对SAX的支持。
3.2 不同解析器的对比分析
3.2.1 DOM解析器的特点与适用场景
DOM解析器将整个XML文档读入内存并构建为树形结构,允许用户通过API随机访问节点。DOM解析器的特点包括:
- 操作性: 用户可以创建、修改或删除节点。
- 随机访问: 无需线性遍历,可以直接访问任何节点。
- 内存消耗: 由于构建整个树,可能会消耗较多内存资源。
适用于解析较小的XML文档,或者需要频繁查询和更新节点信息的场景。
3.2.2 SAX解析器的特点与适用场景
SAX解析器通过事件处理机制逐个处理XML文档中的元素,它不构建整个树形结构。SAX解析器的特点包括:
- 低内存消耗: 逐个读取元素,不构建树,适合大文件。
- 速度: 由于是流式处理,SAX比DOM解析器快。
- 一次性处理: 无法多次遍历文档,只能向前遍历。
适用于解析大型文件或只需一次遍历的场景,其中不需对整个文档结构进行复杂的随机访问。
3.2.3 DOM和SAX的对比表格
| 特性 | DOM解析器 | SAX解析器 | |----------------|-----------------|-----------------| | 数据结构 | 树形结构 | 流式处理 | | 随机访问 | 支持 | 不支持 | | 内存消耗 | 较高 | 较低 | | 速度 | 较慢 | 较快 | | 解析模式 | 随机访问模式 | 一次性遍历模式 | | 适用性 | 小型文档 | 大型文档 |
3.2.4 代码示例与分析:使用Python的xml.dom.minidom和xml.sax
DOM解析示例
from xml.dom import minidom
# 加载XML文件
doc = minidom.parse('example.xml')
# 获取根元素
root = doc.documentElement
# 获取所有名为'item'的子元素
items = root.getElementsByTagName('item')
for item in items:
# 获取子节点并打印其文本内容
print(item.firstChild.data)
# 关闭文档
doc.unlink()
以上代码通过Python的 minidom 模块进行解析,首先加载了一个XML文件,并获取了根元素。接着,它获取了所有名为 item 的子元素,并遍历打印了它们的文本内容。最后,关闭文档释放资源。
SAX解析示例
import xml.sax
class MyHandler(xml.sax.ContentHandler):
def startElement(self, tag, attrs):
if tag == 'item':
print("Found an item")
xml.sax.parse('example.xml', MyHandler())
在这个例子中,我们定义了一个 ContentHandler 类,它在遇到元素标签时会触发 startElement 事件。这里我们只处理了名为 item 的元素,当解析器遇到 item 标签时,它会打印出一条消息。
通过这个简单的例子可以看出,SAX解析器通过事件驱动模型进行工作,当遇到感兴趣的元素时,我们可以在对应的事件处理器中执行我们想要的操作。由于SAX的这种一次性遍历特性,它特别适用于处理大型文档,我们不需要保持整个文档的结构在内存中,从而节省内存资源。
4. DOM和SAX解析技术
4.1 DOM解析技术详解
4.1.1 DOM解析机制及其实现
文档对象模型(DOM,Document Object Model)是一种以树形结构表示XML或HTML文档的编程接口。DOM解析器将整个XML文档读入内存,并构建成一个树状结构,其中每一个元素、属性和文本节点都成为树的一个节点。这种方式允许开发者利用DOM提供的API来导航、添加、修改、删除或者重新排列树中的节点。
DOM解析机制的实现基于W3C的DOM推荐标准。在Python中,我们可以使用第三方库如 xml.dom.minidom 来进行DOM解析。下面是一个简单的例子:
from xml.dom import minidom
# 解析XML文档
dom_tree = minidom.parse("example.xml")
# 获取根节点
root = dom_tree.documentElement
# 获取所有的<p>元素
paragraphs = root.getElementsByTagName("p")
for paragraph in paragraphs:
# 输出<p>元素中的文本内容
print(paragraph.firstChild.data)
4.1.2 DOM在文档操作中的应用
一旦XML文档被加载为DOM树,我们便可以使用DOM提供的接口进行各种操作。这包括但不限于修改节点、增加新节点、删除节点以及将整个DOM树转换回字符串。
例如,修改上述XML文档中每个 <p> 元素的内容可以通过遍历这些元素并使用DOM的节点操作API来完成:
for paragraph in paragraphs:
paragraph.firstChild.data = "New text"
print(paragraph.toxml())
4.2 SAX解析技术详解
4.2.1 SAX解析机制及其实现
简单的API用于XML(SAX,Simple API for XML)是一种事件驱动的XML解析方式。与DOM不同,SAX不需要将整个文档加载到内存中。它逐个读取XML文件的元素,并触发一系列事件(如开始标签、文本内容、结束标签等)。开发者需要提供事件处理函数来响应这些事件。
Python中的 xml.sax 模块实现了SAX解析。下面是一个简单的例子:
from xml.sax.handler import ContentHandler
from xml.sax import make_parser
class MyHandler(ContentHandler):
def startElement(self, tag, attrs):
print(f"Start tag: {tag}")
def endElement(self, tag):
print(f"End tag: {tag}")
def characters(self, data):
print(f"Text: {data}")
parser = make_parser()
parser.setContentHandler(MyHandler())
parser.parse("example.xml")
4.2.2 SAX在事件驱动处理中的优势
SAX最大的优势在于它的内存效率,尤其适合处理大型XML文件。由于不需要一次性加载整个文档,SAX只需要足够的内存来维护正在处理的部分,这对于DOM解析来说是不可行的。
事件驱动的处理模式使得SAX非常适合于只需要部分处理XML文档的情况。例如,如果我们只关心XML中的特定元素,可以在相应事件处理函数中进行检查和处理,然后忽略其他所有内容。
4.3 DOM与SAX的选择与应用
4.3.1 如何选择合适的解析技术
选择DOM还是SAX解析技术取决于具体的应用需求。DOM适合于需要频繁随机访问文档元素的场景,尤其当XML文档不是特别大时。另一方面,SAX适合于处理大型文件或只需要顺序访问特定元素的场景。由于其较低的内存占用,SAX在处理非常大的XML文件时更为高效。
4.3.2 实际案例分析:DOM与SAX的应用比较
例如,假设我们有一个包含上千个订单项的大型XML文件,我们只需要计算订单总价值。在DOM中,我们需要构建整个树,然后遍历树中的每个订单节点来获取数值并进行计算。这不仅消耗内存,而且需要较长时间来构建DOM树。
使用SAX,我们可以定义一个事件处理器来累加订单金额,如下所示:
class OrderHandler(ContentHandler):
def __init__(self):
self.total = 0
def startElement(self, tag, attrs):
if tag == 'order':
self.price = 0
def characters(self, data):
if self.price:
self.price += int(data)
def endElement(self, tag):
if tag == 'order':
self.total += self.price
# 然后,我们可以使用SAX解析器来处理文件。
在这个例子中,我们只关注与订单金额相关的数据,并忽略文档中的其他内容,从而显著提高处理速度和降低内存消耗。
根据上述分析,我们可以看出,在处理大型文件且只需要顺序访问的情况下,SAX是更优的选择。而当需要进行频繁的随机访问或者处理的XML文档不是特别大时,DOM提供了更直观、方便的方式来操作XML数据。
5. XML在Web服务中的数据交换作用
5.1 XML作为数据交换格式的重要性
XML自诞生以来,就因其自描述性、可扩展性和跨平台性,成为在Web服务中交换数据的首选格式。它允许开发者以一种结构化的方式描述数据,这种描述方式不依赖于特定的应用程序或硬件平台。
5.1.1 数据交换的需求和XML的优势
在进行Web服务交互时,尤其是在分布式系统之间,数据交换的标准化和语言无关性显得尤为重要。XML提供了一种统一的数据格式,使得不同的系统之间可以方便地交换信息。同时,XML还支持复杂的数据结构,如嵌套元素和属性,这在交换复杂数据时显得尤为重要。
5.1.2 XML在Web服务中的角色
在Web服务中,XML扮演着信息载体的角色。服务请求和响应常常用XML格式来表示,这使得服务端和客户端可以基于XML文档的结构进行解析和处理。例如,SOAP(Simple Object Access Protocol)协议中,数据就以XML格式封装。这不仅帮助确保了数据的完整性和正确性,也使得数据处理变得标准化。
5.2 XSLT和XPath的应用
XSLT和XPath是处理XML文档的两个重要技术。它们帮助开发者转换和查询XML文档,为XML数据的处理和展示提供了强大的支持。
5.2.1 XSLT的转换过程和功能
XSLT(Extensible Stylesheet Language Transformations)是一种用于将XML文档转换成其他文档的语言。在Web服务中,XSLT可以将数据从一种格式转换成另一种格式,例如,从XML转换成HTML或者JSON。这种转换对于将数据适应不同的客户端展示需求至关重要。
5.2.2 XPath的查询功能和在XSLT中的运用
XPath是一种在XML文档中查找信息的语言。XPath表达式可以定位XML文档中的特定节点或者节点集合,使得数据提取变得快速方便。在XSLT中,XPath通常用于选择需要被转换的XML元素。例如,如果你想转换所有的 <product> 节点,你可以使用XPath表达式 /catalog/product 来选择这些节点。
5.3 XML Schema(XSD)的应用与重要性
XML Schema(XSD)提供了定义XML文档结构和内容的语法,它帮助确保了数据交换时的准确性和一致性。
5.3.1 XSD的定义和作用
XSD定义了一套规则来约束XML文档的结构和内容。通过XSD,可以声明元素和属性的数据类型,以及它们之间的关系,这样可以确保交换的XML数据是格式正确且具有意义的。比如,XSD可以指定一个XML文档中必须包含哪些元素,以及这些元素的数据类型和允许的值。
5.3.2 XSD在保证数据一致性和有效性的应用实例
假设我们有一个电子商务系统,需要处理来自不同供应商的产品数据。每个供应商的XML数据格式可能略有不同,为了确保这些数据能够被系统正确处理,我们可以定义一个XSD来规定产品数据的标准格式。在这个XSD中,我们可能定义 <product> 元素必须包含 <name> , <price> 和 <quantity> 子元素,并为它们指定合适的数据类型。这样,当系统接收到供应商发送的数据时,它就可以使用XSD来验证这些数据,确保它们符合预定义的结构和格式。
通过XSD的应用,我们不仅简化了数据的交换和处理流程,也提高了系统的健壮性和可维护性。
简介:《无废话XML》是一本系统介绍XML的书籍,它从基础概念出发,详细阐述了XML的结构、语法规则和解析技术。本书深入讨论了DOM和SAX两种XML解析器的原理和应用场景,以及如何利用XSLT和XPath进行数据样式转换和信息检索。此外,它还涉及了XML在Web服务中的应用,包括SOAP消息、RESTful API的数据交换,以及XML Schema定义。书中提供了对XML文件处理的编程语言库的介绍,目的是让读者能够高效地理解和运用XML这一核心标记语言。















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









