







当Kafka减少Broker节点后,需要把数据分区迁移到其他节点上,以下将介绍我的一次迁移验证过程。前3步为环境准备,实际数据操作看第4步即可,增加Broker节点,也可以采用步骤4相同的方法进行重新分区。
方案思想:
使用kafka-reassign-partitions命令,把partition重新分配到指定的Broker上
1、创建测试topic
具有3个分区,2个副本
1kafka-topics --create --topic test-topic \
2--zookeeper cdh-002/kafka \
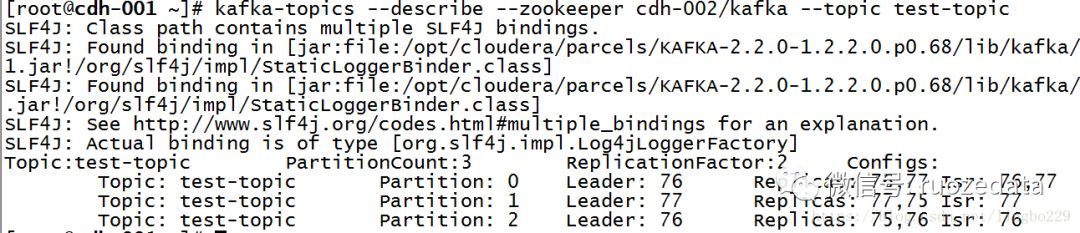
3--replication-factor 2 --partitions 32、查看test-topic
1kafka-topics --describe --zookeeper cdh-002/kafka --topic test-topic

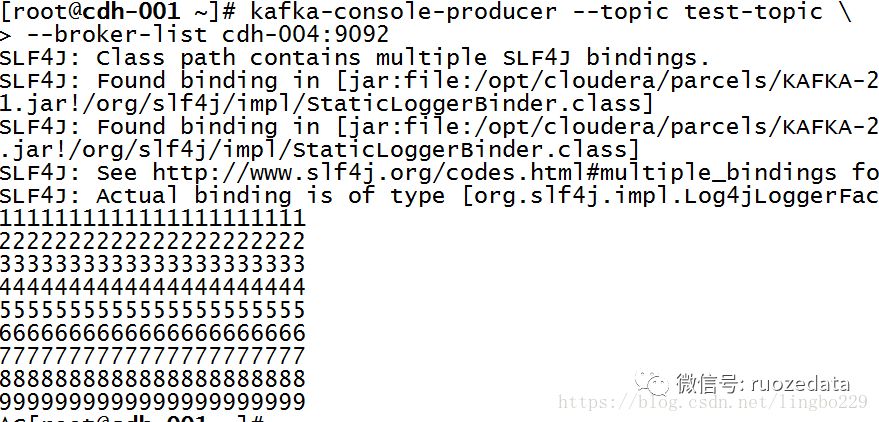
3、产生若干条数据
1kafka-console-producer --topic test-topic \
2--broker-list cdh-004:9092
4、kafka-reassign-partitions重分区
(假设需要减少节点broker 75,本测试通过关闭对应kafka broker节点模拟)
1) 新建文件topic-to-move.json
比加入如下内容:
1{"topics": [{"topic":"test-topic"}], "version": 1}
2) 使用--generate生成迁移计划
broker-list根据自己环境设置,我的环境由于broker 75挂掉了,只剩下76和77
1kafka-reassign-partitions --zookeeper cdh-002/kafka \
2--topics-to-move-json-file /opt/lb/topic-to-move.json \
3--broker-list "76,77" --generate
输出日志:
(从日志可知各个分区副本所在的Broker节点,以及建议的副本分布)
1Current partition replica assignment (当前分区副本分布)
2{"version":1,"partitions":[{"topic":"test-topic","partition":0,"replicas":[76,77]},{"topic":"test-topic","partition":2,"replicas":[75,76]},{"topic":"test-topic","partition":1,"replicas":[77,75]}]}
3Proposed partition reassignment configuration (建议分区副本分布)
4{"version":1,"partitions":[{"topic":"test-topic","partition":0,"replicas":[76,77]},{"topic":"test-topic","partition":2,"replicas":[76,77]},{"topic":"test-topic","partition":1,"replicas":[77,76]}]}
3) 新建文件kafka-reassign-execute.json
并把建议的分区副本分布配置拷贝到新建文件中

4) 使用--execute执行迁移计划
(有数据移动,broker 75上的数据会移到broker 76和77上,如果数据量大,执行的时间会比较久,耐心等待即可)
1kafka-reassign-partitions --zookeeper cdh-002/kafka \
2--reassignment-json-file /opt/lb/kafka-reassign-execute.json \
3--execute
5)使用-verify查看迁移进度
1kafka-reassign-partitions --zookeeper cdh-002/kafka \
2--reassignment-json-file /opt/lb/kafka-reassign-execute.json \
3--verify

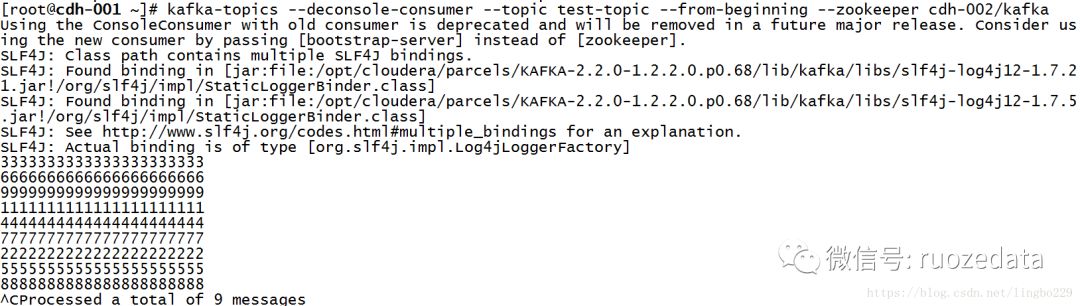
6)通过消费者验证,可知,并未丢失数据。
注意需要加--from-beginning。
(此时broker 75和77同时宕机,也不会丢失数据,因为76上有了所有分区的副本)
1kafka-console-consumer --topic test-topic --from-beginning --zookeeper cdh-002/kafka
另外一种验证方法是:通过查看Kafka存储路径来确认,是否有迁移数据(生产上一般都用这个)

1[root@cdh-003 ~]# cd /var/local/kafka/data/
2[root@cdh-003 data]# ll
3rwxr-xr-x 2 kafka kafka 110 Oct 23 14:21 test-topic-0
4drwxr-xr-x 2 kafka kafka 110 Oct 23 14:52 test-topic-1
5drwxr-xr-x 2 kafka kafka 110 Oct 23 14:21 test-topic-2作者:若泽数据—微步229
原文:
https://blog.csdn.net/lingbo229/article/details/83309208
回归原创文章:
2019,奔跑没有尽头
若泽数据2018视频集合
Flink生产最佳实践,2018年12月刚出炉
我去过端午、国庆生产项目线下班,你呢?
2019元旦-线下项目第11期圆满结束
大数据生产预警平台项目之文章汇总
学习大数据的路上,别忘了多给自己鼓掌
明年毕业的我,拿了大数据30万的offer!
最全的Flink部署及开发案例
我司Kafka+Flink+MySQL生产完整案例代码
代码 | Spark读取mongoDB数据写入Hive普通表和分区表
我司Spark迁移Hive数据到MongoDB生产案例代码















 478
478











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









