







共轭函数是最优化问题中非常重要的概念,常用来在原问题和对偶问题之间进行转换。
本文从便于理解的角度对其进行介绍,并推导常见例子。
本文主要参考S. Boyd and L. Vandenberghe, Convex Optimization中3.3节。
定义
对于原函数
f
(
x
)
,
x
∈
D
f(x),x\in D
f(x),x∈D,其共轭函数为:
f
∗
(
y
)
=
sup
x
∈
D
(
<
y
,
x
>
−
f
(
x
)
)
f^*(y)=\sup_{x\in D} (<y,x>-f(x))
f∗(y)=x∈Dsup(<y,x>−f(x))
其中, < y , x > <y,x> <y,x>表示两个变量的内积
- 对于标量: < y , x > = y ⋅ x <y,x>=y\cdot x <y,x>=y⋅x
- 对于向量: < y , x > = y T x <y,x>=y^Tx <y,x>=yTx
- 对于 n × n n\times n n×n对称矩阵: < y , x > = tr ( y x ) <y,x>=\textbf{tr} (yx) <y,x>=tr(yx)
特别注意,共轭函数的定义域要求对 x ∈ D x\in D x∈D, < y , x > − f ( x ) <y,x>-f(x) <y,x>−f(x)有上界。即, f ∗ ( y ) f^*(y) f∗(y)不能为无穷大。
物理意义
对于共轭函数的每一个自变量
y
=
y
ˉ
y=\bar{y}
y=yˉ,其取值相当于一条直线与原函数之差的最大值:
f
∗
(
y
ˉ
)
=
sup
x
∈
D
(
l
(
x
)
−
f
(
x
)
)
f^*(\bar y)=\sup_{x\in D}(l(x)-f(x))
f∗(yˉ)=x∈Dsup(l(x)−f(x))
这条直线
l
(
x
)
=
<
y
ˉ
,
x
>
l(x)=<\bar y,x>
l(x)=<yˉ,x>,其斜率由
y
ˉ
\bar y
yˉ决定。
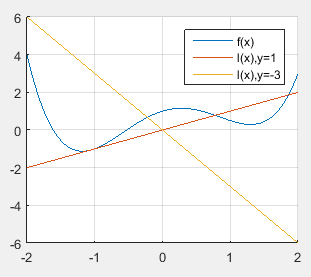
两条曲线之差随着
x
x
x变化,其最大值可以对
x
x
x求导得到:
∂
(
<
y
,
x
>
−
f
(
x
)
)
∂
x
=
0
⇒
f
′
(
x
)
=
y
\frac{\partial(<y,x>-f(x))}{\partial x}=0 \Rightarrow f'(x)=y
∂x∂(<y,x>−f(x))=0⇒f′(x)=y
即:曲线斜率与直线斜率相同处的
x
x
x,能够得到最大值。
f
∗
(
y
ˉ
)
=
<
y
ˉ
,
x
ˉ
>
−
f
(
x
ˉ
)
,
s
u
b
j
e
c
t
t
o
f
(
x
ˉ
)
=
y
ˉ
f^*(\bar y)=<\bar y, \bar x>-f(\bar x), subject\ to\ f(\bar x)=\bar y
f∗(yˉ)=<yˉ,xˉ>−f(xˉ),subject to f(xˉ)=yˉ

举例
Negative entropy
原函数: f ( x ) = x log x , x > 0 f(x)=x\log x, x>0 f(x)=xlogx,x>0
原函数为增函数。
对于
y
<
0
y<0
y<0,
l
(
x
)
l(x)
l(x)为减函数。则
l
(
x
)
−
f
(
x
)
l(x)-f(x)
l(x)−f(x)为减函数,不超过其在零点取值。
对于
y
≥
0
y\geq 0
y≥0,
l
(
x
)
l(x)
l(x)也是增函数
lim
x
→
∞
l
(
x
)
/
f
(
x
)
=
lim
x
→
∞
l
′
(
x
)
/
f
′
(
x
)
=
lim
x
→
∞
y
/
(
log
x
+
x
)
=
0
\lim_{x\to \infty} l(x)/f(x)=\lim_{x \to \infty} l'(x)/f'(x)=\lim_{x\to \infty} y/(\log x + x)=0
x→∞liml(x)/f(x)=x→∞liml′(x)/f′(x)=x→∞limy/(logx+x)=0
l ( x ) l(x) l(x)增速小于 f ( x ) f(x) f(x)增速,故其差有界。
故, f ∗ ( y ) f^*(y) f∗(y)的定义域为 y ∈ R y\in R y∈R。
找到最大值处
x
x
x的表达式:
x
y
−
x
log
x
∂
x
=
0
⇒
x
=
e
y
−
1
\frac{xy - x\log x}{\partial x}=0 \Rightarrow x=e^{y-1}
∂xxy−xlogx=0⇒x=ey−1
代入共轭函数:
f
∗
(
y
)
=
y
⋅
e
y
−
1
−
e
y
−
1
(
y
−
1
)
=
e
y
−
1
f^*(y)=y\cdot e^{y-1}-e^{y-1}(y-1)=e^{y-1}
f∗(y)=y⋅ey−1−ey−1(y−1)=ey−1

















 3996
3996

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









