







让你彻底搞明白YARN资源分配
本篇要解决的问题是:
Container是以什么形式运行的?是单独的JVM进程吗?
YARN的vcore和本机的CPU核数关系?每个Container能够使用的物理内存和虚拟内存是多少?
一个NodeManager可以分配多少个Container?
一个Container可以分配的最小内存是多少?最大内存内存是多少?以及最小、最大的VCore是多少?
当将Spark程序部署在YARN上, AM与Driver的关系是什么?
Spark on YARN,一个Container可以运行几个executor?executor设置的内存和container的关系是什么?
1
YARN资源管理简述
分布式应用在YARN中的执行流程
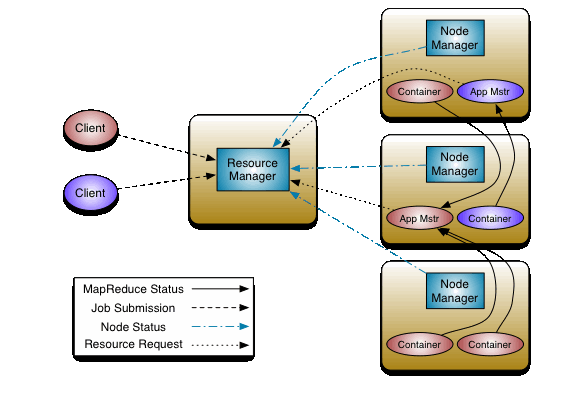
这张图是YARN的经典任务执行流程图。可以发现上图中有5类角色:
Client
Resource Manager
Node Manager
Application Master
Container
先简单来梳理提交任务的流程。
要将应用程序(MapReduce/Spark/Flink)程序运行在YARN集群上,先得有一个用于将任务提交到作业的客户端,也就是client。它向Resource Manager(RM)发起请求,RM会为提交的作业生成一个JOB ID。此时,JOB的状态是:NEW
客户端继续将JOB的详细信息提交给RM,RM将作业的详细信息保存。此时,JOB的状态是:SUBMIT
RM继续将作业信息提交给scheduler(调度器),调度器会检查client的权限,并检查要运行Application Master(AM)对应的queue(默认:default queue)是否有足够的资源。此时,JOB的状态是ACCEPT。
接下来RM开始为要运行AM的Container资源,并在Container上启动AM。此时,JOB的状态是RUNNING
AM启动成功后,开始与RM协调,并向RM申请要运行程序的资源,并定期检查状态。
如果JOB按照预期完成。此时,JOB的状态为FINISHED。如果运行过程中出现故障,此时,JOB的状态为FAILED。如果客户端主动kill掉作业,此时,JOB的状态为KILLED。
2
YARN集群资源管理
a
集群总计资源
要想知道YARN集群上一共有多少资源很容易,我们通过YARN的web
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5966
5966











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









