











进制转换
1、进制定义
二进制:是指在数学和数字电路中以2为基数的记数系统,二进制只有0和1两个数字符号,其运算规律是逢2进1,例如101101。
八进制:一种以8为基数的计数法,采用0,1,2,3,4,5,6,7这八个数字符号,其运算规律是逢8进1,例如77。
十进制:一种以10为基数的计数法,采用0,1,2,3,4,5,6,7,8,9这十个数字符号,其运算规律是逢10进1,例如88。
十六进制:一种以16为基数的计数法,采用0,1,2,3,4,5,6,7,8,9,A,B,C,D,E,F这十六个数字和字母符号,其运算规律是逢16进1,例如9527。
2、各进制间的转换方法
2.1 二进制转其他进制
二进制转十进制: 采用位置计数法,其位权是以2为底的幂,顺序从右到左,从0开始计数。
例如二进制数1011(二进制) = 1 * 23 + 0 * 22 + 1 * 21 + 1 * 20 = 11(十进制)。
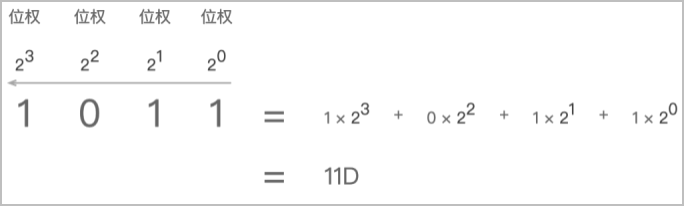
二进制转八进制: 采用三合一法,即从二进制的小数点为分界点,向左(或向右)每三位取成一位来计算,不足三位的前面补0
例如:10110011B = (0)10 110 011 = 263(八进制)。
二进制转十六进制: 采用四合一法,即从二进制的小数点为分界点,向左(或向右)每四位取成一位来计算,不足四位的前面补0
例如:10110011B = 1011 0011 = B3(十六进制)。

2.2 十进制转其他进制
-
十进制转二进制
整数采用“除2倒取余”,小数采用“乘2取整”。
例如十进制数135转换成二进制时,将135除以2,得余数,直到不能整除,然后再将余数从下至上倒取,结果为10000111(二进制)。 -
十进制转八进制
和转二进制的方法类似,整数采用“除8倒取余”,小数采用“乘8取整”。
例如十进制数10转换成二进制时,将10除以8,得余数,直到不能整除,然后再将余数从下至上倒取,结果为12(八进制)。 -
十进制转十六进制
思路和转二进制、八进制一样,十进制数25转换成十六进制时,结果为19(十六进制)。
2.3 八进制转其他进制
-
八进制转二进制:和二进制转八进制的方法相反,采用三合一法,例如:263(八进制) = 010 110 011(二进制)。
-
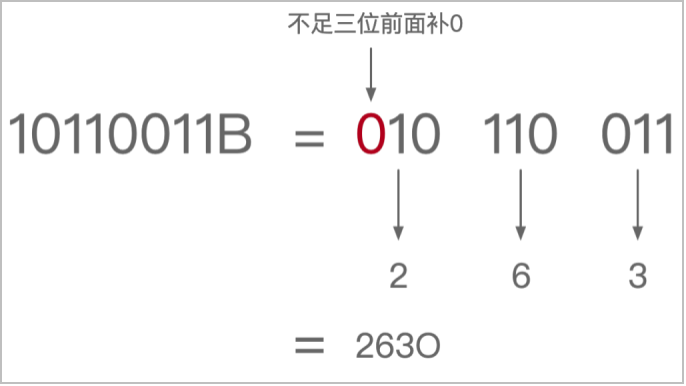
八进制转十进制:和二进制转十进制的方法一样,采用位置计数法,其位权是以8为底的幂,顺序从右到左,从0开始计数。例如八进制数26(八进制) = 2 * 81 + 6 * 80 = 22(十进制)。
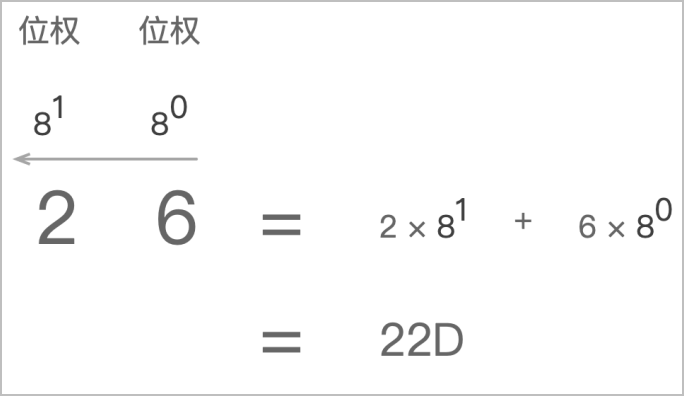
- 八进制转十六进制:不能直接转换,需要先转成二进制,再将二进制转成十六进制。
2.4 十六进制转其他进制
-
十六进制转二进制:和二进制转十六进制的方法相反,采用四合一法,例如:B3(十六进制) = 1011 0011 = 10110011(二进制)。
-
十六进制转八进制:不能直接转换,需要先转成二进制,再将二进制转成八进制。
-
十六进制转十进制:和二进制转十进制的方法一样,采用位置计数法,其位权是以16为底的幂,顺序从右到左,从0开始计数。例如十六进制数26(十六进制) = 2 * 161 + 6 * 160 = 38(十进制)。

信息单位
在计算机内部,信息都是釆用二进制的形式存储、运算、处理和传输的。信息的存储和传输是以位(bit)、字节(Byte)、千字节(Kilo Byte)、兆字节(Mega Byte)等计量标准为单位的。
1、单位定义
存储单位: 存储在计算机硬盘或内存中的信息容量标准,最小计量单位是“位”(bit,比特),一个比特位表示一个二进制的0或1在计算机中所占用的存储空间
传输单位: 在计算机网络中称为带宽,宽带传输速率的单位为bps,bps是bit per second的缩写,表示每秒钟传输多少比特位信息(很多人都会把这里的bit误以为是Byte,也就是错把位当成字节),例如:带宽的单位是10Mb/s,这里其实指的是每秒传输10兆位,而不是10兆字节数据,因此将位数需要除以8换算成字节数,也就是每秒传输1.25兆字节,即10Mbit/s = 1.25MByte/s
2、换算公式
- 1字节(Byte)= 8位(bit)
- 1KB(Kilo Byte,千字节)= 1024B(Byte)
- 1MB(Mega Byte,兆字节)= 1024KB
- 1GB(Giga Byte,吉字节)= 1024MB
- 1TB(Tera Byte,太字节)= 1024GB
- 1PB(Peta Byte,拍字节)= 1024TB
- 1EB(Exa Byte,艾字节)= 1024PB
- 1ZB(Zeta Byte,泽字节)= 1024EB
- 1YB(Yotta Byte,尧字节)= 1024ZB
- 1BB(Bronto Byte,珀字节)= 1024YB
- 1NB(Nona Byte,诺字节)= 1024BB
- 1DB(Dogga Byte,刀字节)= 1024NB
数据校验
数据在传输的过程中,会受到各种干扰的影响,如脉冲干扰,随机噪声干扰和人为干扰等,这会使数据产生差错。为了能够控制、减少甚至消除传输过程中的差错,就必须采用有效的措施来控制差错的产生。
1、奇偶校验
根据传输的二进制数据和奇偶校验位中“1”的个数进行校验。
如果连同校验位中“1”的个数是奇数,就是奇校验;反之,就是偶校验

技术特点: 简单,可以检测出错误,但无法确切地知道哪里有错,也无法修改,只能要求重传
适用场景: 应用广泛,但不适宜在信号噪声较多的环境中传输
多媒体基础参数
所谓多媒体(Multimedia)指的是多种媒体的综合,一般包括图像、声音和视频等形式或者它们的组合。可以通过基础参数来衡量多媒体文件质量的好坏。
1、参数定义
比特率: 音视频、图像都可以采用这个指标,它指的是规定时间内传输的比特数,单位是bps(bit per second),比特率越高,数据传输的速度就越快,流媒体的播放质量就越好(音视频越清晰),所需带宽也越大,比特率有时候也和码率混为一谈,但码率的单位一般是kbps(千位每秒)。
采样率: 专用于音频多媒体,也称为采样速度或者采样频率,它定义了每秒从连续信号中提取并组成离散信号的采样个数,单位为赫兹(Hz) 。采样率的意义在于将模拟信号转换成数字信号时的采样频率,也就是单位时间内采样多少个点,常用的采样率为44.1KHz。
采样位深: 也被称为采样精度,单位为Bit,常见的位深有16Bit和24Bit,它其实就是每个采样样本中信息的比特数。
2、计算公式
视频码率计算公式(kbps,千位每秒) = 文件大小(KB,千字节)* 8 / 秒数
音频码率计算公式(kbps,千位每秒) = 采样率 × 采样位深 × 通道数
HTTP
超文本传输协议(Hyper Text Transfer Protocol,HTTP)是一个简单的请求-响应协议,它通常运行在TCP之上。它指定了客户端可以给服务器发送什么样的消息以及能够得到什么样的响应。这个简单的模型是早期Web应用得以普及的重要保障,可以说没有HTTP协议,就没有今天丰富多彩、繁荣兴旺的互联网。
HTTP特性
-
HTTP 协议构建于 TCP/IP 协议之上,是一个应用层协议,默认端口号是 80
-
HTTP 是无连接无状态的
请求报文
HTTP 协议是以 ASCII 码传输,建立在 TCP/IP 协议之上的应用层规范。规范把 HTTP 请求分为三个部分:状态行、请求头、消息主体。类似于下面这样:
<method> <request-URL> <version>
<headers>
<entity-body>
HTTP 定义了与服务器交互的不同方法,最基本的方法有4种,分别是GET,POST,PUT,DELETE。
URL全称是资源描述符,我们可以这样认为:一个URL地址,它用于描述一个网络上的资源,而 HTTP 中的GET,POST,PUT,DELETE就对应着对这个资源的 查,增,改,删 4个操作。
-
GET 用于信息获取,而且应该是安全的 和 幂等的。
所谓安全的意味着该操作用于获取信息而非修改信息。换句话说,GET 请求一般不应产生副作用。就是说,它仅仅是获取资源信息,就像数据库查询一样,不会修改,增加数据,不会影响资源的状态。
幂等的意味着对同一 URL 的多个请求应该返回同样的结果。
GET 请求报文示例:
GET /books/?sex=man&name=Professional HTTP/1.1 Host: www.example.com User-Agent: Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.7.6) Gecko/20050225 Firefox/1.0.1 Connection: Keep-Alive -
POST 表示可能修改变服务器上的资源的请求。
POST / HTTP/1.1 Host: www.example.com User-Agent: Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.7.6) Gecko/20050225 Firefox/1.0.1 Content-Type: application/x-www-form-urlencoded Content-Length: 40 Connection: Keep-Alive sex=man&name=Professional -
注意:
-
GET 可提交的数据量受到URL长度的限制,HTTP 协议规范没有对 URL 长度进行限制。这个限制是特定的浏览器及服务器对它的限制
-
理论上讲,POST 是没有大小限制的,HTTP 协议规范也没有进行大小限制,出于安全考虑,服务器软件在实现时会做一定限制
-
参考上面的报文示例,可以发现 GET 和 POST 数据内容是一模一样的,只是位置不同,一个在 URL 里,一个在 HTTP 包的包体里
POST 提交
HTTP 协议中规定 POST 提交的数据必须在 body 部分中,但是协议中没有规定数据使用哪种编码方式或者数据格式。实际上,开发者完全可以自己决定消息主体的格式,只要最后发送的 HTTP 请求满足上面的格式就可以。
但是,数据发送出去,还要服务端解析成功才有意义。一般服务端语言如 PHP、Python 等,以及它们的 framework,都内置了自动解析常见数据格式的功能。服务端通常是根据请求头(headers)中的 Content-Type 字段来获知请求中的消息主体是用何种方式编码,再对主体进行解析。所以说到 POST 提交数据方案,包含了 Content-Type 和消息主体编码方式两部分。下面就正式开始介绍它们:
application/x-www-form-urlencoded
这是最常见的 POST 数据提交方式。浏览器的原生 <form> 表单,如果不设置 enctype 属性,那么最终就会以 application/x-www-form-urlencoded 方式提交数据。上个小节当中的例子便是使用了这种提交方式。可以看到 body 当中的内容和 GET 请求是完全相同的。
multipart/form-data
这又是一个常见的 POST 数据提交的方式。我们使用表单上传文件时,必须让 <form> 表单的 enctype 等于 multipart/form-data 。直接来看一个请求示例:
POST http://www.example.com HTTP/1.1
Content-Type:multipart/form-data; boundary=----WebKitFormBoundaryrGKCBY7qhFd3TrwA
------WebKitFormBoundaryrGKCBY7qhFd3TrwA
Content-Disposition: form-data; name="text"
title
------WebKitFormBoundaryrGKCBY7qhFd3TrwA
Content-Disposition: form-data; name="file"; filename="chrome.png"
Content-Type: image/png
PNG ... content of chrome.png ...
------WebKitFormBoundaryrGKCBY7qhFd3TrwA--
这个例子稍微复杂点。首先生成了一个 boundary 用于分割不同的字段,为了避免与正文内容重复,boundary 很长很复杂。然后 Content-Type 里指明了数据是以 multipart/form-data 来编码,本次请求的 boundary 是什么内容。消息主体里按照字段个数又分为多个结构类似的部分,每部分都是以 --boundary 开始,紧接着是内容描述信息,然后是回车,最后是字段具体内容(文本或二进制)。如果传输的是文件,还要包含文件名和文件类型信息。消息主体最后以 --boundary-- 标示结束。
这种方式一般用来上传文件,各大服务端语言对它也有着良好的支持。
上面提到的这两种 POST 数据的方式,都是浏览器原生支持的,而且现阶段标准中原生 <form> 表单也只支持这两种方式(通过 <form> 元素的 enctype 属性指定,默认为 application/x-www-form-urlencoded 。其实 enctype 还支持 text/plain,不过用得非常少)。
随着越来越多的 Web 站点,尤其是 WebApp,全部使用 Ajax 进行数据交互之后,我们完全可以定义新的数据提交方式,例如 application/json,text/xml ,乃至 application/x-protobuf 这种二进制格式,只要服务器可以根据 Content-Type 和 Content-Encoding 正确地解析出请求,都是没有问题的。
响应报文
HTTP 响应与 HTTP 请求相似,HTTP响应也由3个部分构成,分别是:
- 状态行
- 响应头(Response Header)
- 响应正文
状态行由协议版本、数字形式的状态代码、及相应的状态描述,各元素之间以空格分隔。
常见的状态码有如下几种:
- 200 OK 客户端请求成功
- 301 Moved Permanently 请求永久重定向
- 302 Moved Temporarily 请求临时重定向
- 304 Not Modified 文件未修改,可以直接使用缓存的文件。
- 400 Bad Request 由于客户端请求有语法错误,不能被服务器所理解。
- 401 Unauthorized 请求未经授权。这个状态代码必须和WWW-Authenticate报头域一起使用
- 403 Forbidden 服务器收到请求,但是拒绝提供服务。服务器通常会在响应正文中给出不提供服务的原因
- 404 Not Found 请求的资源不存在,例如,输入了错误的URL
- 500 Internal Server Error 服务器发生不可预期的错误,导致无法完成客户端的请求。
- 503 Service Unavailable 服务器当前不能够处理客户端的请求,在一段时间之后,服务器可能会恢复正常。
下面是一个HTTP响应的例子:
HTTP/1.1 200 OK
Server:Apache Tomcat/5.0.12
Date:Mon,6Oct2003 13:23:42 GMT
Content-Length:112
<html>...
Cookie 和 Session的区别
1、存取方式的不同
Cookie中只能保管ASCII字符串,假如需求存取Unicode字符或者二进制数据,需求先进行编码。Cookie中也不能直接存取Java对象。若要存储略微复杂的信息,运用Cookie是比拟艰难的。而Session中能够存取任何类型的数据,包括而不限于String、Integer、List、Map等。Session中也能够直接保管Java Bean乃至任何Java类,对象等,运用起来十分便当。能够把Session看做是一个Java容器类。
2、隐私策略的不同
Cookie存储在客户端阅读器中,对客户端是可见的,客户端的一些程序可能会窥探、复制以至修正Cookie中的内容。而Session存储在服务器上,对客户端是透明的,不存在敏感信息泄露的风险。假如选用Cookie,比较好的方法是,敏感的信息如账号密码等尽量不要写到Cookie中。最好是像Google、Baidu那样将Cookie信息加密,提交到服务器后再进行解密,保证Cookie中的信息只要本人能读得懂。而假如选择Session就省事多了,反正是放在服务器上,Session里任何隐私都能够有效的保护。
3、有效期上的不同
使用过Google的人都晓得,假如登录过Google,则Google的登录信息长期有效。用户不用每次访问都重新登录,Google会持久地记载该用户的登录信息。要到达这种效果,运用Cookie会是比较好的选择。只需要设置Cookie的过期时间属性为一个很大很大的数字。由于Session依赖于名为JSESSIONID的Cookie,而Cookie JSESSIONID的过期时间默许为–1,只需关闭了阅读器该Session就会失效,因而Session不能完成信息永世有效的效果。运用URL地址重写也不能完成。而且假如设置Session的超时时间过长,服务器累计的Session就会越多,越容易招致内存溢出。
4、服务器压力的不同
Session是保管在服务器端的,每个用户都会产生一个Session。假如并发访问的用户十分多,会产生十分多的Session,耗费大量的内存。因而像Google、Baidu、Sina这样并发访问量极高的网站,是不太可能运用Session来追踪客户会话的。而Cookie保管在客户端,不占用服务器资源。假如并发阅读的用户十分多,Cookie是很好的选择。关于Google、Baidu、Sina来说,Cookie或许是唯一的选择。
5、浏览器支持的不同
Cookie是需要客户端浏览器支持的。假如客户端禁用了Cookie,或者不支持Cookie,则会话跟踪会失效。关于WAP上的应用,常规的Cookie就派不上用场了。假如客户端浏览器不支持Cookie,需要运用Session以及URL地址重写。需要注意的是一切的用到Session程序的URL都要进行URL地址重写,否则Session会话跟踪还会失效。关于WAP应用来说,Session+URL地址重写或许是它唯一的选择。假如客户端支持Cookie,则Cookie既能够设为本浏览器窗口以及子窗口内有效(把过期时间设为–1),也能够设为一切阅读器窗口内有效(把过期时间设为某个大于0的整数)。但Session只能在本阅读器窗口以及其子窗口内有效。假如两个浏览器窗口互不相干,它们将运用两个不同的Session。(IE8下不同窗口Session相干)
6、跨域支持上的不同
Cookie支持跨域名访问,例如将domain属性设置为“.biaodianfu.com”,则以“.biaodianfu.com”为后缀的一切域名均能够访问该Cookie。跨域名Cookie如今被普遍用在网络中,例如Google、Baidu、Sina等。而Session则不会支持跨域名访问。Session仅在他所在的域名内有效。仅运用Cookie或者仅运用Session可能完成不了理想的效果。这时应该尝试一下同时运用Cookie与Session。Cookie与Session的搭配运用在实践项目中会完成很多意想不到的效果。
总结
Session 是在服务端保存的一个数据结构,用来跟踪用户的状态,这个数据可以保存在集群、数据库、文件中;
Cookie 是客户端保存用户信息的一种机制,用来记录用户的一些信息,也是实现Session的一种方式。
HTTPS
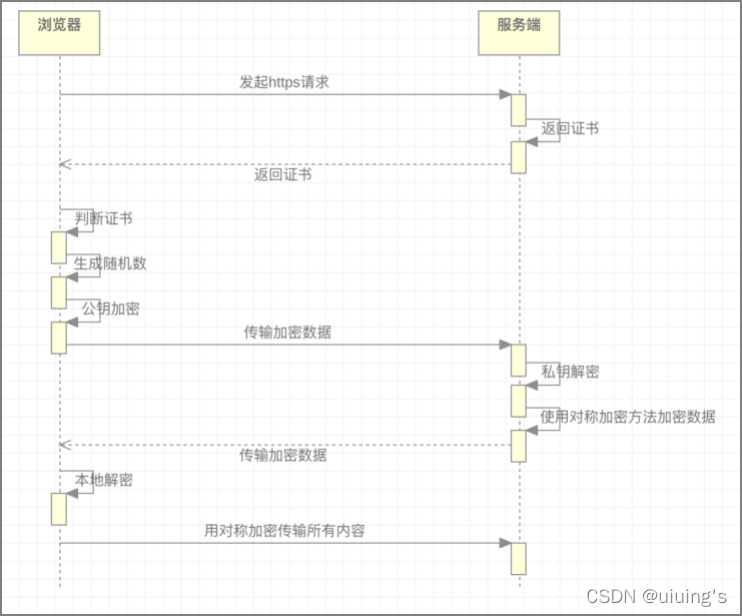
HTTPS(全称是Hyper Text Transfer Protocol over SecureSocket Layer)是身披SSL/TLS外壳的HTTP。它在HTTP之上利用SSL/TLS建立安全的信道,加密数据传输。
1、加密算法
对称加密: 加密与解密用同一套密钥,如DES、3DES和AES等
非对称加密: 加密和解密所使用的密钥不同,如RSA、DSA等
不可逆加密: 明文加密后无法通过解密来复原,如MD5、SHA等
2、SSL
全称Secure Sockets Layer,安全套接字协议,因为HTTP是用明文来传输数据的,传输内容可能会被偷窥(嗅探)和篡改,SSL的出现就是用来解决信息安全问题的,当前版本为3.0。
它位于TCP/IP协议与各种应用层协议之间,自身又分为两层: SSL记录协议(SSL Record Protocol)和SSL握手协议(SSL Handshake Protocol)。


3、TLS
全称Transport Layer Security,传输层协议,它是在SSL3.0基础上设计的,相当于SSL的后续版本,它的目标是让SSL更安全。

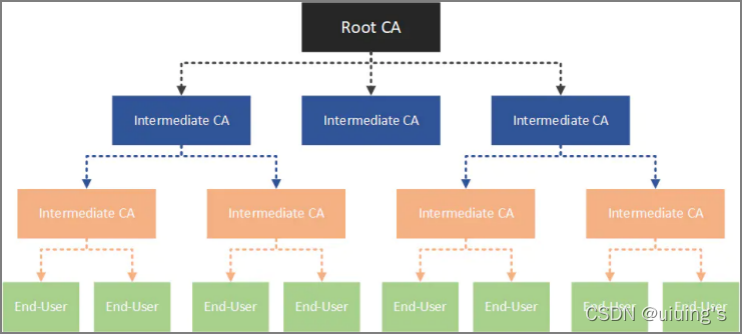
4、证书与证书链
大学读完之后有毕业证书,并且这个证书可以在学信网查询
专业上有注会、CCIE、律师证等,可以在国家职业认证机构或委托机构的网站上查到
公司注册之后,营业执照信息也可以在天眼查或企查查上找到
证书的作用
- 过往经历的证明
- 第三方信用担保
- 唯一合法性检验
OSI七层模型
OSI的全称是Open System Interconnection(开放系统互联),是一个定义得较为完备的协议规范。它最大的意义在于解决了不同网络之间的互联互通问题,并且清晰地定义了不同网络层次之间的边界和职责。
应用层(Application Layer)
是OSI参考模型的最高层,它是用户、应用程序和网络之间的接口,它直接向用户提供服务,替用户在网络上完成各种工作。
表示层(Presentation Layer)
是OSI参考模型的第六层,它对来自应用层的指令和数据进行解释,对各种语法赋予相应的含义,它主要功能是处理用户信息的表示问题,例如数据编码、数据格式转换和加解密等。
会话层(Session Layer)
是OSI参考模型的第五层,它的主要任务是为两个实体的表示层提供建立和使用连接的方法(不同实体之间表示层的连接称为会话),组织和协调两个会话进程之间的通信,并对数据交换进行管理。
传输层(Transport Layer)
是OSI参考模型的第四层。该层的主要任务是向用户提供可靠的端到端的差错和流量控制,保证报文的正确传输,同时向高层屏蔽下层数据通信的细节。
网络层(Network Layer)
是OSI参考模型的第三层,它是最复杂的一层,也是通信子网的最高一层。它在下两层的基础上向上层提供服务。它的主要任务是通过路由选择算法,为报文或分组选择最合适的路径。该层控制数据链路层与传输层之间的信息转发,建立、维持和终止网络的连接。
数据链路层(Data Link Layer)
是OSI参考模型的第二层,它负责建立和管理节点间的链路。同时通过各种控制协议,将有差错的物理信道变为无差错的、能可靠传输数据帧的数据链路。
物理层(Physical Layer)
是OSI参考模型的第一层,也是最底层。它的主要功能是利用传输介质为数据链路层提供物理连接,实现比特流的透明传输。它使数据链路层不必考虑网络的具体传输介质是什么。“比特流的透明传输”表示经实际电路传送后的比特流没有发生变化,对传送的比特流来说,这个电路好像是看不见的。
发送电子邮件示意图
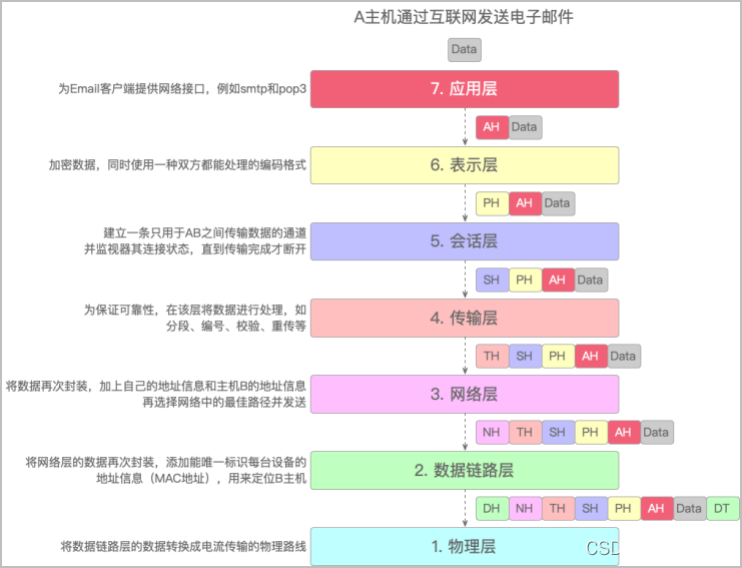
接收电子邮件示意图
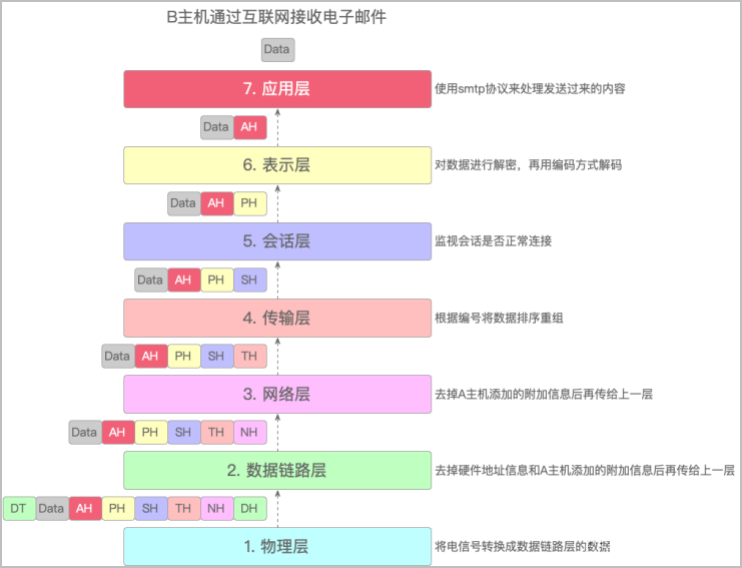
各层级常用协议

IP基础
IP是Internet Protocol(网际协议)的缩写,是整个TCP/IP协议族的核心,也是构成互联网的基础,可以说,只要计算机在网络中存在,就一定会有能够找得到它的IP地址。IP主要包含三方面的内容:IP编址方案、分组封装格式及分组转发规则。本任务所涉及的仅仅是IP编址方案。
1、IP地址
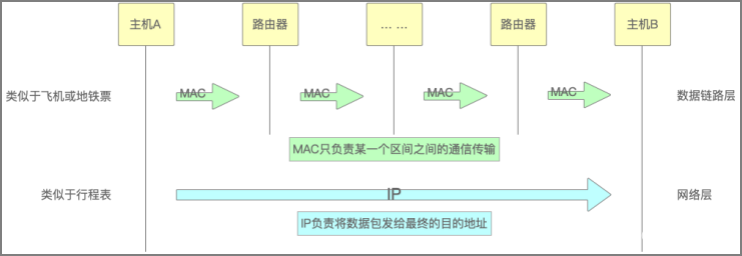
IP位于网络层,作用是主机间的通信,负责在没有直连的两个网络之间传输通信数据,而MAC位于数据链路层,作用是实现两个设备之间的直连通信
IP和MAC的区别
IP地址(IPv4)由32位二进制数表示,在计算机中是以二进制的方式处理的,人类为了方便记忆而采用了点分十进制的标记方式:也就是将32位二进制的IP地址以每8位为一组,共分为4组,组之间用“.”隔开,再将每组转换成十进制数表示。
也就是说,IP地址的最大值就是2^32 = 4294967296
IPv4的表示方法

2、IP地址分类
互联网诞生之初,IP地址显得很充裕,因此计算机科学家们设计了分类地址。他们把IP地址分为五种类型:A、B、C、D、E。
A、B、C、D、E五类IP地址
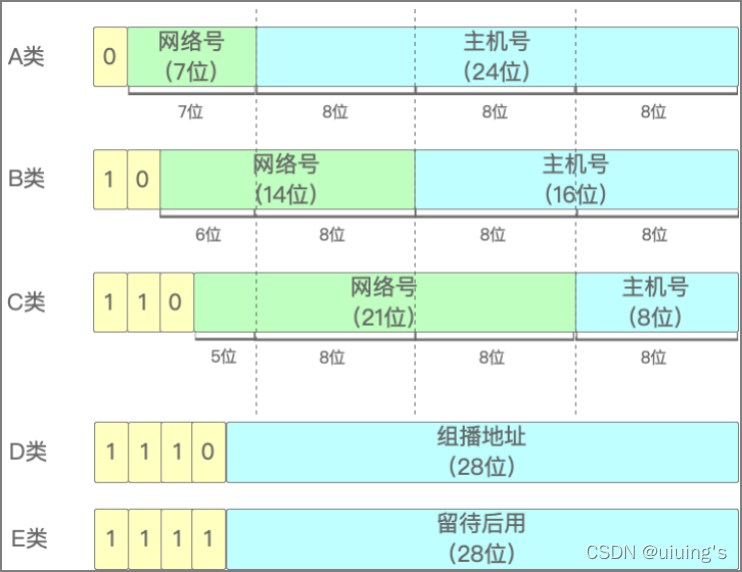
| 类别 | IP地址范围 | 最大主机数 |
|---|---|---|
| A | 0.0.0.0 ~ 127.255.255.255 | 16777214 |
| B | 128.0.0.0 ~ 191.255.255.255 | 65534 |
| C | 192.0.0.0 ~ 223.255.255.255 | 254 |
为什么要有网络号? 因为除了需要定位某台具体的计算机,还需要定位某个网络。网络号和主机号的关系,就好比楼栋和住户的关系,也就是**「网络号:主机号 == 楼栋号:住户」**。
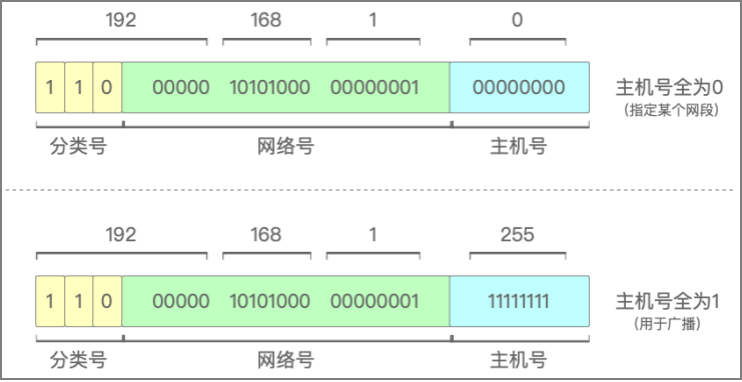
最大主机数 = 2^主机号的位数 - 2, 例如C类IP地址的主机号位数为8,那么C类IP地址的最大主机数 = 28 - 2 = 254。之所以要减2,是因为有两个IP是特殊的,分别是主机号全为1和主机号全为0。
最大主机数要排除全0和全1的主机号
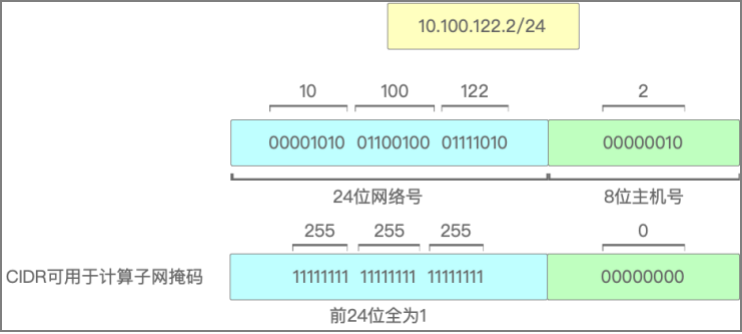
3、无分类地址CIDR
不再有A、B、C、D、E等分类的概念,而是仅仅将32位的IP地址划分成两部分:网络号 + 主机号,形式为:a.b.c.d/x,其中/x表示前x位属于网络号,范围是0~32。例如10.100.122.2/24,通过CIDR也可以得到子网掩码。
CIDR无分类地址
4、小知识
在A、B、C三类地址中,分别都有一个保留地址。
-
A类: 10.0.0.0 ~ 10.255.255.255
-
B类: 172.16.0.0 ~ 172.31.255.255
-
C类: 192.168.0.0 ~ 192.168.255.255
也就是说,这三组地址是私有网络地址,在互联网上是用不了的
本机IP、127.0.0.1和localhost 他们之间的区别
-
本机IP: 确切地说是本机物理网卡的IP地址,它发送和接收数据会受到防火墙和网卡的限制
-
127.0.0.1: 这是一个环回地址,也是一个特殊的网络接口,从它发出的任何数据包都不会出现在网络中,它发送和接收数据也会受到防火墙和网卡的限制
-
localhost: 它是一个域名,过去它指向127.0.0.1这个IP地址,现在它同时还指向IPv6地址:[::1] ,它发送和接收数据不会受防火墙和网卡的限制
IPv6
在IPv4诞生的时代,是无法预见今日互联网的繁荣程度的,因此很多设计问题在发展的过程中也逐渐暴露出来,例如分类不合理,可用的公网IP地址总数量太少等等。在此情况下,出现了IPv6。IPv6是英文“Internet Protocol Version 6”(互联网协议第6版)的缩写,是互联网工程任务组(IETF) 设计的用于替代IPv4的下一代IP协议,其地址数量号称可以为全世界的每一粒沙子编上一个地址。
冒分十六进制表示法: 格式为X:X:X:X:X:X:X:X,每个X表示地址中的16个二进制位(或者十六进制数)
例如:ABCD:EF01:2345:6789:ABCD:EF01:2345:6789,这种表示法中,X中的前导0是可以省略的。
0位压缩表示法: 如果一个IPv6地址中间包含很长的一段0,就可以把连续的一段0压缩为“::”。但这种形式“::”只能出现一次。
内嵌IPv4表示法: 为了和IPv4兼容,IPv4地址可以嵌入IPv6地址中,此时地址格式为:X:X:X:X:X:X:d.d.d.d ,前96位采用冒分十六进制表示,而最后32位则使用IPv4的点分十进制表示,例如:::192.168.0.1。
网络拓扑
互联网是一个广义上的概念,它泛指的是一切通过网络连接在一起的计算机集合。所以,如果只是观察局部,比如某一家公司的网络的话,那么就不能再说这家公司的网络就是“互联网”了。那么,对于每家公司来说,网络具体又是如何构成的呢?这就是网络拓扑结构要解决的问题。如同数据结构是按照某种形式组织数据一样,网络拓扑结构指的也是按照某种形式将不同的物理计算机连接在一起。
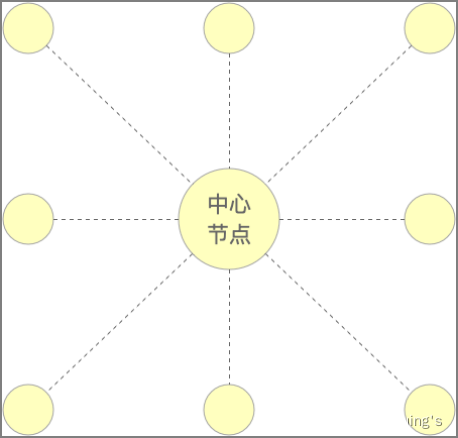
星型结构
指各计算机以星型方式连接成网。
网络有中央节点,其他结点(工作站、服务器)都与中央节点直接相连,这种结构以中央结点为中心,因此又称为集中式网络。它具有结构简单、便于管理、控制简单、网络延迟时间小、传输误差低等特点。但缺点也是明显的:可靠性较低、资源共享能力较差、线路利用率低。
总线型结构
是指各工作站和服务器均挂在一条总线上,各工作站地位平等,无中心节点控制,它结构简单、可扩充性好、安装容易,但维护困难。
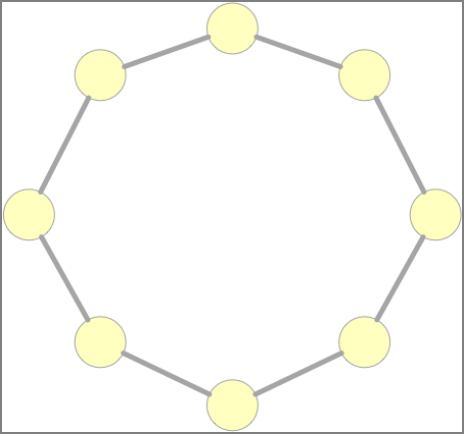
环型结构
由网络中若干结点通过通信链路首尾相连形成一个闭合的环,这种结构使公共传输电缆组成环状,数据在环路中沿着一个方向在各个节点间传输,信息从一个节点传到另一个节点。它实时性强、传输控制容易,但维护困难,可靠性不高。
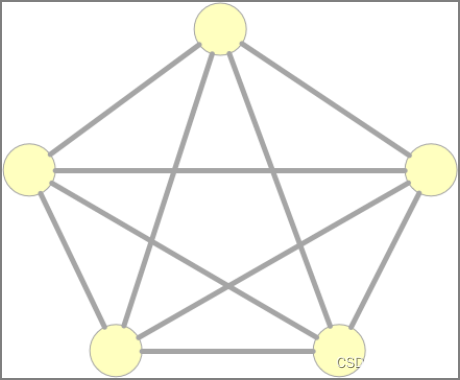
网状结构
它是指每台设备之间均有点到点的链路连接,这种连接不经济,只有每个站点都要频繁发送信息时才使用这种方法。它的安装也比较复杂,但系统可靠性高,容错能力强。有时也称为分布式结构。
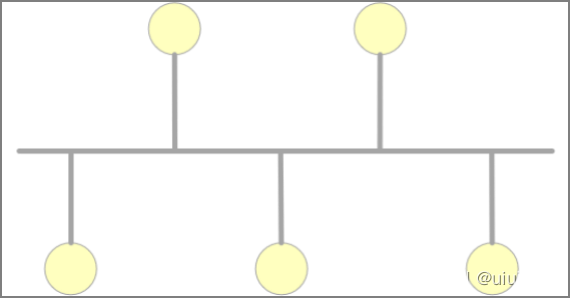
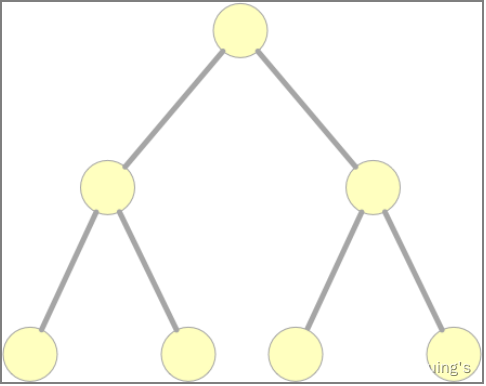
树型结构
这是一种分级的集中控制式网络,与星型相比,它的通信线路总长度短,成本较低、节点易于扩充、寻找路径方便,但除了叶节点及其相连的线路外,任一节点或其相连的线路故障都会使系统受到影响。
域名解析
在互联网上有成千上万台计算机,为了能准确地访问其中某台计算机上的服务,在OSI七层模型的网络层中,通过IP地址来唯一标记每台主机在网络里的位置,比如:39.106.226.142。但是这些纯数字的IP地址太难记了,因而就出现了域名(比如csdn.net)这样便于人类记忆的地址符号。这相当于现实世界中城市的名称,如武汉市,IP地址则相当于邮局内部的编码,如420000,而域名解析就是将域名转换为IP地址的过程。
1、域名规则
英文域名只能由26个英文字母、0~9十个数字以及“-”连字符号混合而成(除了“-”不能是第一个字符),不支持使用空格及一些特殊字符,比如!?/;:@#$%^~_=+,*<>等。
英文域名不区分大小写,也可以是纯英文和数字域名,对于中文域名而言,则必须含有中文字符。
域名级数是从右至左按照“.”分隔的部分确定的,有几个“.”就是几级,一般情况下,域名最好不超过五级,例如a.com是一级域名,而a.b.com则是二级域名。
每一级域名长度的限制是63个字符,域名总长度则不能超过253个字符。
常见的通用顶级域名为:.biz .com .edu .gov .info .int .mil .name .net .org。
国家顶级域名参照ISO 3166-1中的双字母代码生成,例如中国大陆为.cn,中国香港为.hk,中国台湾为.tw,美国为.us。
通用域名可以组合国家域名,标明所在地区(只要域名管理机构允许),例如.gov.cn。
2、域名解析类型
A记录解析
A记录就是Address记录,是用来指定域名对应的IP地址,通常是将网站服务指向服务器地址,例如将域名www.csdn.net指向39.106.226.142这个IP地址,就是一个典型的A记录解析。
CNAME记录解析
如果服务器的地址发生变动,光靠A记录就不行了。这时候就需要用到CNAME,它又叫别名解析,例如域名www.csdn.net,真实的IP地址为39.106.226.142,对应的CNAME可能是abc.csdnweb.com,也就是允许多个域名对应服务器的主机名,这样即使服务器的IP地址发生变更,也不用更改解析记录,域名解析会自动依据主机名更新IP地址。如果A记录解析和CNAME记录解析并存,那么A记录解析将优先生效。
MX记录解析
即邮件交换记录,这种记录解析用于将以域名为结尾的电子邮件指向对应的邮件服务器,例如用户所用的邮件以csdn.net为结尾,那么就需要在域名管理中添加该域名的MX记录来处理所有以@csdn.net为结尾的邮件。
3、泛域名解析
是指将某一类域名解析到同一个IP地址,以通配符的方式实现,例如将*.csdn.net的泛域名指向IP地址39.106.226.142时,那么a.csdn.net、b.csdn.net等所有以csdn.net结尾的域名都会指向39.106.226.142这个IP。
常用网络命令和端口
工程师天天使用计算机做软件开发,有时候出了问题需要确定到底是自己的问题,还是网络的问题。所以学习并了解一些常见的计算机命令和开发中常用的端口,对开发工作会有很多实际的帮助。
1、常用网络命令
ping命令
这是在开发中使用频率极高的一个命令,主要用于确定网络的连通性,例如很多刚刚安装操作系统的计算机,第一件事就是先看看是否能联网,所以往往执行的第一条命令就是ping命令。它的格式是:ping 主机名/域名/IP地址。
ipconfig/ifconfig命令
当使用不带任何参数选项ipconfig/ifconfig命令时,显示每个已经配置了的接口的IP地址、子网掩码和缺省网关值。其中在Windows中使用的是ipconfig,而在Mac或Linux系统中,使用的是ifconfig。

netstat命令
能够显示活动的TCP连接、计算机侦听的端口、以太网统计信息、IP路由表、IPv4以及IPv6统计信息,通过它可以了解网络当前的状态。
2、常用网络端口
TCP与UDP段结构中端口范围在0~65535之间。
-
端口号小于256的是常用端口,服务器一般都是通过常用端口号来识别的。
-
任何TCP/IP实现所提供的服务都用0~1023之间的端口号。
-
1024~49151端口号是被注册的端口号,可以由用户自由使用,也是被IANA指定为特殊服务使用,从49152~65535是动态或私有端口号(以上并不是强制的)。
| 端口 | 服务/协议 | 说明 | 端口 |
|---|---|---|---|
| 21 | FTP | FTP服务器所开放的端口,用于上传、下载 | 21 |
| 22 | SSH | SSH连接 | 22 |
| 23 | Telnet | 远程登录服务 | 23 |
| 25 | SMTP | SMTP服务器所开放的端口,用于发送邮件 | 25 |
| 80 | HTTP | HTTP协议默认端口号 | 80 |
| 110 | POP3 | 邮局协议端口号 | 110 |
| 161 | SNMP | 网络管理协议端口号 | 161 |
| 443 | HTTPS | HTTPS协议默认端口号 | 443 |
| 8080 | WWW代理 | 一般的网站服务会开放此端口 | 8080 |
数据结构常识
更多内容: 我对八种常见数据结构的理解
数据结构是计算机存储、组织数据的方式,它研究的是如何构造复杂软件系统的根基,它的核心内涵是分解与抽象,并得到软件开发过程中需要用到的逻辑结构。用简单直白的话来说,就是同样的数据,在某些场景下,用数组会比用链表好,而在另一些场景下,可能用栈(一种可以实现「后进先出」的线性表)就是最合理的了。
数组(Array)
它是将具有相同类型的若干数据组织在一起的集合,这是一种最基本而且也是一种最经常使用的数据结构。
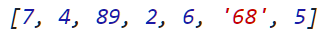
栈(Stack)
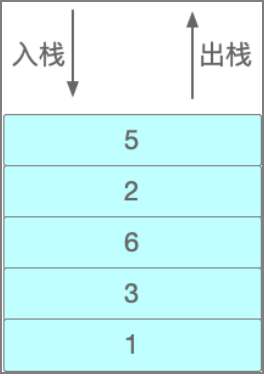
一种特殊的线性表,只能在一个表的固定端进行数据节点的插入和删除操作,栈正是一种按照后进先出(LIFO)的原则来存储数据的数据结构。
队列(Queue)
队列和栈类似,但不同的是,它是在一端执行入队操作,另一端进行出队操作。
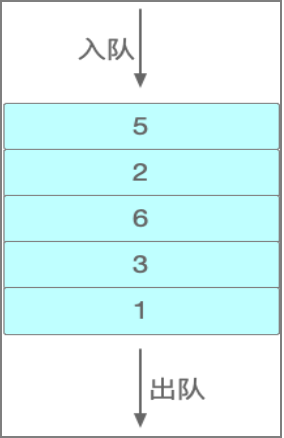
链表(Linked List)
它和数组一样,也是一组数据的集合,但和数组不一样的是,它并不是一组连续的数据集合,而是通过指针连接在一起的。

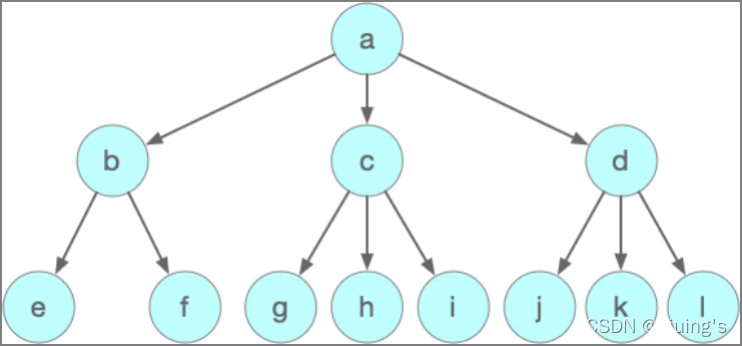
树(Tree)
这是一种典型的非线性结构,之所以叫做“树”,是因为它的结构看起来就像一颗倒过来的树,它只有一个根结点,但可以有多个后继节点。
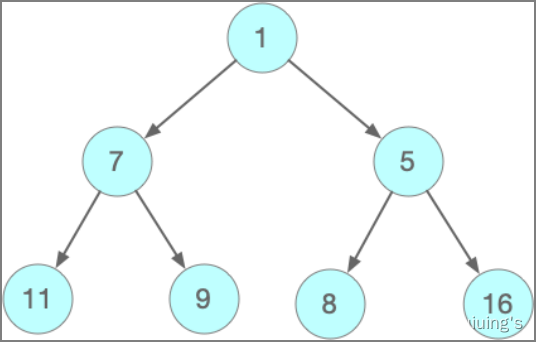
堆(Heap)
它是一种特殊的树型结构,它的特点是根结点的值是所有节点中最大或者最小的,而且根结点的子节点也是一个堆结构。
最小堆
最大堆

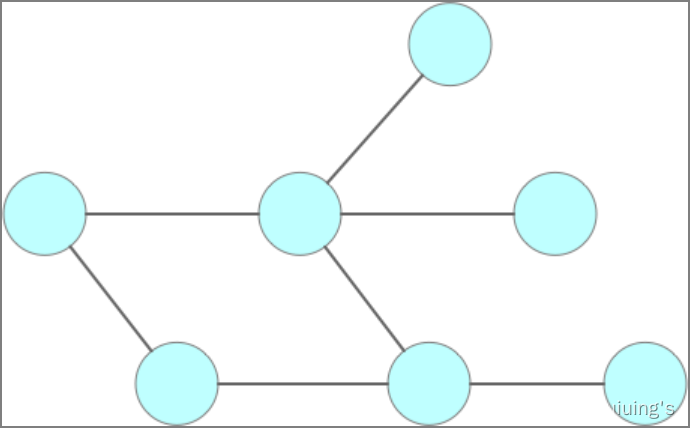
图(Graph)
也是一种非线性数据结构,在图结构中,数据节点称为顶点,顶点之间的连线称为边。
有向图
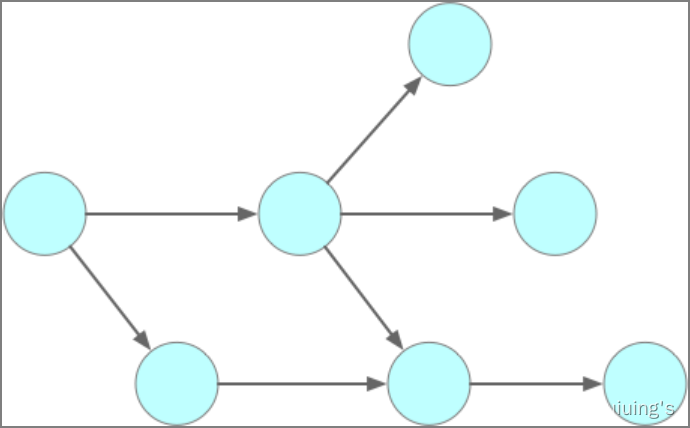
无向图
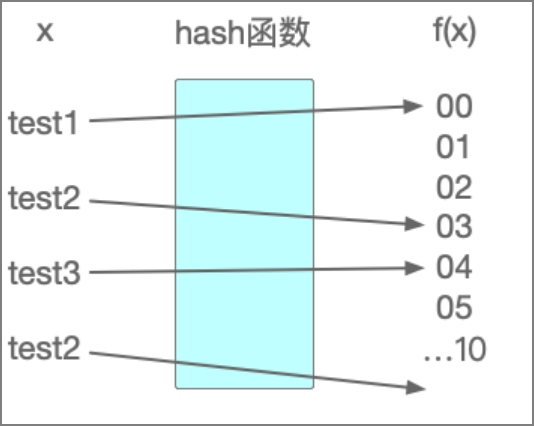
散列表(Hash)
这种数据结构来源于散列函数,它的思想是如果存在x,那么就必然有一个唯一的存储位置f(x)可以找到x,这样通过数学函数就直接计算出x的存储位置而不用在进行比较、查找以后才知道。
算法常识
算法(Algorithm)是对方案的一种描述,对于计算机来说,它是一系列解决问题的计算步骤。算法的意义在于,在各种不同的解决方法之中,找到那个效率最高的
1、查找算法
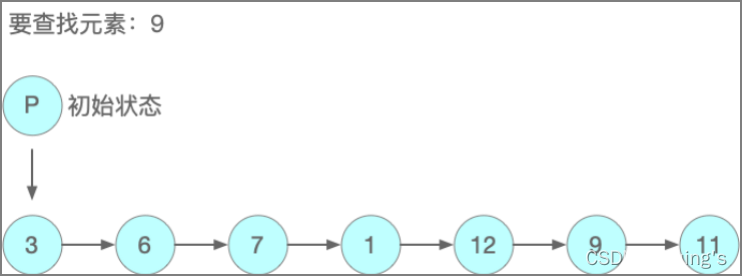
顺序查找
它的基本思想就是从第一个元素开始,按顺序遍历待查找序列,直到找出给定目标或者查找失败,其过程如下图所示。
顺序查找初始状态
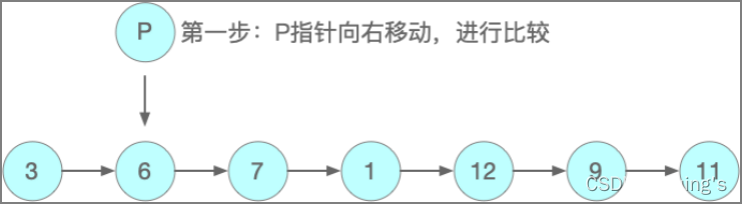
指针逐步向右移动,逐一比较每个元素
逐一查找,直到完成匹配

二分查找
又叫折半查找,它要求列表必须是有序的。它的原理是每次都把待比较元素A和列表中间的元素B进行比较,如果A小于B,那么A再和位于B前半部分的元素进行比较,并且再次选择中间元素进行比较,直到比较完所有元素为止。
二分查找初次比较:中间元素为7

第二次比较:目标元素小于7,7的后半部分抛弃,直接从前半部分开始
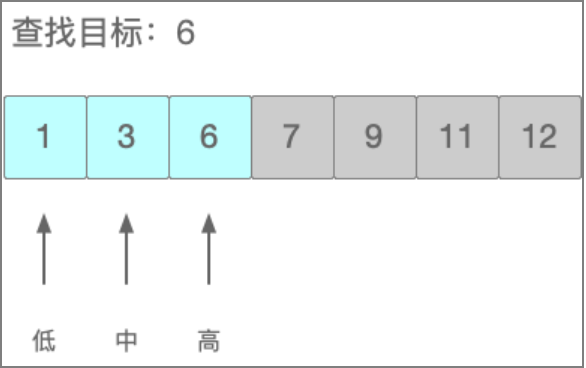
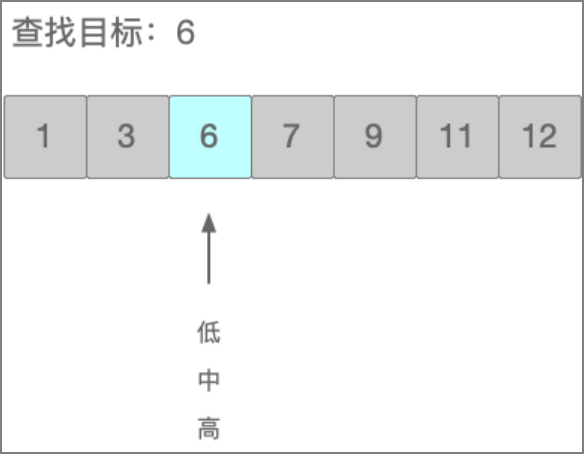
第三次比较:目标元素大于3,3的前半部分抛弃,直接从后半部分开始,直接得到最后一个元素6,就是要查找的目标元素
2、排序算法
更多内容: 十大经典排序算法的总结
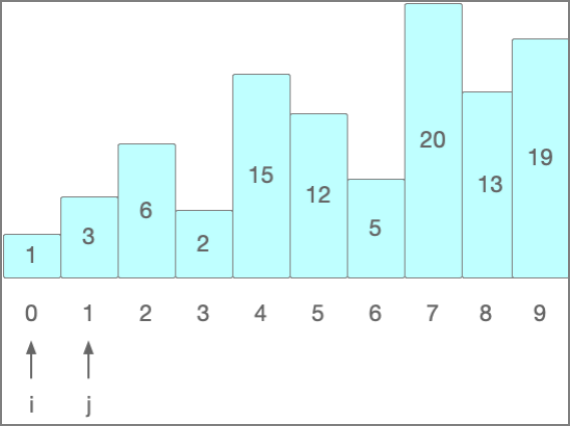
冒泡排序
它重复地走访过要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越小(大)的元素会经由交换慢慢“浮”到数列的顶端。
冒泡排序初始阶段
按倒序排列,那么交换i和j的位置,并且两者的位置继续前移
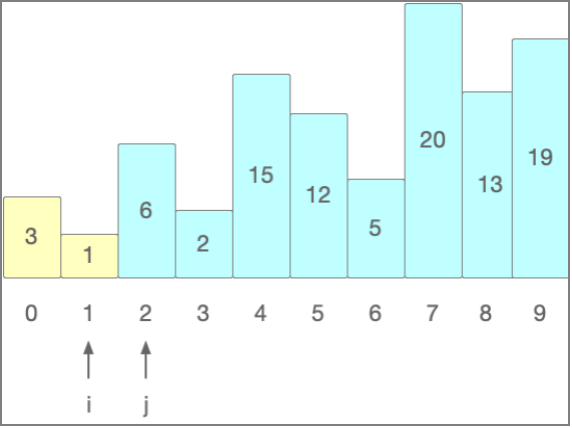
实现1和6的交换,直到完成第一遍排序
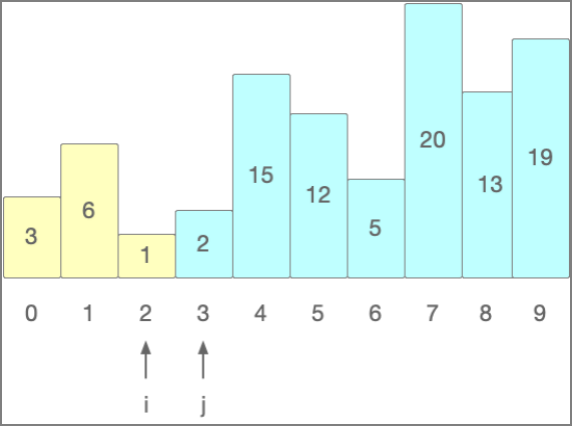
完成第一遍排序之后,再次回到起始位置,再将刚才的过程执行一遍,直到所有元素都按要求实现排序
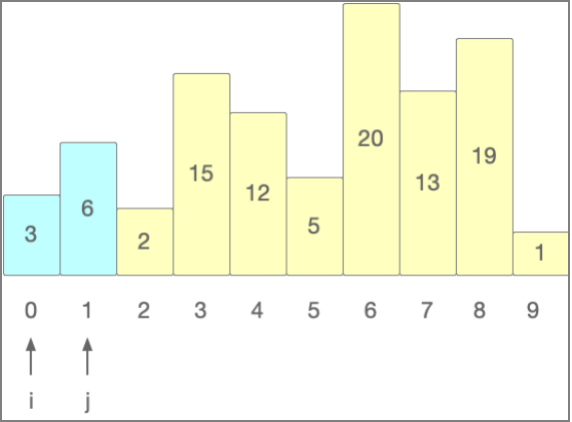
选择排序
是一种简单直观的排序算法。它的工作原理是:首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
先将i放在第一个,然后在后续元素中找是否还有比它更小的

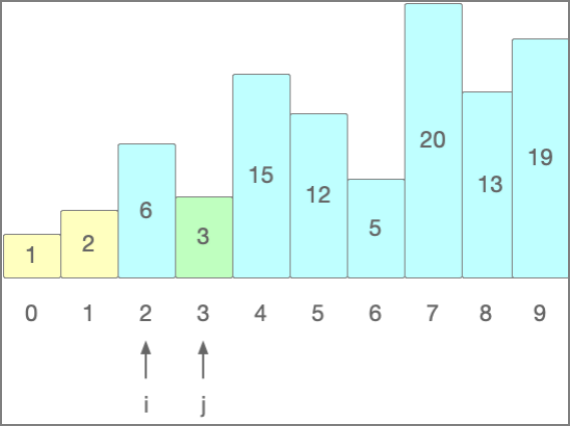
发现没有比1更小的元素,再从第二个开始往后寻找最小的元素

发现2比3小,交换2和3的位置,然后继续比较后面的元素,依次执行,直到完成所有元素的比较与排序

















 2112
2112











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











