







概述
我们知道内存是以页框为单位,每个页框大小默认是4K(大页除外),而在系统运行时间长后就会出现内存碎片,内存碎片的意思就是一段空闲页框中,会有零散的一些正在使用的页框,导致此段页框被这些正在使用的零散页框分为一小段一小段连续页框,这样当需要大段连续页框时就没办法分配了,这些空闲页框就成了一些碎片,不能合并起来作为一段大的空闲页框使用,如下图:
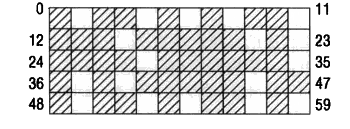
白色的为空闲页框,而有斜线的为已经在使用的页框,在这个图中,空闲页框都是零散的,它们没办法组成一块连续的空闲页框,它们只能单个单个进行分配,当内核需要分配连续页框时则没办法从这里分配。为了解决这个问题,内核实现了内存碎片整理功能,其原理很简单,就是从这块内存区段的前面扫描可移动的页框,从内存区段后面向前扫描空闲的页框,两边扫描结束后,将可移动的页框放入到空闲页框中,最后最理想的结果就如下图:
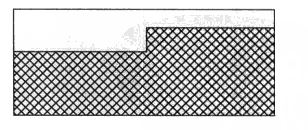
这样移动之后就把前面的页框整理为了一大段连续的物理页框了,当然这只是理想情况,因为并不是所有页框都可以进行移动,像内核使用的页框大部分都不能够移动,而用户进程的页框大部分是可以移动了。
内存碎片整理
对于内存碎片整理来说,只会正对三种类型的页进行整理,分别是:MIGRATE_RECLAIMABLE、MIGRATE_MOVABLE、MIGRATE_CMA。并且内存碎片整理是耗费一定的内存、CPU和IO的。
在内存碎片整理中,可以移动的页框有MIGRATE_RECLAIMABLE、MIGRATE_MOVABLE与MIGRATE_CMA这三种类型的页框,而因为内存碎片整理分为同步和异步,在异步过程中,只会移动MIGRATE_MOVABLE和MIGRATE_CMA这两种类型的页框。因为这两种类型的页框处理,是不会涉及到IO操作的。而在同步过程中,这三种类型的页框都会进行移动,因为MIGRATE_RECLAIMABLE基本上都是文件页,在移动过程中,有可能要将脏页回写,会涉及到IO操作,也就是在同步过程中,是会涉及到IO操作的。
内存碎片整理模式
内存碎片整理分为三种模式,三种模式耗费的资源和对整个系统的压力不一样,如下:
enummigrate_mode {/** 异步模式的意思是禁止阻塞,遇到阻塞和需要调度的时候直接返回,返回前会把隔离出来的页框放回去
* 在内存不足以分配连续页框时进行内存碎片整理,默认初始是异步模式,如果异步模式后还不能分配连续内存,则会转为轻同步模式(当明确表示不处理透明大页,或者当前进程是内核线程时,就会转为请同步模式)
* 而kswapd内核线程中只使用异步模式,不会使用同步模式
* 所以异步不处理MIRGATE_RECLAIMABLE类型的页框,因为这部分页框很大可能导致回写然后阻塞,只处理MIGRATE_MOVABLE和MIGRATE_CMA类型中的页
* 即使匿名页加入到了swapcache,被标记为了脏页,这里也不会进行回写,只有匿名页被内存回收换出时,才会进行回写
* 异步模式不会增加推迟计数器阀值*/MIGRATE_ASYNC,/*在内存不足以分配连续页框并进行了异步内存碎片整理之后,有可能会进行轻同步模式,轻同步模式下处理MIRGATE_RECLAIMABLE、MIGRATE_MOVABLE和MIGRATE_CMA类型的页
* 此模式下允许进行大多数操作的阻塞,比如在磁盘设备繁忙时,锁繁忙时,但不会阻塞等待正在回写的页结束,对于正在回写的页直接跳过,也不会对脏页进行回写
* 轻同步模式会增加推迟计数器阀值*/MIGRATE_SYNC_LIGHT,/*同步模式意味着在轻同步基础上,可能会对隔离出来需要移动的脏文件页进行回写到磁盘的操作(只会对脏文件页进行回写,脏匿名页只做移动,不会被回写),并且当待处理的页正在回写时,会等待到回写结束
* 这种模式发生有三种情况:
* 1.cma分配
* 2.通过alloc_contig_range()尝试分配一段指定了开始页框号和结束页框号的连续页框时
* 3.将1写入sysfs中的vm/compact_memory
* 同步模式会增加推迟计数器阀值,并且在同步模式下,会设置好compact_control,让同步模式时忽略pageblock的PB_migrate_skip标记*/MIGRATE_SYNC,
};
异步模式:内存碎片整理最常用的模式,在此模式中不会进行阻塞(但是时间片到了可以进行主动调度),也就是此种模式不会对文件页进行处理,文件页用于映射文件数据使用,这种模式也是对整体系统压力较小的模式。
轻同步模式:当异步模式整理不了更多内存时,有两种情况下会使用轻同步模式再次整理内存:1.明确表示分配的不是透明大页的情况下;2.当前进程是内核线程的情况下。这个模式中允许大多数操作进行阻塞(比如隔离了太多页,需要阻塞等待一段时间)。这种模式会处理匿名页和文件页,但是不会对脏文件页执行回写操作,而当处理的页正在回写时,也不会等待其回写结束。
同步模式:所有操作都可以进行阻塞,并且会等待处理的页回写结束,并会对文件页、匿名页进行回写到磁盘,所以导致最耗费系统资源,对系统造成的压力最大。它会在三种情况下发生:1.从cma中分配内存时;2.调用alloc_contig_range()尝试分配一段指定了开始页框号和结束页框号的连续页框时;3.通过写入1到sysfs中的/vm/compact_memory文件手动实现同步内存碎片整理。
在内存不足以分配连续页框后导致内存碎片整理时,首先会进行异步的内存碎片整理,如果异步的内存碎片整理后还是不能够获取连续的页框(这种情况发生在很多离散的页的类型是MIGRATE_RECLAIMABLE),并且gfp_mask明确表示不处理透明大页的情况或者该进程是个内核线程时,则进行轻同步的内存碎片整理。
在kswapd中,永远只进行异步的内存碎片整理,不会进行同步的内存碎片整理,并且在kswapd中会跳过标记了PB_migrate_skip的pageblock。相反非kswapd中的内存碎片整理,当推迟次数超过了推迟阀值时,会将pageblock的PB_migrate_skip标记清除,也就是会扫描之前有PB_migrate_skip标记的pageblock。
在同步内存碎片整理时,会忽略所有标记了PB_migrate_skip的pageblock,强制对这段内存中所有pageblock进行扫描(当然除了MIGRATE_UNMOVEABLE的pageblock)。
异步是用得最多的,它整理的速度最快,因为它只处理MIGRATE_MOVABLE和MIGRATE_CMA两种类型,并且不处理脏页和阻塞的情况,遇到需要阻塞的情况就返回。而轻同步的情况是在异步无法有效的整理足够内存时使用,它会处理MIGRATE_RECLAIMABLE、MIGRATE_MOVABLE、MIGRATE_CMA三种类型的页框,在一些阻塞情况也会等待阻塞完成(比如磁盘设备回写繁忙,待移动的页正在回写),但是它不会对脏文件页进行回写操作。同步整理的情况就是在轻同步的基础上会对脏文件页进行回写操作。
这里需要说明一下,非文件映射页也是有可能被当成脏页的,当它加入swapcache后会被标记为脏页,不过在内存碎片整理时,即使匿名页被标记为脏页也不会被回写,它只有在内存回收时才会对脏匿名页进行回写到swap分区。在脏匿名页进行回写到swap分区后,基本上此匿名页占用的页框也快被释放到伙伴系统中作为空闲页框了。
内存碎片整理算法
先说一下内存碎片整理的算法,首先,内存碎片整理是以zone为单位的,而zone中又以pageblock为单位。在内存碎片整理开始前,会在zone的头和尾各设置一个指针,头指针从头向尾扫描可移动的页,而尾指针从尾向头扫描空闲的页,当他们相遇时终止整理。下图就是简要的说明图:
初始时内存状态(默认所有正在使用的页框都为可移动):

从头扫描可移动页框:

从尾扫描空闲页框:
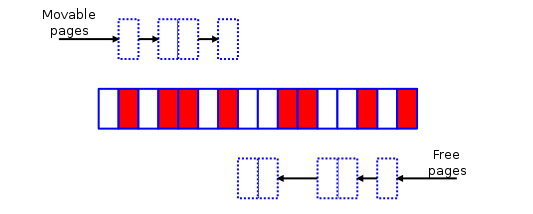
结果:

但是实际情况并不是与上面图示的情况完全一致。头指针每次扫描一个符合要求的pageblock里的所有页框,当pageblock不为MIGRATE_MOVABLE、MIGRATE_CMA、MIGRATE_RECLAIMABLE时会跳过这些pageblock,当扫描完这个pageblock后有可移动的页框时,会变为尾指针以pageblock为单位向前扫描可移动页框数量的空闲页框,但是在pageblock中也是从开始页框向结束页框进行扫描,最后会将前面的页框内容复制到这些空闲页框中。
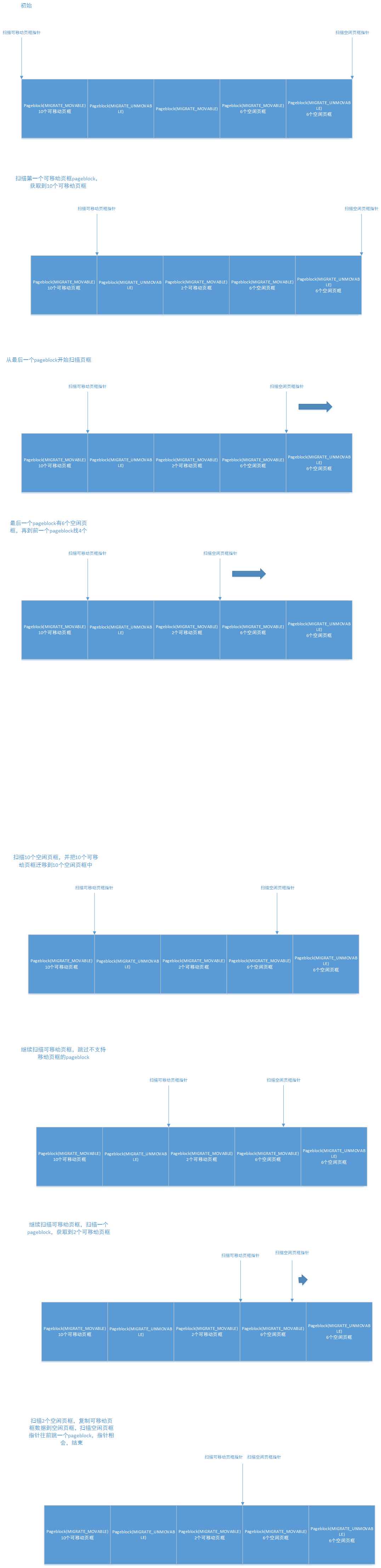
需要注意,扫描可移动页框是要先判断pageblock的类型是否符合,符合的pageblock才在里面找可移动的页框,当扫描了一个符合的pageblock后本次扫描可移动页框会停止,转到扫描空闲页框。而扫描空闲页框时也会根据pageblock进行扫描,只是从最后一个pageblock向前扫描,而在每个pageblock里面,也是从此pageblock开始页框向pageblock结束页框进行扫描。当需要的空闲页框数量=扫描到的一个pageblock中可移动的页框数量时,则会停止。
内存碎片整理发生时机
现在再来说说什么时候会进行内存碎片整理。它会在四个地方调用到:
内核从伙伴系统以min阀值获取连续页框,但是连续页框又不足时。
当需要从指定地方获取连续页框,但是中间有页框正在使用时。
因为内存短缺导致kswapd被唤醒时,在进行内存回收之后会进行内存碎片整理。
将1写入sysfs中的/vm/compact_memory时,系统会对所有zone进行内存碎片整理。
而内存碎片整理是一个相当耗费资源的事情,它并不会经常会执行,即使因为内存短缺导致代码中经常调用到内存碎片整理函数,它也会根据调用次数选择性地忽略一些执行请求,见内存碎片整理推迟。
系统判定是否执行内存碎片整理的标准是
在分配页框过程中,zone显示是有足够的空闲页框供于本次分配的,但是伙伴系统链表中又没有连续页框段用于本次分配。原因就是过多分散的空闲页框,它们没办法组成一块连续页框存放在伙伴系统的链表中。
在kswapd唤醒后会对zone的页框阀值进行检查,如果可用页框少于高阀值则会进行内存回收,每次进行内存回收之后会进行内存碎片整理。
即使满足标准,也不一定会执行内存碎片整理,具体见后面的内存碎片整理推迟和compact_zone()函数。
内存碎片整理结束时机
在内存碎片整理中,一次zone的内存碎片整理结束条件有三条:
可移动页框扫描的位置是否已经超过了空闲页框扫描的位置,超过则结束整理,并且会重置zone->compact_cached_free_pfn和zone->compact_cached_migrate_pfn,并且不是kswap时,会设置zone->compact_blockskip_flush为真
zone的空闲页框数量满足了 (zone的low阀值 + 1<
判断伙伴系统中是否有比order值大的空闲连续页框块,有则结束整理,如果order为-1,则忽略此条件
不过有例外,通过写入到/proc/sys/vm/compact_memory进行强制内存碎片整理的情况,则判断条件只有第1条。对于zone来说,可移动页扫描和空闲页扫描交汇,也就是第一种情况时,才算是对zone进行了一次完整的内存碎片整理,这个完整的内存碎片整理并不代表一次内存碎片整理就能实现,也有可能是对zone进行多次内存碎片整理才达到的,因为每次内存碎片整理结束时机还有另外两种。当zone达到一次完整的内存碎片整理时,会重置两个扫描的起始为zone的第一个页和最后一个页,并且不是处于kswap中时,会设置zone->compact_blockskip_flush为真,这个zone->compact_blockskip_flush在kswapd准备睡眠时,会将zone的所有pageblock的PB_migrate_skip标志清除。
内存碎片整理推迟
内存碎片整理虽然是针对每个zone的,但是执行的时候传入的是一个zonelist,这样就会有一种情况,就是可能某个zone刚进行过内存碎片整理,而系统因为内存不足又进行了内存碎片整理,导致这个刚进行内存碎片整理的zone又要执行内存碎片整理,为了避免这种情况,内核会为每个zone做一个整理推迟计数,这个计数是每个zone都会有的,在struct zone里:
structzone
{
....../*这两个用于推迟内存碎片整理处理,只有当内存碎片整理时使用的order大于compact_order_failed才会推迟
* 只有一种情况会重置这两个值:在zone执行内存碎片整理后,从此zone中分配到了内存,会重置*/
/*用于判断是否需要推迟,每次推迟会++,然后判断是否超过 1UL << compact_defer_shift,超过了则要进行内存碎片整理*/unsignedintcompact_considered;/*用于定量推迟计数,主要用于内存碎片整理分为compact_considered < compact_defer_shift和compact_considered >= compact_defer_shift两种情况,当次管理区的内存碎片整理成功后被置0,不会大于COMPACT_MAX_DEFER_SHIFT
* 只有在同步和轻同步模式下进行内存碎片整理后,zone的空闲页框数量没达到 (low阀值 + 1<
* 当进行内存碎片整理时,使用的order小于此值,则允许进行内存碎片整理,否则记一次推迟
* 当内存碎片整理完成时,此值为使用的order值+1,意思是假设大一级的order在整理中会失败
* 当内存碎片整理失败时,此值则是等于order值,表示使用此大小的order值,有可能会导致失败*/
intcompact_order_failed;
......
}
compact_considered:称为内存碎片整理推迟计数器,每次zone的内存碎片整理推迟了,此值会+1
compact_defer_shift:称为内存碎片整理推迟阀值,内存碎片整理推迟计数器达到 1 << compact_defer_shift 后,就不能对zone进行内存碎片整理推迟了。
compact_order_failed:称为内存碎片整理失败最大order值,记录着此zone进行内存碎片整理失败时使用的最大的order值
当一个zone要进行内存碎片整理时,首先会判断本次整理需不
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 540
540











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









