






从网页中获取大段文章时,常常是先获取整个文本处的html标签使用正则处理,但是正则往往只能去除比较规范的前端标签,对于不规范的标签,往往需要多次处理,比较麻烦。
在python中有些库可以实现解决此类问题。
from lxml.html.clean import clean_html
from scrapy.selector import Selector
import requests
if __name__ == '__main__':
res = requests.get('http://baijiahao.baidu.com/s?id=1645248735989537091')
response = Selector(text=res.text)
html = response.xpath('//div[@class="article-content"]').extract()
new_html = clean_html("".join(html) + '
print(new_html)
以上代码是取一个网页中的文本处所有div,并额外加入了以及格式不规范的html标签,输出结果如下:

script标签被去除,html标签被补全,clean_html()的作用就是如此。
若想得到格式完整的文本,可以使用remove_tags(text, which_ones=(), keep=(), encoding=None)方法,其中which_onesyua元组。说明
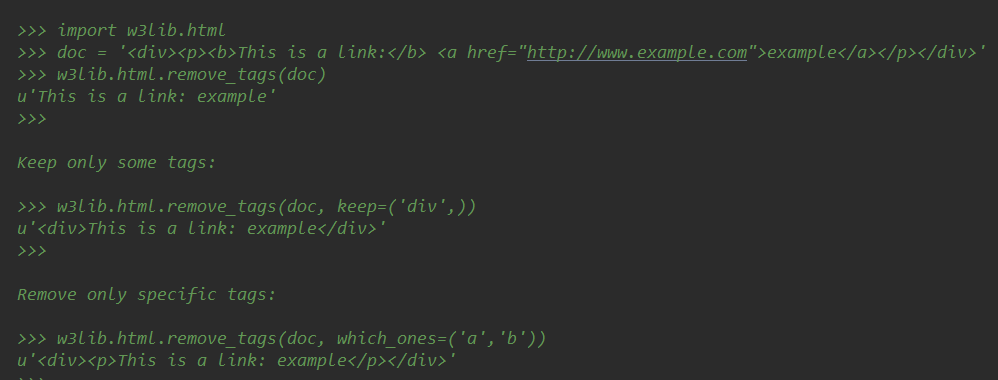
但是你不可以同时使用which_ones和keep,否则就抛出断言
AssertionError: which_ones and keep can not be given at the same time
text = remove_tags(new_html)
print(text)















 412
412











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









