







事故现场
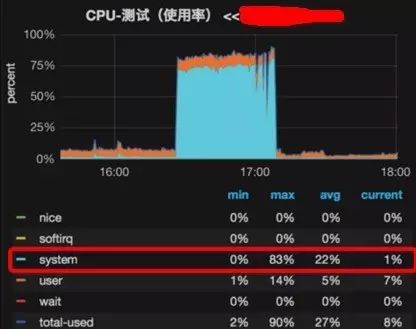
16:27分钟时刻,系统CPU突然标高,大部分都是system,同时processlist暴增,running最高到1500,应用反映超时。
系统其他资源正常,io、网络、内存,都在正常使用范围。网络和io掉了一些,剖析不是他们的问题。
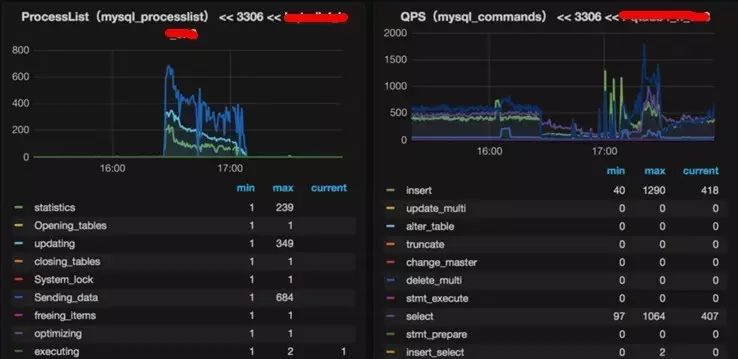
线上有大量的这个sql:
select
count(*)
from db.tablewherecreate_time>=‘2017-07-01 00:00:00’and create_time
表结构很简单,索引使用正常,表只有1w多行,查询的效果集也只有几千行。

这种情形,最先怀疑是并发突增,看了qps并没有增高,营业也没有换取,这个sql的qps也只有40,平时执行0.0xs。故障时代qps并没有突增,因此连接数增高、并发的增高解释为响应变慢。
而且cpu大量的sys这不正常,排查如下:
排查了硬件故障,确立链接会消耗syscpu,但应该是瞬间,不应该cpu是延续的
排查了应用对端,若是tcp协议数据发的很慢,网络堆在mysql发送也会导致sys,同时导致增大链接,排查了没问题。
数据库没有报错
没有其他显著慢sql
查询了以往并发突增导致的故障,并没有syscpu高
线上暂且把这个营业下线,解决了故障。但没有找到根本原因。
环境复现:
之后和开发在离线库抱着试一试的心态复现环境,开启30个线程去查询,也用了sysbench去压测这个sql,复现了问题。(之所以没有选线上从库,看之前的监控,写节点性能低,pxc从库qps也受到了影响)
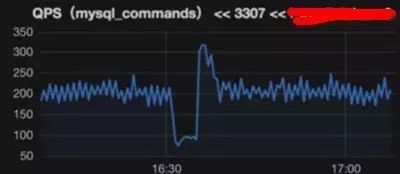
异常现象和线上险些一致,sys高,running高,qps低。
然后重点最先剖析cpu。异常时系统级别cpu上下文切换偏高,是正常的10倍:
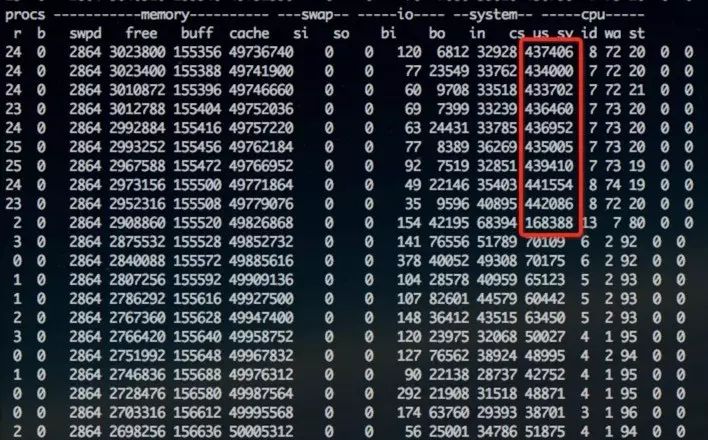
这里抓到cpu大量用在kernel的spin自旋锁:
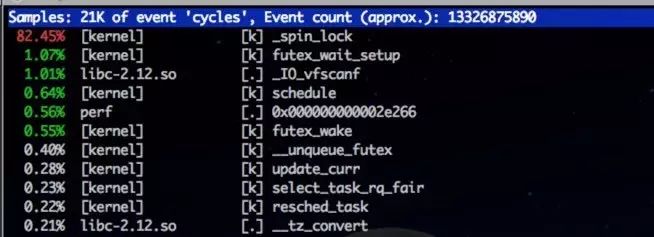
pstack:看到大量的线程在挪用 Time_zone_system 方式
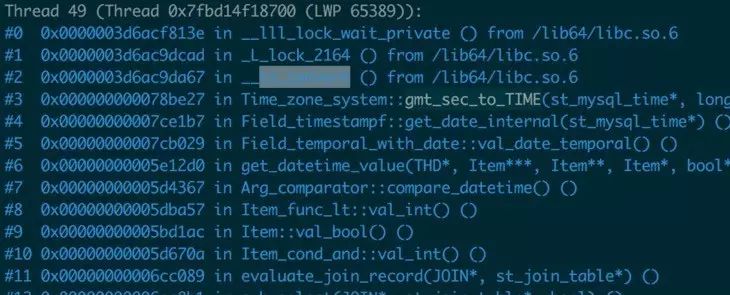
这些线索,大量时间花在cpu的spin,遐想到了之前剖析时看到的文章,http://webcache.googleusercontent.com/search?q=cache:p_AeVu4QhL8J:glume.blog.chinaunix.net/uid-20708886-id-5105437.html+&cd=1&hl=zh-CN&ct=clnk&gl=hk
对于使用 timestamp 的场景,MySQL 在接见 timestamp 字段时会做时区转换,当 time_zone 设置为 system 时,MySQL 接见每一行的 timestamp 字段时,都市通过 libc 的时区函数,获取 Linux 设置的时区,在这个函数中会持有mutex,当大量并发SQL需要接见 timestamp 字段时,会泛起 mutex 竞争。MySQL 接见每一行都市做这个时区转换,转换完后释放mutex,所有守候这个 mutex 的线程所有叫醒,效果又会只有一个线程会乐成持有 mutex,其余又会再次sleep,这样就会导致 context switch 异常高但 qps 很低,系统吞吐量急剧下降。
总结下文章,就是当time_zone=system的时刻,查询timestamp字段,会挪用系统的时区做时区转换,有全局锁__libc_lock_lock的珍爱,导致线程并发环境下,系统性能受限。
若是将time_zone=’+8:00’则不会挪用系统时区,则不会触发系统时区转换,使用mysql自身转换,大大提高了性能。
结论
将time_zone改为’+8:00’后,再次压测性能正常,验证了上面的剖析。
MySQL 中的 mutex 在获取不乐成后,短暂spin,若是还不乐成,会发生context switch。这个故障就是在读取系统时区转换函数时,持有了mutex,mutex独占的,大量的接见会泛起资源竞争,读完才会释放mutex,导致其他并发线程的spin以及cs,从而导致高running和响应慢,cpu飙升,又加剧了其他sql的响应。
后话
qunar线上time_zone都设置的system,而且这个sql也上线有一段时间了,怎么突然泛起问题。
凭证开发所说,之前该表5k行,7月初最先量逐步加大。我也测试了若是读取数目降低到1k的话,是没有这个问题的,尚有降低些qps(降低到10)都不会触发这个问题,因此想应该是qps和读取行数协调作用,每一行都市触发转换,触发了资源的争抢导致这个问题。















 1238
1238











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









