







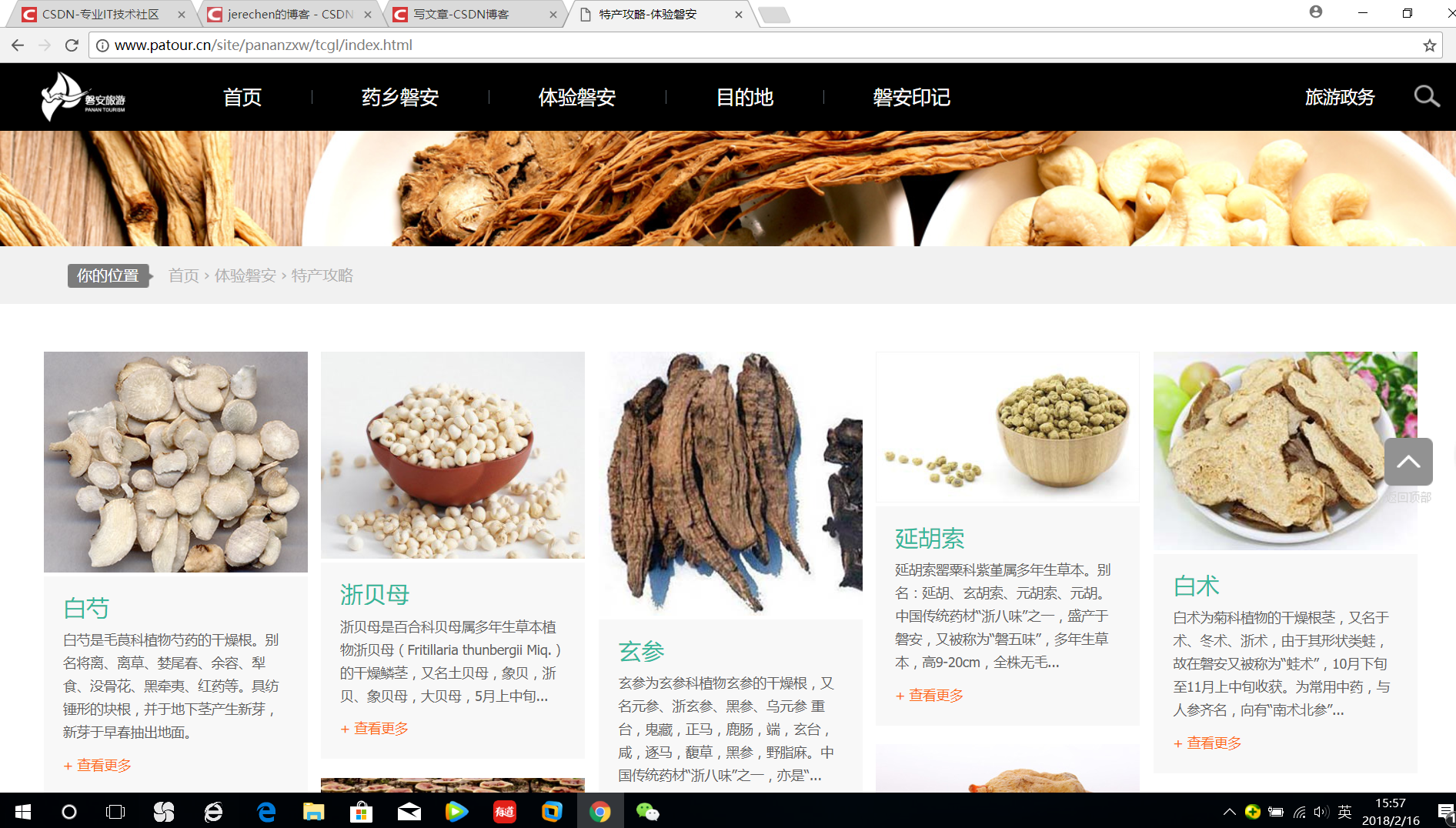
 还是老家的旅游网址:http://www.patour.cn/site/pananzxw/tcgl/index.html,将这些特产的图片及其介绍都爬取下来!
还是老家的旅游网址:http://www.patour.cn/site/pananzxw/tcgl/index.html,将这些特产的图片及其介绍都爬取下来!
源码:
1 # -*- coding:utf-8 -*-
2 import urllib2
3 import re
4 from lxml import etree
5
6 class Spider:
7 def __init__(self):
8 pass
9 def loadPage(self):
10 #将网页的源码爬取下来
11 url = 'http://www.patour.cn/site/pananzxw/tcgl/index.html'
12 headers ={"User-Agent":"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:45.0) Gecko/20100101 Firefox/45.0"}
13 request = urllib2.Request(url,headers=headers)
14 response = urllib2.urlopen(request)
15 html = response.read()
16 self.getfullUrl(html)
17 #print html
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3364
3364











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









