






共轭函数
共轭函数的定义:
设函数f:Rn→R,定义函数f∗:Rn→R为:
此函数称为函数f的共轭函数。即函数yx和函数f(x)之间差值的上确界。
如下图所示:
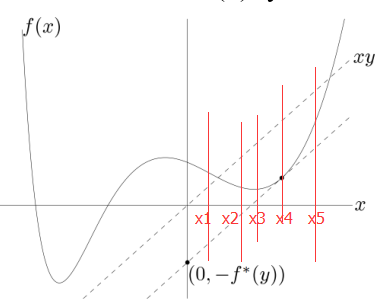
假设y=2时,yTx的图像是xy那条虚线,而定义式右边的部分是求x等于多少时yTx - f(x)的值最大,在上图中我们可以一眼看出,在“和xy平行且是f(x)切线的那个点”处两函数的差值最大,假设差值是10,于是我们就求出yTx - f(x)的共轭函数的一个点,即f*(2) = 10,就这样把y扩展到这个定义域范围内后就得到了整个共轭函数。
假设有函数f(x) = xTQx/2,其中Q是可逆的对称阵,算它的共轭函数,根据定义就是求:g(x, y) = yTx - xTQx/2 的上确界。
于是将g(x, y)对x求偏导:
g’(x,y) = (yTx)’ - (xTQx/2)’
因为xTQx对x求偏导的结果是2Qx,所以上式继续推导为:
=y - Qx
另偏导等于0,得:
x= Q-1y
因为是求偏导,所以得到的是上确界,于是把上式代入g(x, y)后就得f(x)的共轭函数:
f*(y)= (yTQ-1y)/2
负熵函数: f(x)=xlog(x), x∈R+,f(0)=0,共轭函数
f∗(y)=supyx−xlog(x), 在y=log(x)+1取最大值,即x=ey−1,因此,f∗(y)=ey−1.
http://blog.csdn.net/raby_gyl/article/details/53178467














 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









