






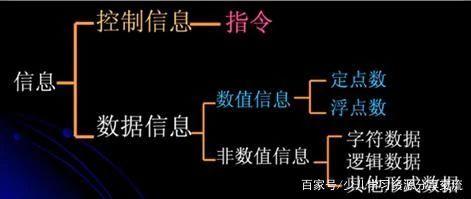
计算机、数据与信息


无符号位数的表示
(一)、四种常用的数制及它们之间的相互转换:
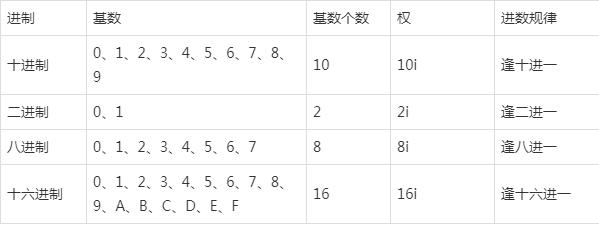
注意:在进行十六进制运算时,A、B、C、D、E、F六个字母要化成对应的十进制数:
10、11、12、13、14、15,详见后面例题。
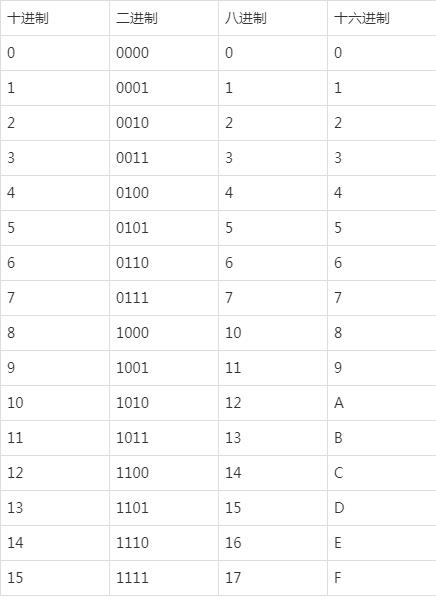
十进制、二进制、八进制与十六进制数字对照表(要求熟记于心)
十进制数转换为二进制数、八进制数、十六进制数的方法:
整数转换方法:除基反取余法
小数转换方法:乘基取整法
二进制数、八进制数、十六进制数转换为十进制数的方法:按权展开求和法
1.二进制与十进制间的相互转换:
(1)二进制转十进制
方法:“按权展开求和”
例: (1011.01)2=(1×23+0×22+1×21+1×20+0×2-1+1×2-2)10
=(8+0+2+1+0+0.25)10
=(11.25)10
规律:个位上的数字的次数是0,十位上的数字的次数是1,......,依奖递增,而十分位的数字的次数是-1,百分位上数字的次数是-2,......,依次递减。
注意:不是任何一个十进制小数都能转换成有限位的二进制数。
(2)十进制转二进制
· 十进制整数转二进制数:“除以2取余,逆序输出”(短除反取余法)
例: (89)10=(1011001)2
2 89
2 44 ……1
2 22 ……0
2 11 ……0
2 5 ……1
2 2 ……1
2 1 ……0
0 ……1
· 十进制小数转二进制数:“乘以2取整,顺序输出”(乘2取整法)
例: (0.625)10= (0.101)2
0.625
X 2
1.25 1
X 2
0.5 0
X 2
1.0 1
2.八进制与二进制的转换:
二进制数转换成八进制数:从小数点开始,整数部分向左、小数部分向右,每3位为一组用一位八进制数的数字表示,不足3位的要用“0”补足3位,就得到一个八进制数。
八进制数转换成二进制数:把每一个八进制数转换成3位的二进制数,就得到一个二进制数。
例:将八进制的37.416转换成二进制数:
3 7 . 4 1 6
011 111 .100 001 110
即:(37.416)8 =(11111.10000111)2
例:将二进制的10110.0011 转换成八进制:
0 1 0 11 0 . 0 0 1 1 0 0
2 6 . 1 4
即:(10110.011)2= (26.14)8
3.十六进制与二进制的转换:
二进制数转换成十六进制数:从小数点开始,整数部分向左、小数部分向右,每4位为一组用一位十六进制数的数字表示,不足4位的要用“0”补足4位,就得到一个十六进制数。
十六进制数转换成二进制数:把每一个八进制数转换成4位的二进制数,就得到一个二进制数。
例:将十六进制数5DF.9 转换成二进制:
5 D F . 9
0101 1101 1111 .1001
即:(5DF.9)16=(10111011111.1001)2
例:将二进制数1100001.111 转换成十六进制:
0110 0001 . 1110
6 1 . E
即:(1100001.111)2=(61.E)16
注意:以上所说的二进制数均是无正、负符号的数。这些数的范围如下表:

符号位数的表示
一、符号数的机器码表示方法
1.带符号二进制数的表示方法:
带符号二进制数用最高位的一位数来表示符号:0表示正,1表示负。

2、符号位的机器码表示:
1)机器数和真值
数在计算机中的表示形式统称为机器数,它有两上特点:其一,数的符号数值化;其二,二进制数的位数受计算机设备字长的限制。
字长:机器内部一次能表示的二进制位数由机器的字长,字长8位叫一个字节(Byte),一般机器字长都是字节的整数倍,如字长8位、16位、32位、64位等。
机器数的真值:指带符号位的机器数所对应的十进制数值;如符号数01001B,11011B的真值分别是+9和-11。
2)最常用的机器数的表示方法:原码、反码和补码。
(1)原码表示法:一个机器数x由符号闰和有效数值两部分组成,设符号位为x0,x真值的绝对值|x|=x1x2x3...xn,则x的机器数原码可表示为:
[x]原= ,当x>=0时,x0=0,当x<0时,x0=1。
例如:已知:x1=-1011B,x2= +1001B,则x1,x2有原码分别是
[x1] 原=11011B,[x2]原=01001B
规律:正数的原码是它本身,负数的原码是取绝对值后,在最高位(左端)补“1”。
(2)反码表示法:一个负数的原码符号位不变,其余各位按位取反就是机器数的反码表示法。正数的反码与原码相同。
按位取反的意思是该位上是1的,就变成0,该位上是0的就变成1。即1=0,0=1
设[x]原=,则当x0=0时,[x]反=[x]原=,
当x0=1时,[x]反=[x]原=。
例:,,求和。
解:=,=
(3)补码表示法:
首先分析两个十进制数年运算:78-38=41,79+62=141
如果使用两位数的运算器,做79+62时,多余的100因为超出了运算器两位数的范围而自动丢弃,这样在做78-38的减法时,用79+62的加法同样可以得到正确结果。
模是批一个计量系统的测量范围,其大小以计量进位制的基数为底数,位数为指数的幂。如两位十进制数的测量范围是1——9,溢出量是100,模就是102=100,上述运算称为模运算,可以写作:
79+(-38)=79+62 (mod 100)
进一步写为 -38=62,此时就说 –38的补法(对模100而言)是62。计算机是一种有限字长的数字系统,因此它的运算都是有模运算,超出模的运算结果都将溢出。n位二进制的模是2n,
一个数的补码记作[x]补,设模是M,x是真值,则补码的定义如下:
例:设计算机字长n=8位,机器数真值x=-1011011B,求[x]补。
解:因为 n=8,所以模 M=28=100000000B,x<0,所以
[x]补=M+x=100000000B-1011011B=10100101B
注意:这个x的补码的最高位是“1”,表明它是一个负数。对于二进制数还有一种更加简单的方法由原码求出补码:
(1)正数的补码表示与原码相同;
(2)负数的补码是将原码符号位保持“1”之后,其余各位按位取反,末位再加1便得到补码,即取其原码的反码再加“1”:[x]补=[x]补+1。
下表列出的8位二进制原码,反码和补码并将补码用十六进制表示。
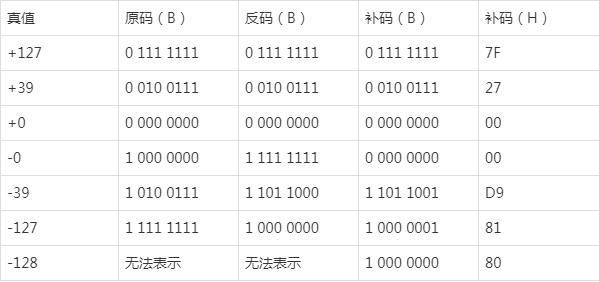
从上可看出,真值+0和-0的补码表示是一致的,但在原码和反码表示中具有不同形式。8位补码机器数可以表示-128,但不存在+128的补码与之对应,由此可知,8位二进制补码能表示数的范围是-128——+127。还要注意,不存在-128的8位原码和反码形式。
二、定点数和浮点数
(一)定点数(Fixed-Point Number)
计算机处理的数据不仅有符号,而且大量的数据带有小数,小数点不占有二进制一位而是隐含在机器数里某个固定位置上。通常采取两种简单的约定:一种是约定所有机器数的小数的小数点位置隐含在机器数的最低位之后,叫定点纯整机器数,简称定点整数。如

小数点位置
若有符号位,符号位仍在最高位。因小数点隐含在数的最低位之后,所以上数表示+1011001B。另一种约定所有机器数的小数点隐含在符号位之后、有效部分最高位之前,叫定点纯小数机器数,简称定点小数,例如

小数点位置
最高位是符号,小数点在符号位之后,所以上数表示 -0.0101101B。
无论是定点整数,还是定点小数,都可以有原码、反码和补码三种形式。例如定点小数

如果这是个原码表示的定点小数,[x]原=11110000B,则x= -0.111B=-0.875D,如这是补码表示的定点小数,[x]补=11110000B,则[x]原=10010000B,则x= -0.001B=-0.125D。(想一想,如何由补码求原码?)
(二)浮点数(Floating-Point Number)
计算机多数情况下采作浮点数表示数值,它与科学计数法相似,把一个二进制数通过移动小数点位置表示成阶码和尾数两部分:
其中:E——N的阶码(Expoent),是有符号的整数
S——N的尾数(Mantissa),是数值的有效数字部分,一般规定取二进制定点纯小数形式。
例:1011101B=2+7*0.11101,101.1101B=2+3*0.1011101,0.01011101B=2-1*1011101
浮点数的格式如下:

阶符 阶 尾符 尾数
浮点数由阶码和尾数两部分组成,底数2在机器数中不出现,是隐含的。阶码的正负符号E0,在最前位,阶反映了数N小数点的位置,常用补码表示。二进制数N小数点每左移一位,阶增加1。尾数是这点小数,常取补码或原码,码制不一定与阶码相同,数N的小数点右移一位,在浮点数中表现为尾数左移一位。尾数的长度决定了数N的精度。尾数符号叫尾符,是数N的符号,也占一位。
例:写出二进制数-101.1101B的浮点数形式,设阶码取4位补码,尾数是8位原码。
-101.1101=-0.1011101*2+3
浮点形式为:
阶码0011 尾数11011101
补充解释:阶码0011中的最高位“0”表示指数的符号是正号,后面的“011”表示指数是“3”;尾数11011101的最高位“1”表明整个小数是负数,余下的1011101是真正的尾数。
浮点数运算后结果必须化成规格化形式,所谓规格化,是指对于原码尾数来说,应使最高位数字S1=1,如果不是1且尾数不是全0时就要移动尾数直到S1=1,阶码相应变化,保证N值不变。
例:计算机浮点数格式如下,写出x=0.0001101B的规格化形式,阶码是补码,尾数是原码。
x=0.0001101=0.1101*10-3
又[-3]补=[-001B]补=[1011]补=1101B
所以 规格化浮点数形式是

三、ASCII码( American Standard Code forInformation Interchange )
美国标准信息交换代码
将每个字符用7位的二进制数来表示,共有128种状态
大小字母、0…9、其它符号、控制符
‘ 0 ’ ―― 48
‘ A ’ ―― 65
‘ a ’ ―― 97
汉字信息编码
1.汉字输入码
汉字输入方法大体可分为:区位码(数字码)、音码、形码、音形码。
· 区位码:优点是无重码或重码率低,缺点是难于记忆;
· 音码:优点是大多数人都易于掌握,但同音字多,重码率高,影响输入的速度;
· 形码:根据汉字的字型进行编码,编码的规则较多,难于记忆,必须经过训练才能较好地掌握;重码率低
· 音形码:将音码和形码结合起来,输入汉字,减少重码率,提高汉字输入速度;
2.汉字交换码
汉字交换码是指不同的具有汉字处理功能的计算机系统之间在交换汉字信息时所使用的代码标准。自国家标准GB2312-80公布以来,我国一直延用该标准所规定的国标码作为统一的汉字信息交换码。
GB2312-80标准包括了6763个汉字,按其使用频度分为一级汉字3755个和二级汉字3008个。一级汉字按拼音排序,二级汉字按部首排序。此外,该标准还包括标点符号、数种西文字母、图形、数码等符号682个。
区位码的区码和位码均采用从01到94的十进制,国标码采用十六进制的21H到73H(数字后加H表示其为十六进制数)。区位码和国标码的换算关系是:区码和位码分别加上十进制数32。如“国”字在表中的25行90列,其区位码为2590,国标码是397AH。
* 由于GB2312-80是80年代制定的标准,在实际应用时常常感到不够,所以,建议处理文字信息的产品采用新颁布的GB18030信息交换用汉字编码字符集,这个标准繁、简字均处同一平台,可解决两岸三地间GB码与BIG5码间的字码转换不便的问题。
3.字形存储码
字形存储码是指供计算机输出汉字(显示或打印)用的二进制信息,也称字模。通常,采用的是数字化点阵字模。如下图:

一般的点阵规模有16×16,24×24,32×32,64×64等,每一个点在存储器中用一个二进制位(bit)存储。例如,在16×16的点阵中,需16×16=8×32 bit 的存储空间,每8bit为1字节,所以,需32字节的存储空间。在相同点阵中,不管其笔划繁简,每个汉字所占的字节数相等。
为了节省存储空间,普遍采用了字形数据压缩技术。所谓的矢量汉字是指用矢量方法将汉字点阵字模进行压缩后得到的汉字字形的数字化信息。
4.其它信息的数字化
1)、图像信息的数字化
一幅图像可以看作是由一个个像素点构成,图像的信息化,就是对每个像素用若干个二进制数码进行编码。图像信息化后,往往还要进行压缩。
图像文件的后缀名有:bmp、gif、jpg等;
2)、声音信息的数字化
自然界的声音是一种连续变化的模拟信息,可以采用A/D转换器对声音信息进行数字化。
声音文件的后缀名有:wav、mp3、mid等;
3)、视频信息的数字化
视频信息可以看成连续变换的多幅图像构成,播放视频信息,每秒需传输和处理25幅以上的图像。视频信息数字化后的存储量相当大,所以需要进行压缩处理。
视频文件后缀名有:avi、mpg等;
举报/反馈














 2443
2443











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









