








1 前言
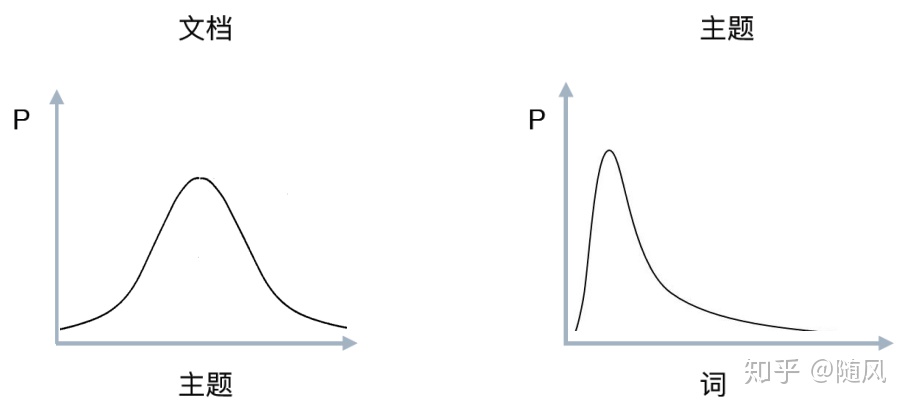
在我们阅读一篇文章的时候,需要明确文章的类别(体育类、新闻类)、内容以及中心思想。通常情况下,一篇文章可能包含多个主题,比如在介绍一座城市的时候,可能会从历史、经济、政治、教育、交通等多个方面做介绍。LDA 正是一种自动分析每篇文档,统计文档中的词语,根据统计的信息判断文档包含哪些主题以及各个主题所占比例的模型。
由于 LDA 的实现原理牵扯到一些数学知识,因此想彻底搞懂 LDA ,请先参看 LDA 的数学基础篇:
随风:自然语言处理(2)主题模型 LDA (1 数学基础篇)zhuanlan.zhihu.com
语言:python3
数据集:http://eventregistry.org/ (实时新闻数据)
2 什么是主题模型?
主题模型(Topic Model)是通过学习一系列的文档,发现抽象主题的一种统计模型。从词频的角度来讲,如果一篇文章包含某个主题,那么一定存在一些特定的词语会频繁出现。通常情况下,一篇文章中包含多个主题,而且每个主题所占的比例各不相同。
比如:“美国对伊朗再度实施单边制裁,这将对伊朗的出口贸易造成严重影响”。这里可以归为政治主题,因为描述国家的词语频繁出现。也可以归为经济主题,因为出现了制裁、出口贸易等词。我们可以预估一下,政治主题的比例为 0.7,经济主题的比例为 0.3。
主题模型是对文本中隐含主题的一种建模方法,每个主题其实是词表上词语的概率分布。主题模型是一种生成模型,一篇文章中每个词都是通过“以一定概率选择某个主题,并从这个主题中以一定概率选择某个词语”这样一个过程得到的。
比如,我们写文章一般先选定一个主题,然后用和这个主题有关的词语进行组合形成文章。
3 LDA 主题模型直观认识
隐含狄利克雷分布(Latent Dirichlet Allocation,简称 LDA),是一种概率主题模型。LDA可以将文档集中每篇文档的主题以概率分布的形式给出,通过分析一批文档集,抽取出它们的主题分布,就可以根据主题分布进行主题聚类或文本分类。同时,它是一种典型的词袋模型,即一篇文档是由一组词构成,词与词之间没有先后顺序关系。此外,一篇文档可以包含多个主题,文档中每个词都由其中的一个主题生成。
LDA 是一种无监督学习方法,在训练时不需要手工标注的训练集,需要的仅仅是文档集以及指定主题的数量 k 即可。此外,LDA 的另一个优点是,对于每一个主题均可找出一些词语来描述它。
一篇文章的每个词都是以一定概率选择某个主题,并从这个主题中以一定概率选择某个词语而组成的。用公式表示为:
从公式来看,
对语料库中的每篇文档,LDA 定义了如下生成过程(generative process):
令 w 表示词语,d 表示文档,t 表示主题;小写代表个体,大写代表集合。D 中每篇文档 d 看作一个词语序列
- 对 D 中的每一篇文档 d,对应到不同主题的概率
。其中,
表示对应 T 中第 i 个主题的概率。计算方法是
,其中
表示 d 中对应第 i 个主题的词语的数量,n 表示 d 中所有词语的总数。
- 对 T 中的每一个主题 t,生成不同词语的概率
。其中,
表示 t生成 V 中第 i 个词语的概率。计算方法是
,其中
表示对应到 t 的 V 中第 i 个词语在语料库(所有文档)中的数量,n 表示语料库中所有对应到 t 的词语总数。
LDA 的核心公式为:
4 LDA 主题模型
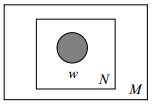
4.1 Unigram model
对于文档
其图模型为(图中被涂色的 w 表示可观测变量,N 表示一篇文档中总共 N 个词语,M 表示 M篇文档):
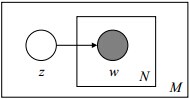
4.2 Mixture of unigrams model
该模型的生成过程是:给某个文档先选择一个主题,再根据该主题生成文档,该文档中的所有词都来自一个主题。假设主题有
其图模型为(图中被涂色的 w 表示可观测变量,未被涂色的 z 表示未知的隐变量,N 表示一篇文档中总共 N 个单词,M 表示 M 篇文档):
4.3 PLSA model
PLSA 模型是最接近 LDA 模型的,所以理解 PLSA 模型有助于我们理解 LDA 模型。
(1)PLSA 模型下生成文档过程
在上面的 Mixture of unigrams model 中,我们假定一篇文档只有一个主题生成,可实际中,一篇文章往往有多个主题,只是这多个主题各自在文档中出现的概率大小不一样。比如介绍一个国家的文档中,往往会分别从教育、经济、交通等多个主题进行介绍。那么在 PLSA 中,文档是怎样被生成的呢?
假设你要写 M 篇文档,由于一篇文档由各个不同的词组成,所以你需要确定每篇文档里每个位置上的词。
再假定你一共有 K 个可选的主题,有 V 个可选的词,咱们来玩一个扔骰子的游戏。
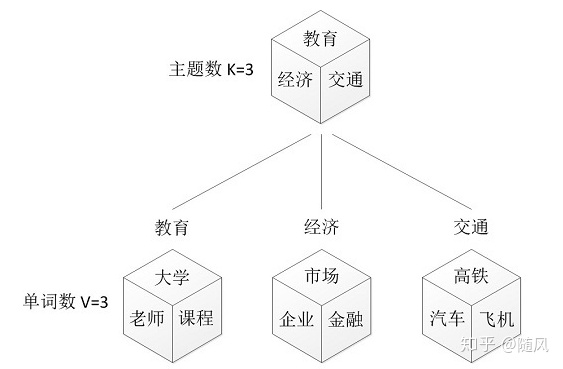
第一步:假设你每写一篇文档会制作一颗 K 面的“文档-主题”骰子(扔此骰子能得到 K 个主题中的任意一个),和 K 个 V 面的“主题-词项” 骰子(每个骰子对应一个主题,K 个骰子对应之前的 K个主题,且骰子的每一面对应要选择的词,V 个面对应着 V 个可选的词)。
比如可令 K=3,即制作 1 个含有 3 个主题的“文档-主题”骰子,这 3 个主题可以是:教育、经济、交通。然后令 V = 3,制作 3 个有着 3 面的“主题-词项”骰子,其中,教育主题骰子的3 个面上的词可以是:大学、老师、课程,经济主题骰子的 3 个面上的词可以是:市场、企业、金融,交通主题骰子的 3 个面上的词可以是:高铁、汽车、飞机。
第二步:每写一个词,先扔该“文档-主题”骰子选择主题,得到主题的结果后,使用和主题结果对应的那颗“主题-词项”骰子,扔该骰子选择要写的词。
先扔“文档-主题”的骰子,假设(以一定的概率)得到的主题是:教育,所以下一步便是扔教育主题筛子,(以一定的概率)得到教育主题筛子对应的某个词:大学。
上面这个投骰子产生词的过程简化一下便是:“先以一定的概率选取主题,再以一定的概率选取词”。事实上,一开始可供选择的主题有 3 个:教育、经济、交通,那为何偏偏选取教育这个主题呢?其实是随机选取的,只是这个随机遵循一定的概率分布。比如可能选取教育主题的概率是 0.5,选取经济主题的概率是 0.3,选取交通主题的概率是 0.2,那么这 3 个主题的概率分布便是 {教育:0.5,经济:0.3,交通:0.2},我们把各个主题 z 在文档 d 中出现的概率分布称之为主题分布,且是一个多项分布(因为主题分布是 n 次掷筛子产生的)。
同样的,从主题分布中随机抽取出教育主题后,依然面对着 3 个词:大学、老师、课程,这 3个词都可能被选中,但它们被选中的概率也是不一样的。比如大学这个词被选中的概率是 0.5,老师这个词被选中的概率是 0.3,课程被选中的概率是 0.2,那么这 3 个词的概率分布便是 {大学:0.5,老师:0.3,课程:0.2},我们把各个词语 w 在主题 z 下出现的概率分布称之为词分布,这个词分布也是一个多项分布(因为词分布是 n 次掷筛子产生的)。
所以,选主题和选词都是两个随机的过程,先从主题分布{教育:0.5,经济:0.3,交通:0.2}中抽取出主题:教育,然后从该教育主题对应的词分布{大学:0.5,老师:0.3,课程:0.2}中抽取出词:大学。
第三步:最后,你不停的重复扔“文档-主题”骰子和”主题-词项“骰子,重复 N 次(产生 N个词),完成一篇文档,重复这产生一篇文档的方法 M 次,则完成 M 篇文档。
上述过程抽象出来即是 PLSA 的文档生成模型。在这个过程中,我们并未关注词和词之间的出现顺序,所以 PLSA 是一种词袋方法。定义:
-
表示海量文档中某篇文档被选中的概率。
-
表示词
在给定文档
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









