






什么是索引
在现实生活中,我们经常去图书馆查阅图书。
现在我们将所有图书杂乱无章的摆放在一起,那么找一本书就像大海捞针一样效率非常低。
如果我们按分类整理排序后,根据类别去找对应的图书那么效率就很高了。其实这个过程就是在建立索
引。
查看mysql中语句执行效率
show variables like '%query%' ;
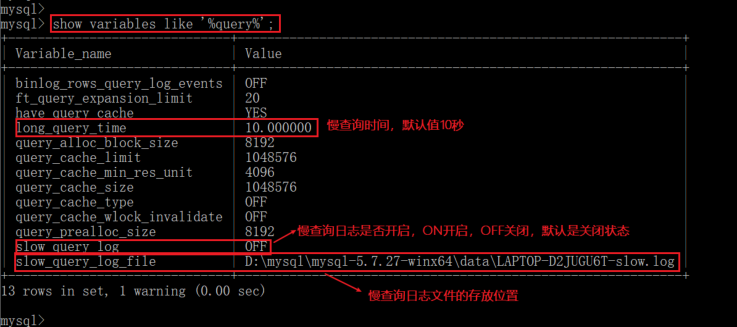
查询当前的慢日志状态 其中long_query_time表示执行时间比较。
长的记录 slow_query_log=off 表示慢日志为关闭状态。
slow_query_log_file 表示慢日志存储的位置。
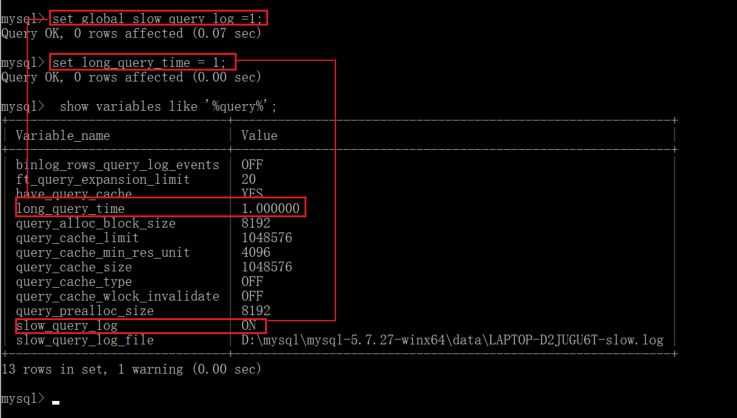
--打开 慢日志查询
set global slow_query_log =1;--设置需要记录的比较慢的sql时间
set long_query_time = 1;
select * from temp_table where id like '%91b4a3ac2edb6f9064d18a8fb286edf9';

超过了一秒的语句可以去相应的目录下看log文件
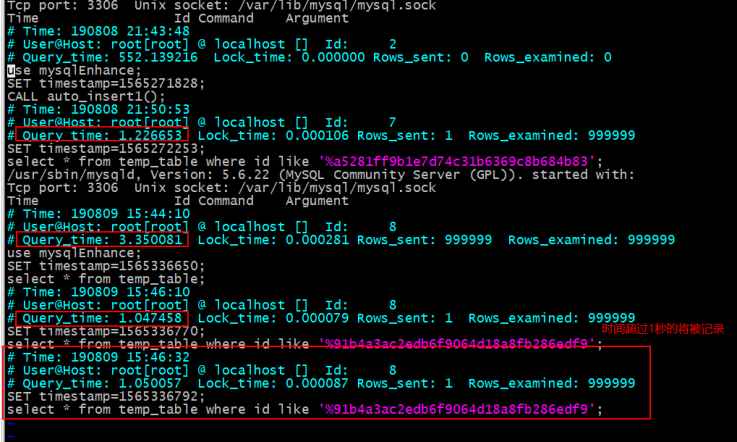
query_time:查询时间
lock_time:锁时间
rows_sent:返回条数
rows_examined:扫描行数
索引的优势与劣势
优势
① 类似大学图书馆建书目索引,提高数据检索的效率,降低数据库的 IO 成本。
② 通过索引列对数据
进行排序,降低数据排序的成本,降低 CPU 的消耗。
劣势
① 实际上索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录,所以索引列也是要占用
空间的
② 虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和
DELETE操作 , MySQL不仅要保存数据,还要更新一下索引文件 , 理论上来说 , 频繁的更新索引字段的数
据 , 表的更新效率会下降
MySQL索引分类
普通索引:仅加速查询
唯一索引:加速查询 + 列值唯一(可以有null) 唯一约束
主键索引:加速查询 + 列值唯一(不可以有null)+ 表中只有一个 , 主键约束
组合(联合)索引:多列值组成一个索引,注意:最左匹配原则(一会演示)
全文索引:了解(es)
hash索引:了解(key-value 查询速度非常高效)
--创建索引
① 直接创建(普通、唯一)
--创建普通索引
create index 索引名 on表名(列名);--创建唯一索引
create unique index 索引名 on表名(列名);--创建普通组合索引
create index 索引名 on表名(列名1,列名2....);--创建唯一组合索引
create unique index 索引名 on 表名(列名1,列名2...);
② 修改表时指定
--添加一个主键,这意味着索引值必须是唯一的,且不能为NULL
alter table 表名 add primary key(id);--添加唯一索引(除了NULL外,NULL可能会出现多次)
alter table 表名 add unique(列名); --索引名就是列名--添加普通索引,索引值可以出现多次。
alter table 表名 add index(列名);--索引名就是列名
③ 创建表时指定
create tablexxx(
idint,
usernamevarchar(32),
ageint,primary key(id), --主键
unique(username), --唯一
index(age) --普通
);
--删除索引
--直接删除
drop index 索引名 on表名;--修改表时删除
alter table 表名 drop index 索引名;
索引创建原则
1. 字段内数据的辨识度不能低于70%
字段内数据唯一值的个数不能低于70%,例如:一个表数据只有50行,那么性别和年龄哪个字段适
合创建索引,明显是年龄,因为年龄的唯一值个数比较多,性别只有两个选项
2. 在经常需要 搜索 的列上建索引,这样会大大加快查找速度,经常使用 where 查询字段。
3. 在经常需要 连接 的列上建索引,可以加快连接的速度,经常使用 多表连接字段(主外键) 内连接 | 外连接。
4. 在经常需要 排序 的列上建索引,因为索引已经是排过序的,这样一来可以利用索引的排序,加快排序查询速度,经常使用 group by having | order by 字段。
* 注意:
那是不是在数据库表字段中尽量多建索引呢?肯定是不是的。因为索引的建立和维护都是需要耗时的
创建表时需要通过数据库去维护索引,添加记录、更新、修改时,也需要更新索引,会间接影响数据库的
效率。
常见索引失效情况
--1.使用like模糊匹配,%通配符在最左侧使用时
select * from user where username like '%jack88';--2.尽量避免使用or,如果条件有一个没有索引,那么会进行全表扫描
select * from user where id = 1 or sex ='male';--3.在索引列上进行计算
select * from user where id + 1 = 2;--4.使用 !=、 not in、is not null时
select * from user where sex != 'male';select * from user where id not in( 1, 3 ,5);
索引的数据结构
我们知道索引是帮助MySQL高效获取排好序的数据结构。
索引= 排序后的数据结构
为什么使用索引后查询效率提高很多呢?接下来我们来了解下。
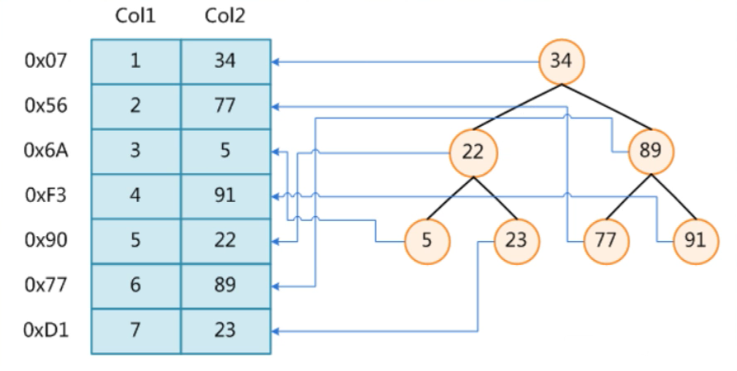
在没有索引的情况下我们执行一条sql语句,那么是表进行全局遍历,磁盘寻址(注意逻辑上相邻的记录在磁盘上也并不是一定物理相邻的)
为了加快的查找效率,可以维护一个右边所示的二叉查找树,每个节点分别包含索引键值和一个指向对
应数据记录物理地址的指针,这样就可以运用二叉查找快速获取到相应数据。
1. 二叉树 左边子节点比父节点小,右边子节点比父节点大2. 红黑树(平衡二叉树) 左旋和右旋实现自平衡3. Hash 散列1. JDK1.7 (数组+链表)2. JDK1.8 (数组+红黑树) 如果链表长度《=8
4. B-Tree (多路搜索平衡树)5. B+Tree【MySQL使用】
数据库存储引擎
--MyISAM(非聚集索引)
MySQL5.5版本之前默认的存储引擎,不支持事务。
CREATE TABLEmyisam_tab(
idINT,
usernameVARCHAR(32)
)ENGINE= MYISAM;
使用这个存储引擎,每个MyISAM在磁盘上存储成三个文件。
(1)frm文件:存储表的定义数据
(2)MYD文件:存放表具体记录的数据
(3)MYI文件:存储索引

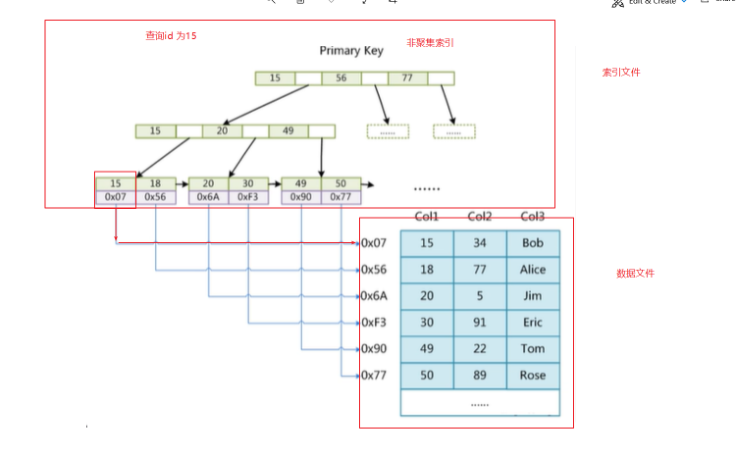
frm和MYI可以存放在不同的目录下。MYI文件用来存储索引,但仅保存记录所在页的指针,索引的结构是B+树结构。下面这张图就是MYI文件保存的机制:
--InnoDB(聚集索引)
MySQL5.5版本之后默认的存储引擎,支持事务,有自动增长,支持外键约束,支持缓冲区
CREATE TABLEinnodb_tab(
idINT,
usernameVARCHAR(32)
)ENGINE= INNODB;
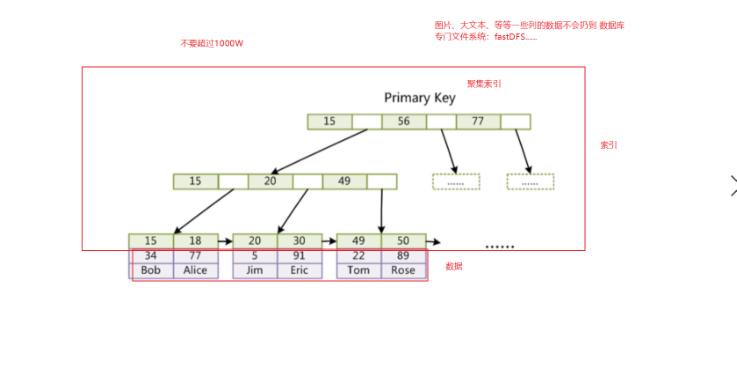
InnoDB的存储表和索引也有下面两种形式:
(1)使用共享表空间存储:所有的表和索引存放在同一个表空间中。
(2)使用多表空间存储:表结构放在frm文件,数据和索引放在IBD文件中。分区表的话,每个分区对应单独的IBD文件,分区表的定义可以查看我的其他文章。使用分区表的好处在于提升查询效率。
对于InnoDB来说,最大的特点在于支持事务。但是这是以损失效率来换取的。















 1434
1434











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









