






段丞博:使用Pandas处理excel文件-(1)动机和资源
段丞博:使用Pandas处理excel文件-(2)DataFrame和相关概念
段丞博:使用Pandas处理excel文件-(3)从Python默认数据类型中产生DataFrame
段丞博:使用Pandas处理excel文件-(4)读写excel表格
段丞博:使用Pandas处理excel文件-(5)访问DataFrame中的数据
段丞博:使用Pandas处理excel文件-(6)筛选DataFrame中满足特定条件的数据
段丞博:使用Pandas处理excel文件-(7)删除、增添行列或标签
段丞博:使用Pandas处理excel文件-(8)pandas中处理日期的四种基本数据类型介绍
段丞博:使用Pandas处理excel文件-(9)日期的处理
段丞博:使用Pandas处理excel文件-(10)数据处理
对于excel表格的操作中,增添删减、修改内容是基本的功能,这次介绍一下如何对于DataFrame进行相同的操作。假设有如下的表格内容:
删除行列
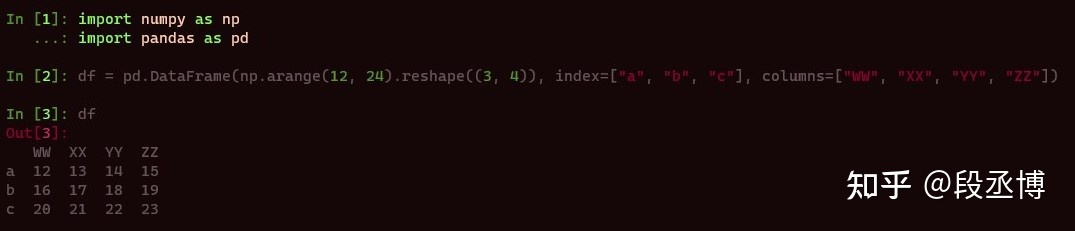
如果要删除某些行列,可以用drop函数实现。drop函数的接口如下:
drop(labels=None, axis=0, index=None, columns=None, inplace=False) - label:字符串或者是字符串构成的列表,代表要删除的行或者列的标签,具体行列由axis指定
- axis: 如果axis=0,label中的标签为index,否则为columns
- index/columns:也可直接用这两个参数指定删除的行列
- inplace: 是否修改原DataFrame,pandas默认情况下是不会修改原表格
为了说明该函数的用法,下面的图片中分别用两种方法删除表格中第二行和第三列。第一种利用labels和axis两个参数。
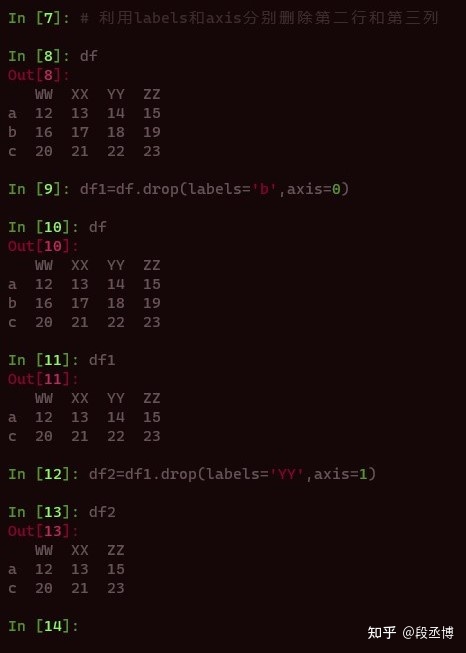
也可以利用index删除行,利用columns删除列。
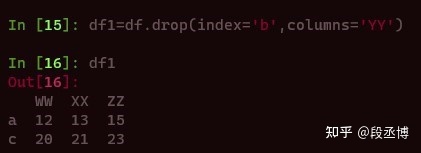
除了按照行列的标签名字删除,还有一种按照序号删除的方式。例如刚才删除'YY'列,相当于删除第三列(python计数中为2),因此也可以按下面的方式删除。
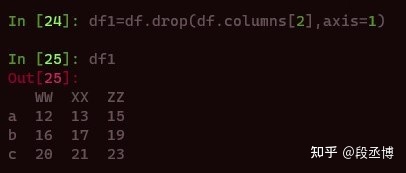
它的含义也是明确的,即使用df的columns的部分内容作为labels的参数输入。
如果要删除原表格中的行列,那么仅需要让inplace参数为True即可,当然也可以用del直接删除表格中的列并生效,如下。
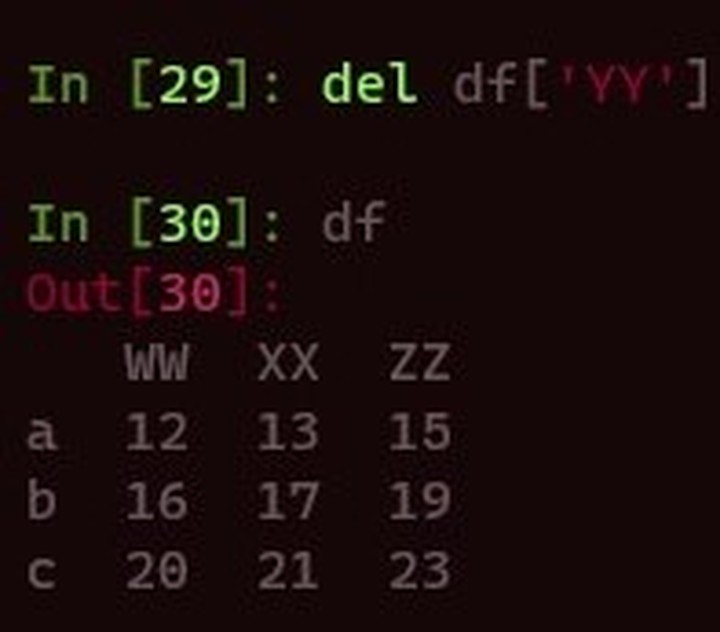
添加行列
首先看如何添加行,这里的“添加”就是在表格的末尾续上一行。一个正规的含义明确的操作是用append方法来实现。但是如果可以保证新添加的行标签并不在原来的表格中,那么也可以用loc、at、set_value来实现。不过需要注意的是,和删除操作不同,添加操作会直接修改原表格,以loc和at为列演示如下。
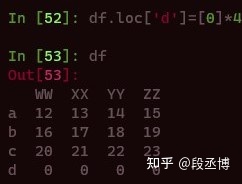

append的方法相对灵活,可以接收的参数类型比较多,用起来需要注意可能对表格带来的不可预期的改变,例如我们在表格后面可以追加一个列表。
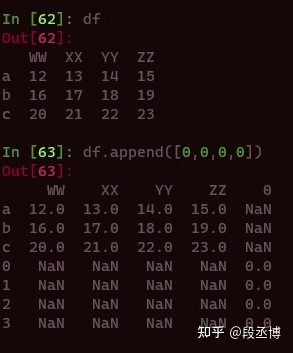
或者追加一个Series,
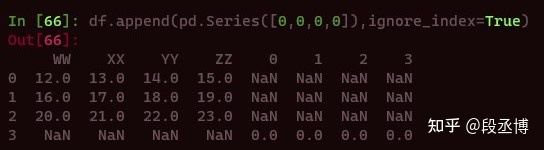
行为完全不一样,也并不是特别符合直觉,所以append函数是不会修改原来的表格的,使用时务必要仔细参考手册。这一点也是我非常不喜欢numpy和pandas中一些对我而言并不是自然的广播方式。
列的添加方式有两种,由于表格总是以列为主,所以可以像操作字典一样来添加列,即添加一个新的列标签即可。
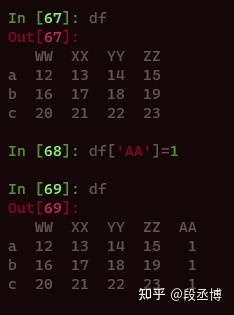
也可以使用loc或者at实现这样的效果。
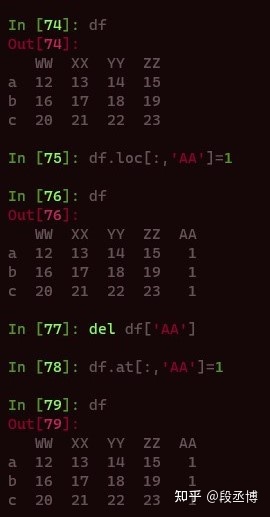
指定的位置添加列
在表格中新添加一行和新添加一列的含义是不同的,在指定的位置添加新的列比添加行的意义要大,因为行总是可以通过排序,索引重拍,其具体位置并没有特别的价值。在Pandas中,在指定的位置添加列用到insert函数,方法很简单如下。
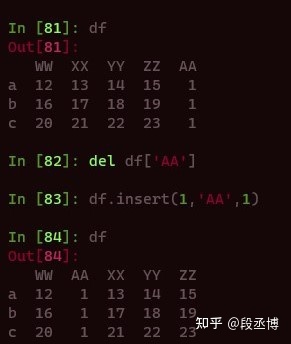
第一参数为插入的位置,第二个插入列的标签名,第三个为插入的内容。
修改行列标签
如果想给某一行或者列重新起一个名字,那么就可以用rename函数。rename函数有三个参数:
index: 修改行标签名字的参量,传递一个字典,字典的键为旧名,值为新名;
columns: 与上相同,修改列的名字;
inplace: 是否要修改原表格。
使用方法如下,例如把列中"YY"改为小写。

总结
Pandas中对于表格行列的操作也非常灵活,因此会存在一些隐患,特别是那些无意的操作,但是又不报错,特别是各类广播,使用需要谨慎小心。有数值处理经验的朋友一定知道,数值处理中的错误很多表现为数组的形状出现了问题,广播是一种非常灵活但是要谨慎的操作。















 662
662











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









