






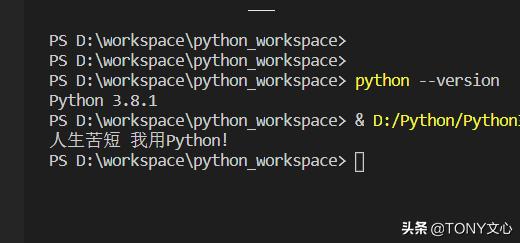
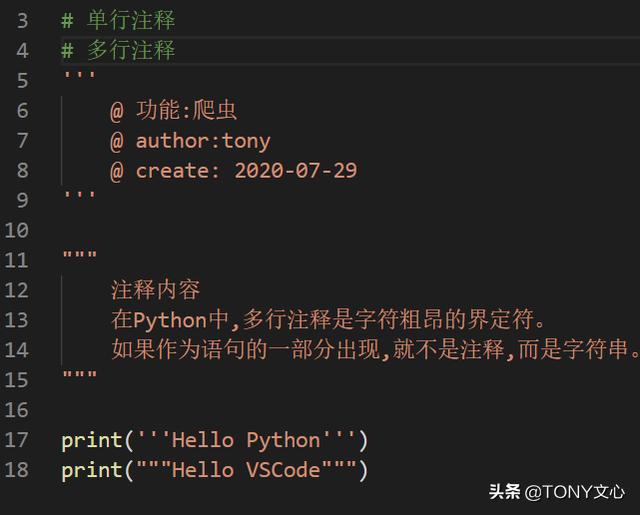
注释:
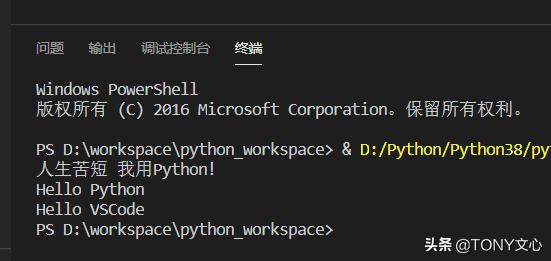
# 保留字 (区分大小写)import keywordprint(keyword.kwlist)
# type() 内置函数查看变量类型name = 'tony'print(""*10)print("name的类型:",type(name))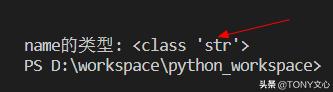
# id() 获取变量的内存地址age = 18print("%#x" %id(age))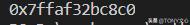
"""基本数据类型:1. 数字类型: (不可改变,修改了,会把值存放到内存中,然后修改变量让其指向新的内存地址) 包括: 整数、浮点数、复数2. 字符串类型: 连续的字符序列,在Python中,字符串属于不可变序列。 单引号(' ')、双引号(" ")、或三引号(''' '''/""" """)括起来 单引号和双引号中的字符序列必须在一行上,而三引号内的字符序列可以分布在连续的多行上!3. 布尔类型: True和False,可以转化为数值,True表示1,False表示0"""# 整数类型: 十进制整数、八进制整数(0o/0O开头)、十六进制整数(0x/0X开头)、二进制整数# 浮点数: 由整数部分和小数部分组成,主要用于处理包括小数的数。也可以使用科学计数法表示# 复数: 实部和虚部组成''' (常用)数据类型转换: int(x): 将x转换成整数类型 float(x): 将x转换成浮点数类型 complex(real,[,imag]): 创建一个复数 str(x): 将x转换为字符串 repr(x): 将x转换为表达式字符串 eval(x): 计算在字符串中的有效Python表达式,并返回一个对象 chr(x): 将整数x转换为一个字符 ord(x): 将一个字符x转换为它对应的整数值 hex(x): 将一个整数x转换为一个16进制的字符串 oct(x): 将一个整数x转换为一个8进制的字符串'''''' 运算符: 数学计算、比较大小、逻辑运算、赋值运算符、位运算符 1. 算术运算符: + - * / % // ** ... 2. 赋值运算符: = += -= *= /= %= **= //= 3. 比较运算符: > < == != >= <= 4. 逻辑运算符: and or not 5. 位运算符: 把数字看作二进制数来进行计算 & | ^ ~ <<:>>: 右移,低位丢弃,高位: 最高位是0(正数),补0,最高位是1(负数),补1. 右移位运算相当于除以2的n次幂'''"""基本输入输出!在Python中,使用内置函数input("提示")接收用户的键盘输入: 无论输入的是数字还是字符,都被作为字符串读取! print(输出): 输入内容可以是数字和字符串,字符串用引号括起来!"""name = input("输入你的姓名:")age = input("输入你的年龄:")print("姓名:",name)print("年龄:",age)new_age = int(input("重新输入你的年龄:"))print(type(new_age))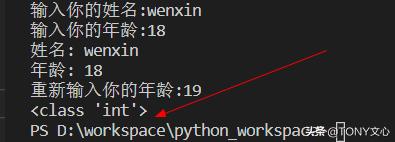
在Python中,默认情况下,print()语句输出后会自动换行,如果要一次输出多个内容,并且不换行,可以将要输出的内容使用逗号分隔!!!
""" 流程控制语句: 1. if 表达式 : 语句块 2. if 表达式 : 语句块 else : 语句块 3. if...elif...else 4. if语句的嵌套 循环语句: while for ... in 对象 : 循环体 循环嵌套 break continue"""""" 序列: 一块用于存放多个值的连续内存空间,按照一定顺序排列,每一个值(称为元素)都分配一个数字,称为索引或位置. 通过索引可以取出相应的值! Python中内置了5个常用的序列结构: 1. 列表 2. 元组 3. 集合 4. 字典 5. 字符串 以上序列结构的有几个通用操作,其中,集合和字典不支持索引、切片、相加和相乘操作! 索引: [x] -> names = ["tony","wenxin","文心"] names[0] # 输出: tony 负数也可以作为索引(-1) 切片: 可以访问一定范围内的元素,并生成一个新的序列: names[start : end : step] start: 开始位置(包括),不指定,默认为0 end: 结束位置(不包括),不指定,默认为序列的长度 step: 步长,不指定,默认为1,最后一个:也可以省略 names[2:] 输出: ["文心"] names[1:2] 输出: ["wenxin"] names[0:2:2] 输出: ["tony"] 如果要复制整个序列,可以将start和end参数都省略,中间添加冒号: names[:] 相加:+(相同类型、不去重、连接),相同类型:通过列表、元组、集合等,序列中的元素类型可以不同. 乘法:* 原来序列被重复n次的结果. [None] * 3 in: 检查某个元素是否为序列的成员(某个元素是否包含在某个序列中) value in sequence 内置函数计算序列的长度、最大值和最小值: len() max() min() 其他内置函数及作用: list(): 将序列转换为列表 str(): 将序列转换为字符串 sum(): 计算元素和 sorted(): 对元素进行排序 reversed(): 反向序列中的元素 enumerate(): 将序列组合为一个索引序列,多用在for循环中 """ """# 列表: 由一系列按特定顺序排列的元素组成的。内置的可变序列。# 元素都放在一对[]中,相邻元素间使用逗号','分隔开.# 内容上,可以将整数、实数、字符串、列表、元组等任何类型的内容放入到列表中,并且同一个列表中,# 元素的类型可以不同的# 创建num = [7,12,45,19,23,29] # 空列表name = []# list(data): data表示可以转换为列表的数据,其类型可以是rangge对象、字符串、元组# 或其他可迭代类型的数据list = list(range(10 ,20 , 2))print(list)# 删除列表 del listname (删除前要保证列表是存在的)# 访问列表元素 [索引]# 遍历'''for item in listname : 输出itemfor index,item in enumerate(listname) : 输出index和item # index索引 item元素值'''# 添加、修改、删除列表元素""" 添加: +: 也可以实现为列表添加元素,但执行速度比使用列表对象的append()方法慢, 建议使用append(),append()在列表的末尾追加元素. listname.append(obj) insert():也可以向列表的指定位置插入元素,效率没append()高,不推荐! listname.extend(seq): 一个列表中的全部元素添加到另一个列表中! 修改: listname[x] = value 删除: 根据索引:del listname[x] 根据元素值: listname.remove(name) 删除前判断元素是否存在 if listname.count(value) > 0 : listname.remove(value)"""# 对列表进行统计和计算"""# 获取指定元素出现的次数: listname.count(value)# 获取指定元素首次出现的下标: listname.index(value) 元素不存在,会抛出异常.# 统计数值列表的元素和: sum(iterable,[,start]) iterable: 要统计的列表 start: 统计从哪个数开始(包含),没指定,默认为0"""# 对列表进行排序""" 1. 使用列表对象的sort()方法: 排序后原列表中的元素顺序将发生改变. 只为列表定义! listname.sort(key=None,reverse=False) # 对中文内容支持不太好 key: 指定在进行比较之前要在每个列表元素上进行调用的函数,例如,key=str.lower: 表示排序时不区分大小写 key形参的值应该是一个函数,它接受一个参数并返回一个用于排序的键.只调用一次! reverse: True: 降序排列; False: 升序排列(默认)"""student_tuples = [ ('john','A',15), ('jane','B',12), ('dave','B',10)]print("排序前的列表:",student_tuples)# key(('john','A',15))student_tuples.sort(key = lambda student : student[2])print("排序后的列表:",student_tuples)
# 列表推导公式"""# 快速生成一个列表,或者根据某个列表生成满足指定需求的列表. 1. list = [Expression for var in range] Expression: 表达式,用于计算新列表的元素 var: 循环变量 range: 采用range()函数生成的range对象 2. newlist = [Expression for var in list] newlist: 新生成的列表名称 list: 用于生成新列表的原列表 3. newlist = [Expression for var in list if condition] condition: 条件表达式,用于指定筛选条件"""# 1import randomrandomNumber = [random.randint(10,100) for i in range(10)]print("随机数:",randomNumber)# 2price = [1200,5400,2999,6200,1999,8888]sale = [int(x*0.5) for x in price]print("原价格:",price)print("打5折的价格:",sale)# 3price = [1200,5400,2999,6200,1999,8888]sale = [ x for x in price if x > 5000]print("原价格:",price)print("价格高于5000的:",sale)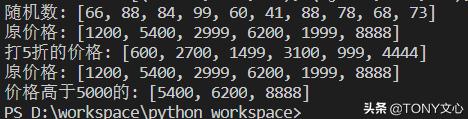
# 二维列表的使用(行,列)"""直接定义:[ ['床','前','明','月','光'], ['疑','是','地','上','霜'], ['举','头','望','明','月'], ['低','头','思','故','乡']]for循环创建列表推导公式创建创建二维数组后,访问方式:listname[x][y]"""# 直接创建poem = [ ['床','前','明','月','光'], ['疑','是','地','上','霜'], ['举','头','望','明','月'], ['低','头','思','故','乡']]print("直接创建:",poem)print(len(poem))# for循环创建num = []for i in range(4) : num.append([]) for j in range(5) : num[i].append(j)print("for循环创建:",num)# 列表推导公式创建arr = [[j for j in range(5)] for i in range(4)]print("列表推导公式创建:",arr)# 访问for i in range(len(poem)) : print(poem[i])for i in range(len(num)) : for j in range(len(num[i])) : print(num[i][j],end=" ") print("",end="")# 元组(tuple): 与列表类似,也是由一系列按特定顺序排列的元素组成,但它是不可变序列!!!# 元组也可称为不可变得列表。() "逗号"分隔# 内容上,可以是整数、实数、字符串、列表、元组等任何类型!# 在同一个元组中,元素的类型可以不同,因为它们之间没有任何关系!# 通常情况下,元素用于保存程序中不可修改的内容.# 元组和列表结构相似,主要区别: 元组是不可变序列(不可以单独修改),列表是可变序列(任意修改)!""" 元组的创建和删除: 1. tuplename = (element1,element2,...) 注意: 元组中的小括号(),并不是必须的,只要将一组元素值用逗号隔开,Python就可以视其为元组! name = "tony","wenxin","sunwentony" 创建的元组只包括一个元素,需要在元素的后面加一个逗号(,): name = ("tony",) 2. 空元组 tuplename = () 3. tuple(data): data表示可以转换为元组的数据,其类型可以是range对象、字符串、元组或其他可迭代类型的数据. tuple(range(10,20,2)) 4. 删除元组: del tuplename del语句在实际开发时,并不常用. Python自带的垃圾回收机制可以自动销毁不用的元组! name = ("tony","wenxin","sunwentony") del name 5. 访问: 1. 索引 2. 切片 3. for遍历 name[0] name[:3] for nickname in name : print("姓名:" + nickname,end=" ") 6. 修改: name[0] = "sun" # 元组是不可变序列,不能对它的单个元素值进行修改,但可以对元组进行重新赋值. name = ("tony","wenxin","sunwentony") name = ("文心","wenxin","sunwentony") # 对元组进行重新赋值 对元组进行连接组合! name = ("tony","wenxin","sunwentony") print("原元组:",name) name = name + ("什么","test") print("组合后:",name) 7. 元组推导式: 类似列表推导式,只需要将[]该为(),和列表推导式不同的是,元组推导式生成的结果是一个生成器对象. 要使用该生成器可以将其转换为元组或者列表,转换为元组用tuple()函数,列表用list()函数. 列表和元组的区别: 1. 列表可变序列,它的元素可以随时修改或者删除;元组属于不可变序列,其中的元素不可修改,除非整体替换. 2. 列表可以使用append(),extend(),insert(),remove(),pop()等方法实现添加和修改,元组没有这几个方法. 3. 列表可以使用切片访问和修改列表中的元素.元组也支持切片,但是它只支持通过切片访问元组中的元素,不支持修改. 4. 元组比列表的访问和处理速度快,所以当只是对其中的元素进行修改,建议使用元组. 5. 列表不能作为字典的键,而元组可以."""name = "tony","wenxin","sunwentony"for nickname in name : print("姓名:" + nickname, end="")# enumerate()函数用于将一个可遍历的数据对象(如列表或元组)组合为一个索引序列,# 同时列出数据和数据下标,一般在for循环中使用.for index,item in enumerate(name) : print("姓名" + str(index) + ":" + item, end="") name = ("tony","wenxin","sunwentony") name = ("文心","wenxin","sunwentony")print("对元组进行重新赋值:",name)# 在进行元组连接时,连接的内容必须都是元组.# 不能将元组和字符串或者列表进行连接.name = ("tony","wenxin","sunwentony") print("原元组:",name)name = name + ("什么","test")print("组合后的元组:",name)# 元组推导公式import randomrandomNumber = (random.randint(10,100) for i in range(10))# 打印查看randomNumber的类型print("randomNumber的类型:",type(randomNumber))# 转换为列表# print("转换为列表",list(randomNumber))# 转换为元组# print("转换为元组",tuple(randomNumber))# 用for或__next__()方法对生成器对象进行遍历# 在Python中,一般循环一边计算的机制,称为生成器: generator,遍历后原生对象不存在!# 生成器也是可迭代对象!for i in randomNumber : # 输出元素的值 print(i,end=" ")print("" * 10)# 字典: 与列表类似,也是可变序列,不过与列表不同,它是无序的可变序列,保存的内容是以键值对的形式存放的.# key-value,键是唯一的,而值可以有多个."""字典的主要特征: 字典有时也称为关联数组或散列表(hash)1. 通过键不是索引来读取2. 任意对象的无序集合: 无序,各项从左到右随机排序,这样可以提高查找效率.3. 可变的,且可以任意嵌套: 可以在原处增长或缩短(无须生成一个副本),且支持任意深度的嵌套(即它的值可以是列表或其他的字典)4. 键必须唯一: 不允许同一个键出现两次,如果出现两次,则后一个值会被记住.5. 键必须不可变: 可以使用数字,字符串或元组,但不能使用列表!"""""" 字典的操作: 1. 创建和删除 创建: key和value之间使用冒号分隔,相邻两个元素使用逗号分隔,所有元素放在一对"{}"中 dictionary = {'key1':'value1',...} key1: 元素的键,必须是唯一的,并且不可变,例如,可以是字符串、数字或者元组 value1: 元素的值,可以是任何数据类型,不是必须唯一的. information = {"name":"文心","age":18,"hobby":"basketball"} 2. 空字典: dictionay = {} 或 dictionary = dict() 3. 已有数据快速创建字典: (1). 映射函数创建字典 dictionay = dict(zip(list_one,list_two)) zip(): 用于将多个列表或元组对应位置的元素组合为元组,并返回包含这些内容的zip对象。 如果想获取元组,可以将zip对象使用tuple()函数转换为元组,如果想获取列表,则可以 使用list()函数转换为列表. (2). 给定key-value创建字典 dictionary = dict(key1=value1,key2=value2,...) # 注意是等号(=) dictionary = dict(绮梦='水瓶座', 冷伊一='射手座', 香凝='双鱼座', 黛兰='双子座') (3). dict对象的fromkeys()方法创建值为空的字典 dictionary = dict.fromkeys(list) (4). 存在的元组和列表创建字典 4. 删除 del dictionary 如果只想删除字典的全部元素,可以使用字典对象的clear()方法,执行后,原字典变为空字典. dictionary.clear() 字典对象的pop()方法删除并返回指定"键"的元素. 字典对象的popitem()方法删除并返回字典中的一个元素. 5. 访问 dictionary["冷伊一"] # 指定键不存在,抛出异常! 推荐使用字典对象的get()方法获取指定键的值: dictionary.get(key[,default]) key: 指定的键 default: 可选项目,键不存在,返回默认值,省略,返回None 6. 遍历字典 字典对象的items()方法获取字典的键值对的元组列表,然后用for遍历! 字典对象的values()方法获取字典的值 keys()返回键 7. 添加、修改和删除字典元素 (1). 添加和修改: dictionary[key] = value # key重复的话,新的值替换原来该键的值. (2). 删除: del dictionary[key] # key存在,删除元素;不存在,抛出异常:keyError 8. 字典推导式"""information = {"name":"文心","age":18,"hobby":"basketball"}print(information)print("information的类型:",type(information))name = ["绮梦","冷伊一","香凝","黛兰"]sign = ["水瓶座","射手座","双鱼座","双子座"]tmp = zip(name,sign)print(tmp)list_tmp = list(zip(name,sign))print(list_tmp)tuple_tmp = tuple(zip(name,sign))print(tuple_tmp)# zip映射函数创建字典dictionary_tmp = dict(zip(name,sign))print(dictionary_tmp)# 给定键值对创建字典# 绮梦等键不能添加引号,???dictionary = dict(绮梦='水瓶座', 冷伊一='射手座', 香凝='双鱼座', 黛兰='双子座')print("键值对创建字典:",dictionary)# dict对象的fromkeys()方法创建值为空的字典name = ["name","age","gender"]dictionary = dict.fromkeys(name)print("dict对象的fromkeys()创建的空字典:",dictionary)# 已存在的元组和列表创建字典name = ("绮梦","冷伊一","香凝","黛兰") # 注意: 此处不能用列表,因为字典的键不能改变,而列表是可变序列!sign = ["水瓶座","射手座","双鱼座","双子座"]dictionary = {name : sign}print("存在的元组和列表创建字典:",dictionary)# 删除dictionary = dict(绮梦='水瓶座', 冷伊一='射手座', 香凝='双鱼座', 黛兰='双子座')print("原字典:",dictionary)# clear# dictionary.clear()# print("clear()后的字典:",dictionary)# del# del dictionary# print("del后的字典:",dictionary) # NameError: name 'dictionary' is not defined# pop()和popitem()# value = dictionary.pop('绮梦')# print("pop()的元素:",value)# print("pop()后的dictionary:",dictionary)# popitem():随机返回并删除字典中的最后一对键和值(无序,LIFO)# value = dictionary.popitem()# print("value:",value)# print("dictionary:",dictionary)# value = dictionary.popitem()# print("value:",value)# print("dictionary:",dictionary)# value = dictionary.popitem()# print("value:",value)# print("dictionary:",dictionary)# 遍历字典 获取各个元素for item in dictionary.items() : print("字典的items():",item)# 遍历字典 获取具体的键和值for key,value in dictionary.items() : print(key + "的星座是" + value)# 遍历字典 获取键for key in dictionary.keys() : print("字典中的人名:",key)# 遍历字典 获取值for value in dictionary.values() : print("字典中的星座:",value)# 字典的添加 修改 删除dictionary = dict((('绮梦','水瓶座'), (('冷伊一','射手座')), ('香凝','双鱼座'), ('黛兰','双子座')))dictionary["文心"] = "摩羯座"print(dictionary)dictionary["黛兰"] = "处女座"print(dictionary)del dictionary["文心"]print(dictionary)# 字典推导式import random randomdict = {i : random.randint(10,100) for i in range(1,5)}print("通过字典推导式生成的字典:",randomdict)# 集合: 用于保存不重复元素的. 可变集合(set)和不可变集合(frozenset)""" set: 无序的不重复元素序列 frozenset: 冻结的集合,不可变(不能更改,没有add,remove方法),存在哈希值,可以作为字典的键,也可以作为其他集合的元素 1. 创建 {}: setname = {element1,element2,...} # 如果输入了重复的元素,Python会自动保留一个 set(iternation): 将列表、元组、字符串、range对象等可迭代对象转换为集合. 空集合: 只能使用set()实现! set是无序的,所以每次输出时元素的排列顺序可能都不相同. 注意: 创建集合,推荐使用set()函数. 2. 添加、删除 add(): setname.add(element) # element: 只能是字符串、数字、布尔类型,不能是列表、元组 del: del setname 删除整个集合; 集合对象的pop()和remove(element) 删除一个元素 集合对象的clear()清空集合 3. set集合的交集、并集、差集 -、&、^"""# 集合的创建name = {"wenxin","tony","sunwenxin"}print(name)print(type(name))name = set("TONY文心")print(name)name = set(range(1,5))print(name)name = set([1,2,3,4,5,1]) # 出现重复元素,只将保留一个.print(name)name = set(("文心","tony","wenxin"))print(name)# 集合的添加subjects = set(["C","C++","Java","PHP","Python"])print(subjects)subjects.add("MySQL")print(subjects)print("原集合subject:",subjects)# remove()subjects.remove("PHP")print("remove后的集合subject:",subjects)# pop()subjects.pop()print("pop后的集合subject:",subjects)# clear()subjects.clear()print("clear后的集合subjects:",subjects)# 集合的运算subjects = set(["C","C++","Java","PHP","Python","MySQL"])web = set(("HTML5","JavaScript","CSS","MySQL"))print("交集:",subjects & web)print("并集:",subjects | web)print("差集:",subjects - web)# 区别: 列表 元组 字典 集合 """列表(list): 可变、可重复、有序、[]元组(tuple): 不可变、可重复、有序、()字典(dictionary): 可变、可重复、无序、{key : value}集合(set): 可变、不可重复、无序、{}"""输出:
直接创建: [['床', '前', '明', '月', '光'], ['疑', '是', '地', '上', '霜'], ['举', '头', '望', '明', '月'], ['低', '头', '思', '故', '乡']]4for循环创建: [[0, 1, 2, 3, 4], [0, 1, 2, 3, 4], [0, 1, 2, 3, 4], [0, 1, 2, 3, 4]]列表推导公式创建: [[0, 1, 2, 3, 4], [0, 1, 2, 3, 4], [0, 1, 2, 3, 4], [0, 1, 2, 3, 4]]['床', '前', '明', '月', '光']['疑', '是', '地', '上', '霜']['举', '头', '望', '明', '月']['低', '头', '思', '故', '乡']0 1 2 3 40 1 2 3 40 1 2 3 40 1 2 3 4姓名:tony姓名:wenxin姓名:sunwentony姓名0:tony姓名1:wenxin姓名2:sunwentony对元组进行重新赋值: ('文心', 'wenxin', 'sunwentony')原元组: ('tony', 'wenxin', 'sunwentony')组合后的元组: ('tony', 'wenxin', 'sunwentony', '什么', 'test')randomNumber的类型: 52 87 26 36 93 27 61 44 85 35{'name': '文心', 'age': 18, 'hobby': 'basketball'}information的类型: [('绮梦', '水瓶座'), ('冷伊一', '射手座'), ('香凝', '双鱼座'), ('黛兰', '双子座')](('绮梦', '水瓶座'), ('冷伊一', '射手座'), ('香凝', '双鱼座'), ('黛兰', '双子座')){'绮梦': '水瓶座', '冷伊一': '射手座', '香凝': '双鱼座', '黛兰': '双子座'}键值对创建字典: {'绮梦': '水瓶座', '冷伊一': '射手座', '香凝': '双鱼座', '黛兰': '双子座'}dict对象的fromkeys()创建的空字典: {'name': None, 'age': None, 'gender': None}存在的元组和列表创建字典: {('绮梦', '冷伊一', '香凝', '黛兰'): ['水瓶座', '射手座', '双鱼座', '双子座']}原字典: {'绮梦': '水瓶座', '冷伊一': '射手座', '香凝': '双鱼座', '黛兰': '双子座'}字典的items(): ('绮梦', '水瓶座')字典的items(): ('冷伊一', '射手座')字典的items(): ('香凝', '双鱼座')字典的items(): ('黛兰', '双子座')绮梦的星座是水瓶座冷伊一的星座是射手座香凝的星座是双鱼座黛兰的星座是双子座字典中的人名: 绮梦字典中的人名: 冷伊一字典中的人名: 香凝字典中的人名: 黛兰字典中的星座: 水瓶座字典中的星座: 射手座字典中的星座: 双鱼座字典中的星座: 双子座{'绮梦': '水瓶座', '冷伊一': '射手座', '香凝': '双鱼座', '黛兰': '双子座', '文心': '摩羯座'}{'绮梦': '水瓶座', '冷伊一': '射手座', '香凝': '双鱼座', '黛兰': '处女座', '文心': '摩羯座'}{'绮梦': '水瓶座', '冷伊一': '射手座', '香凝': '双鱼座', '黛兰': '处女座'}通过字典推导式生成的字典: {1: 49, 2: 34, 3: 48, 4: 74}{'wenxin', 'tony', 'sunwenxin'}{'心', '文', 'T', 'N', 'Y', 'O'}{1, 2, 3, 4}{1, 2, 3, 4, 5}{'wenxin', 'tony', '文心'}{'C++', 'Python', 'PHP', 'Java', 'C'}{'C++', 'MySQL', 'Python', 'PHP', 'Java', 'C'}原集合subject: {'C++', 'MySQL', 'Python', 'PHP', 'Java', 'C'}remove后的集合subject: {'C++', 'MySQL', 'Python', 'Java', 'C'}pop后的集合subject: {'MySQL', 'Python', 'Java', 'C'}clear后的集合subjects: set()交集: {'MySQL'}并集: {'HTML5', 'C++', 'MySQL', 'CSS', 'Python', 'JavaScript', 'PHP', 'Java', 'C'}差集: {'C++', 'Python', 'PHP', 'Java', 'C'}# 字符串""""1. 拼接字符串: +运算可以连接多个字符串并产生一个字符串对象 字符串不允许直接与其他类型的数据拼接2. 计算字符串的长度: len(string); 不区分英文、数字和汉字,所有字符都按一个字符计算. 由于不同的字符所占字节数不同,所以要计算字符串的长度,需要先了解各字符所占的字节数! 在Python中,数字、英文、小数点、下划线和空格占用一个字节; 一个汉字可能占用2-4个字节,具体占用几个字节取决于采用的编码. 汉字在GBK/GB2312编码中占用2个字节,在UTF-8/Unicode编码中一般占用3个字节(或4个字节) 在实际开发中,需要获取字符串实际占用的字节数,即如果采用UTF-8编码,汉字占用3个字节,采用GBK或 GB2312,汉字占2个字节.这时,可以通过使用encode()方法,进行编码后再进行获取。3. 截取字符串: 字符串也属于序列,要截取它,可以采用切片的方法实现. string[start : end : step]4. 分割、合并字符串: 分割: 把字符串分割为列表 str.split(sep,maxsplit) str: 要进行分割的字符串 sep: 指定分隔符,可以包含多个字符,默认为None,即所有空字符(包括空格、换行()、制表符()等) 无论有几个空格或空白符都将作为一个分隔符进行分割 maxsplit: 可选,指定分割的次数,如不指定或者为-1,则分割次数没有限制,否则返回结果列表的元素个数, 个数最多为maxsplit+1 返回值: 分隔后的字符串列表 注意: 不指定sep参数,也不能指定maxsplit参数. 合并: 把列表合并为字符串 将多个字符串采用固定的分隔符连接在一起. new_str = str.join(iterable) new_str: 表示合并后生成的新字符串 str: 字符串类型,用于指定合并时的分隔符. iterable: 可迭代对象,该迭代对象中的所有元素(字符串表示)将被合并为一个新的字符串. 分割和合并是互逆操作!5. 检索字符串: 字符串查找 (1). count(): 检索指定字符串在另一个字符串中出现的次数,不存在返回0,否则返回次数. str.count[sub[, start[, end]]) sub: 检索的子字符串 start: 可选,检索范围的起始位置的索引,不指定,则从头开始检索. end: 可选,结束位置的索引,不指定,则一直检索到结尾. (2). find(): 检索是否包含指定的子字符串,不存在,返回-1,否则返回首次出现该子字符串时的索引. str.find(sub[, start[, end]]) # rfind() 从字符串右边开始查找 (3). index(): 同find()类似,但index()检索时,如果不存在会抛出异常! rindex(): 从右边开始查找 (4). startswith(): 检索字符串是否以指定子字符串开头. 是: True 否: False str.startswith(prefix[, start[, end]]) prefix: 要检索的子字符串 (5). endswith(): 检索字符串是否以指定子字符串结尾. str.endswith(suffix[, start[, end]]) suffix: 要检索的子字符串6. 字母的大小写转换 lower(): 将字符串中的大写字母转换为小写字母. upper(): 小写转大写7. 去除字符串中的空格和特殊字符 strip(): 去除字符串左右两边的空格和特殊字符. lstrip(): 左边的空格和特殊字符 rstrip(): 右边的空格的特殊字符 注意: 这里的特殊字符是指、、等. str.strip([chars]): chars: 可选,用于指定要去除的字符,可以指定多个. 设置为"@.",去除左右两侧包括的@和. 如果不指定,默认去除空格、制表符、 回车符、换行符等.8. 格式化字符串 格式化字符串是指先制定一个模板,在这个模板中预留几个空位,然后再根据需要填上相应的内容. 这些空位需要通过指定的符号标记(也称为占位符),而这些符号还不会显示出来. 在Python中,格式化字符串由两种方法: (1). 使用%操作符 (%操作符是早期Python中提供的方法,2.6版本开始,字符串对象提供了format()方法对字符串进行格式化) 格式:"%[-][+][0][m][.n]格式化字符"%exp -: 指定左对齐,正数前方无符号,负数前方加负号. +: 指定右对齐,正数前方加正号,负数前方加负号. 0: 表示右对齐,正数前方无符号,负数前方加负号,用0填充空白处(一般与m参数一起使用). m: 表示占有宽度. .n: 小数点后保留的位数. 格式化字符: 用于指定类型 %s: 字符串(采用str()显示) %c: 单个字符 %d或%i: 十进制整数 %x: 十六进制整数 %f或%F: 浮点数 %r: 字符串(采用repr()显示) %o: 八进制整数 %e: 指数(基底写为e) %E: 指数(基底写为E) %%: 字符% exp: 要转换的项.如果要指定的项有多个,需要通过元组的形式进行指定,但不能使用列表. (2). 使用字符串对象的format()方法 str.format(args): str: 用于指定字符串的显示样式(即模板). args: 用于指定要转换的项,如果有多项,则用逗号进行分隔. 模板: 创建模板时,需要使用"{}"和":"指定占位符,语法: {[index][:[[fill]align][sign][#][width][.precision][type]} 说明: index: 可选参数,指定要设置格式的对象在参数列表中的索引位置,从0开始. 如果省略,则根据值的先后顺序自动分配. fill: 可选参数,指定空白处填充的字符. align: 可选,用于指定对齐方式: 1. >: 内容右对齐 2. =: 内容右对齐,将符号放在填充内容的最左侧,且只对数字类型有效. 3. <: sign: width: .precision: type: s: d: c: e g b: o: x f len length: split>>> https://www.python.org/"print("原字符串:",str)list_one = str.split() # 默认分隔符print(list_one)list_two = str.split(">>>") # 多个字符进行分割print(list_two)list_three = str.split(".") # .进行分割print(list_three)list_four = str.split(" ",4) # 空格进行分割,最多4次分割(理解:最多切几刀)print(list_four)list_five = str.split(">") # >进行分割(此处要好好理解!),每个>分割一次,后面还有>得不到内容,将产生一个空元素.print(list_five)# 合并字符串 join()friends = ["wenxin","tony","文心","TONY"]join_friends = "#".join(friends)print("合并后的字符串:",join_friends)# 检索字符串 count() find()str = "wenxin#tony#TONY@python@PHP"nums = str.count("#")print("#在str中出现的次数:",nums)index = str.find("@")print("@在str中首次出现的位置索引",index)print("@是否存在于str中:","@" in str)if index > -1 : print("@存在于str中!")else : print("@不存在于str中!")# 检索字符串 rfind() 从右边开始查看""" %09d: 0右对齐,空白处用0填充,9占有宽度,d十进制整数 %s: 字符串(采用str()显示)"""# 使用%操作符template = '编号: %09d公司名称: %s 官方: http://www.%s.com' # 定义模板context_one = (7,"百度","baidu")context_two = (8,"百度学院","baiducolleage")print(template % context_one)print(template % context_two)# 使用字符串对象的format()方法"""# {[index][:[[fill]align][sign][#][width][.precision][type]}{:0>9s}: fill:0 align:>内容右对齐 width:9 s:对字符串类型格式化"""# 定义模板template = "编号:{:0>9s}公司名称: {:s} 官网: http://www.{:s}.com"context_one = template.format("7","百度","baidu")context_two = template.format("8","百度学院","baiducolleage")print("========format()方法格式化========")print("context_one:",context_one)print("context_two:",context_two)import math# 货币形式显示# {[index][:[[fill]align][sign][#][width][.precision][type]}print("1251+3950的结果是(以货币形式显示):¥{:,.2f}元".format(1251+3950))print("{0:.1f}用科学计数法表示:{0:E}".format(120000.1))print("π取5位小数:{:.5f}".format(math.pi))print("{0:d}的十六进制结果是:{0:#x}".format(100))print("天才是{:.0%}的灵感,加上{:.1%}的汗水!".format(0.01,0.99))# 字符串编码转换"""ASCIIGBK、GB2312UTF-8(Python 3.X中默认的编码格式,1字节表示英文字符、3个字节表示中文)在Python中,有两种常用的字符串类型,分别为str和bytes. str: Unicode字符(ASCII或其他) bytes: 表示二进制数据(包括编码的文本) 注意:str和bytes两种类型的字符串不能拼接在一起使用.通常情况下,str在内存中以Unicode表示,一个字符 对应若干个字节.但是如果在网络上传输,或者保存在磁盘上,就需要把str转换为字节类型,及bytes类型. bytes类型的数据是带b前缀的字符串(用单引号或双引号): bytes类型的数据: b"xd2" b"wenxin" str类型和bytes类型之间可以通过encode()和decode()方法进行转换,这两个方法是互逆的过程. encode()方法编码,是str对象的方法,用于将字符串转换为二进制数据(即bytes),也称为编码! str.encode([encoding="utf-8"][,errors="strict"]) encoding="utf-8": 可选参数,用于指定进行转码时采用的字符编码,默认为UTF-8,如果想使用简体中文, 也可以设置为gb2312,只有这一个参数时,encoding=可以省略 errors="strict": 可选参数,用于指定错误处理方式,其可选择值是: strict: 遇到非法字符就抛出异常(默认) ignore: 忽略非法字符 replace: 用?替换非法字符 xmlcharrefreplace: 使用XML的字符引用 在使用encode()方法,不会修改原字符串,如果需要修改原字符串,需要对其进行重新赋值. decode()方法为bytes对象的方法,用于将二进制数据转换为字符串,使用encode()方法转换的结果再转换为字符串, 也称为解码. bytes.decode([encoding="utf-8"][,errors="strict"]) 注意: 在设置解码采用的字符编码时,需要与编码时采用的字符编码一致."""# str对象的encode()str = "吃得苦中苦方为人上人"bytes = str.encode("GBK")print("原字符串:",str)print("转换后:",bytes)# bytes对象的decode()print("解码后的值:",bytes.decode("GBK"))字符串:
str's length: 25原字符串: Python 官方 >>> https://www.python.org/['Python', '官方', '>>>', 'https://www.python.org/']['Python 官方 ', ' https://www.python.org/']['Python 官方 >>> https://www', 'python', 'org/']['Python', '官方', '>>>', 'https://www.python.org/']['Python 官方 ', '', '', ' https://www.python.org/']合并后的字符串: wenxin#tony#文心#TONY#在str中出现的次数: 2@在str中首次出现的位置索引 16@是否存在于str中: True@存在于str中!编号: 000000007 公司名称: 百度 官方: http://www.baidu.com编号: 000000008 公司名称: 百度学院 官方: http://www.baiducolleage.com========format()方法格式化========context_one: 编号:000000007 公司名称: 百度 官网: http://www.baidu.comcontext_two: 编号:000000008 公司名称: 百度学院 官网: http://www.baiducolleage.com1251+3950的结果是(以货币形式显示):¥5,201.00元120000.1用科学计数法表示:1.200001E+05π取5位小数:3.14159100的十六进制结果是:0x64天才是1%的灵感,加上99.0%的汗水!原字符串: 吃得苦中苦方为人上人转换后: b'xb3xd4xb5xc3xbfxe0xd6xd0xbfxe0xb7xbdxcexaaxc8xcbxc9xcfxc8xcb'解码后的值: 吃得苦中苦方为人上人PS D:workspacepython_workspace>














 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









