






分布式系统开发过程中,我们常常会遇到同时访问多个远程接口,然后在自己的业务逻辑内聚合多个接口的调用结果。这个过程,类比到现实中很像“烧水泡茶”。
在正式讲技术实现之前,我们先以“烧水泡茶”为例,讨论一下并发任务执行在现实中是如何进行的。
烧水泡茶,往往分为如下几步:
清洗热水壶(3min)
烧开水(8min)
清洗茶壶(2min)
清洗茶杯(5min)
准备茶叶(1min)
泡茶(3min)
这个例子,源自著名数学家华罗庚的《统筹方法》一文,先生试图通过这样一个例子,为我们讲解如何通过统筹思想,组合不同的步骤,最终达到能够在最短的时间内喝到茶水的目的。
那么我们就试着分析一下这个案例,如果我们不加优化,直接通过串行方式进行泡茶工序,那么具体的执行路径就如下图所示:
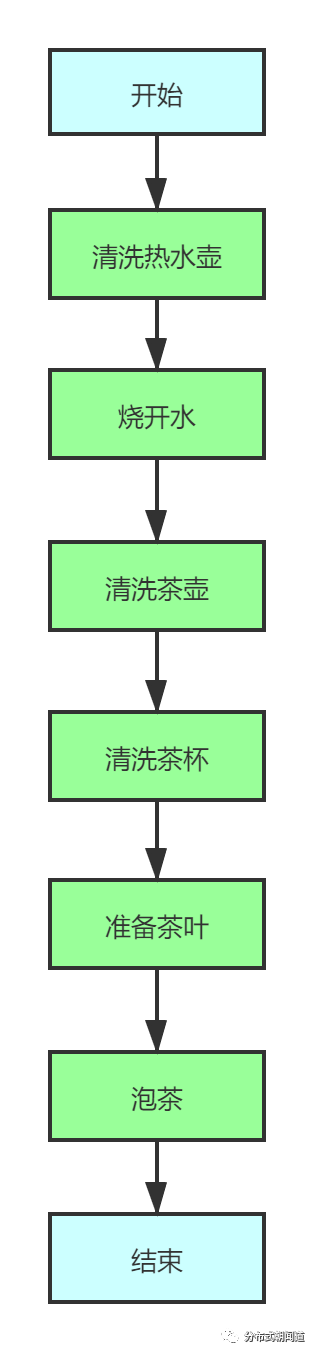
也就是说,我们进行“烧水泡茶”的过程是完全串行操作的,假设每个步骤之间是无缝衔接的,那么最终花费的时间 T0 = 3 + 8 + 2 + 5 + 1 + 3 = 22min。
我们发现,烧开水的时间很长,在这个时间内完全可以去做别的事情,也就是烧开水的过程可以与其他的步骤并行执行。因为必须要把热水壶洗干净才能烧开水,毕竟卫生是第一位的嘛。也就是说第一步“清洗热水壶”需要单独进行。我们尝试对上面的串行流程稍作统筹优化,得到优化后的泡茶流程(看不清可点击放大)。

我们发现,烧开水的时间 (8min)= 清洗茶壶 (2min) + 清洗茶杯 (5min) + 准备茶叶 (1min),也就是在等待水烧开的空档里,我们可以按顺序去执行剩余的准备步骤,最后等茶具和开水都准备到位,就可以开始泡茶,然后享受美好的品茗时光了。
改进后的流程,最终花费的时间 T1 = 3 + 8 + 3 = 14min。相比完全串行的方式,节省了8分钟。毕竟时间就是金钱,能够提前八分钟喝到美味的茗茶,想想也是一件美好的事情。
从这个例子能够看出,合理安排不同操作步骤的执行顺序和关系,让没有强关联的步骤能够并发执行,尽量减少不同步骤执行的串行程度,能够在一定程度上达到提升业务逻辑执行效率的目的。
回到技术问题本身,在Java的分布式系统开发领域,我们常常通过 线程池+Future + Callable 方式来并发地执行任务,从而缩短业务逻辑执行时间,提高执行效率。
接下来我们先对这几个重要的知识点进行科普,为后文的实战奠定理论基础。伟人说过:“在战略上要藐视敌人,在战术上要重视敌人”,虽然问题本身不复杂,但是必要的理论基础准备是必要的。
聊聊Callable
首先聊聊Callable。
Callable位于java.util.concurrent包下,它是一个接口,只声明了一个方法,方法名为call(),简明扼要:
Callable的声明如下:
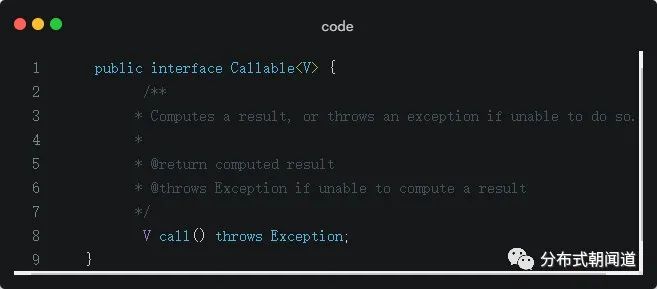
通过注释和接口声明,可以看出Callable是一个泛型接口,并且call()函数返回的类型就是传递进来的泛型V。
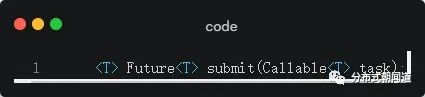
Callable的使用通常需要借助线程池ExecutorService;在ExecutorService中有多个submit的重载方法,其中就有接受Callable实例的方法,这个方式使我们在实战中经常使用到的,因此需要重点关注:
聊聊Future
了解了Callable之后,我们再了解一下Future。在上文中,我们已经能够通过ExecutorService的submit重载方法看出端倪,submit方法的返回值为一个Future带泛型T。
Future类同样位于java.util.concurrent(再次不吝赞美地夸赞一下,道格李大叔真的优秀)包下,是一个接口:

为了展示方便我去除了注释。
我们通过一句话概括Future:
我们通过Future能够实现对具体Runnable或者Callable任务的执行结果进行取消(cancel)、查询是否完成(isDone)、获取结果等操作(get)。
当我们需要对一个异步任务获取其返回结果时,可以通过get方法进行操作,get方法支持指定超时时间,当达到超时时间,则会抛出TimeoutException,因此对于超时时间的需要谨慎指定,重要的是,该方法会阻塞调用get方法的线程,直到任务返回结果。
在Future接口中声明了5个方法,我们简单对Future的几个方法的作用进行介绍,方便读者进行理解。下面是对每个方法的作用的依次解释:
趁热乎,再看看FutureTask
日常开发中,我们发现还有个类经常出现在我们的视线中,它就是FutureTask。
我们看看FutureTask的声明就知道它具体是干什么用了。

我们发现FutureTask实现了接口RunnableFuture,我们再顺着看RunnableFuture声明:
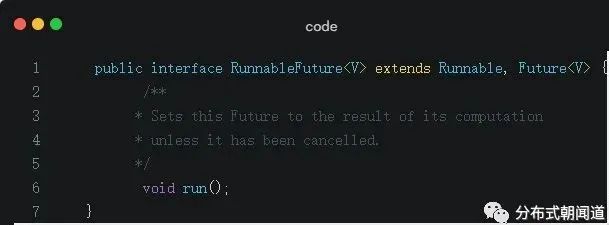
我们发现,最终RunnableFuture本质上是Runnable与Future的子类,也就是说它既可以作为Runnable被线程执行,又可以作为Future得到Callable的返回值。
根据里氏替换原则,可以认为FutureTask同时具备Runnable与Future的特性。
毫不夸张的说,FutureTask是事实上的Future接口的唯一实现类。
我们看一下FutureTask的构造器:
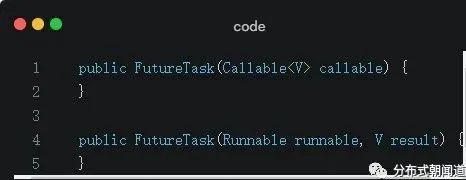
它提供了两个构造器,能够接收Callable or Runnable的实例。
用一句话概括,实战中,我们可以使用FutureTask替代Runnable与Future。
如何在实战中应用异步任务并发执行?
说了这么多,具体应该怎么用呢?
我们还是基于开头提到的“烧水泡茶”例子,用代码方式直观的展示,在实战中,面对多个任务并发执行的场景,应该如何去做。
首先需要一个异步线程池
根据理论部分的分析,我们得知,执行异步任务需要一个线程池,这里我们定义一个ThreadPoolExecutor
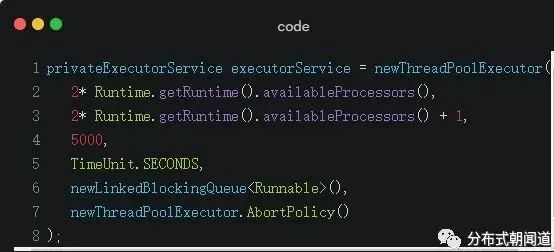
关于线程池的知识点不是我们本文讲述的重点,但是我在此处还是要重点提一个点:我们指定线程池的corePoolSize是有经验可循的:
CPU密集型任务:核心线程数=CPU核心数(或 核心线程数=CPU核心数+1)
I/O密集型任务:核心线程数=2*CPU核心数(或 核心线程数=CPU核心数/(1-阻塞系数))
混合型任务:核心线程数=(线程等待时间 / 线 程CPU时间+1)*CPU核心数
一般分布式后端开发场景多为I/O密集型,因此我们指定核心线程数为2倍的CPU核心数。
言归正传,我们再看一次并发泡茶的流程图,从上文中描述的业务流程我们已经知道,烧开水、清洗茶壶、清洗茶杯、准备茶叶 这几步是能够并发执行的,我们接着定义对应的任务执行Callable实现类。
定义准备工作(清洗茶壶、清洗茶杯、准备茶叶)Callable实现类
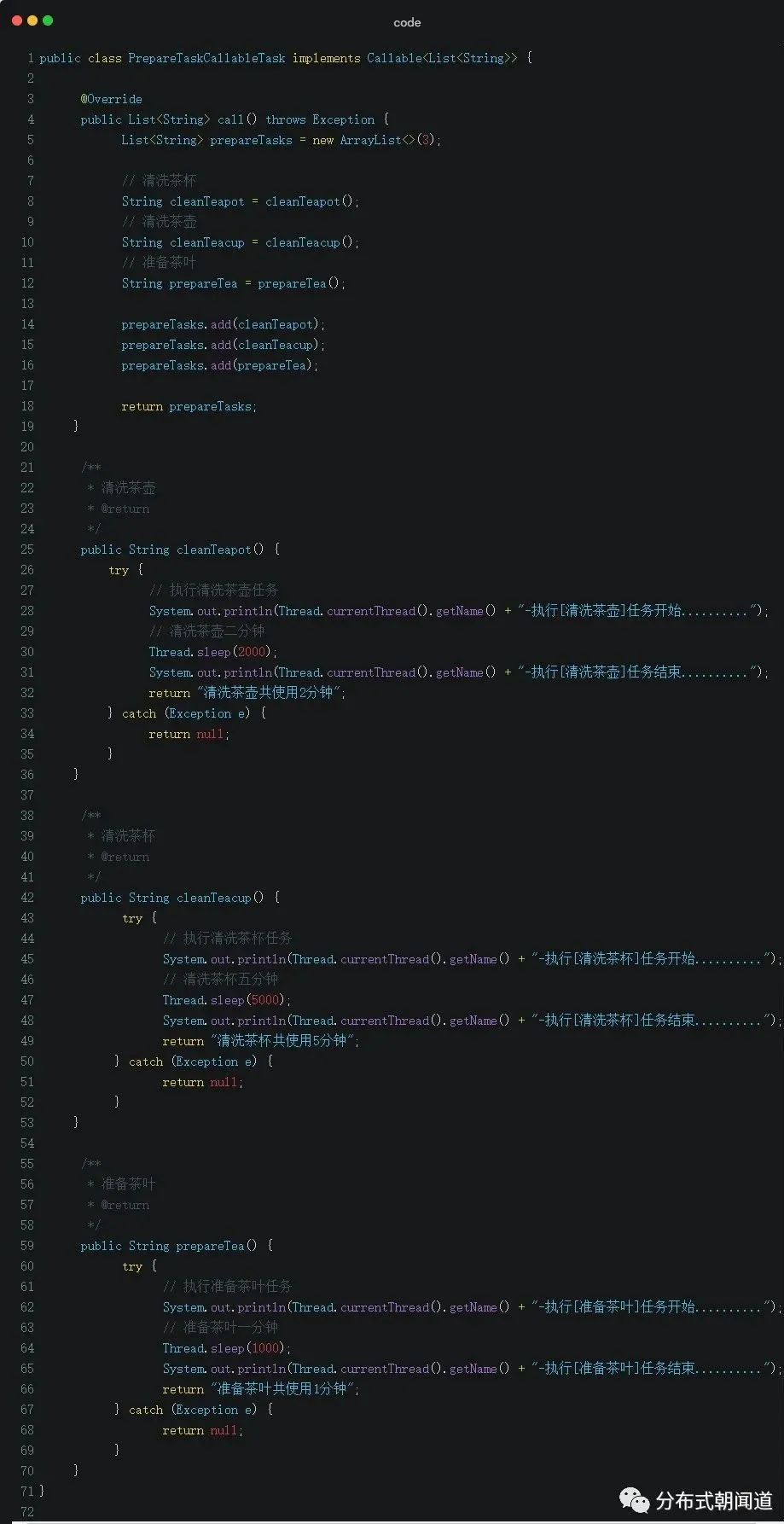
定义一个CleanTeapotCallableTask类,实现接口Callable,我们定义泛型为List<String>用以说明问题,将串行步骤执行结果封装到List中。
我们通过Thread.sleep对应的时长,借以模拟对应的步骤执行耗时。
实战中,泛型类型往往是远程的对象引用实例,我们只需要指定类型为对应对象的引用实例即可。
定义烧开水Callable实现类
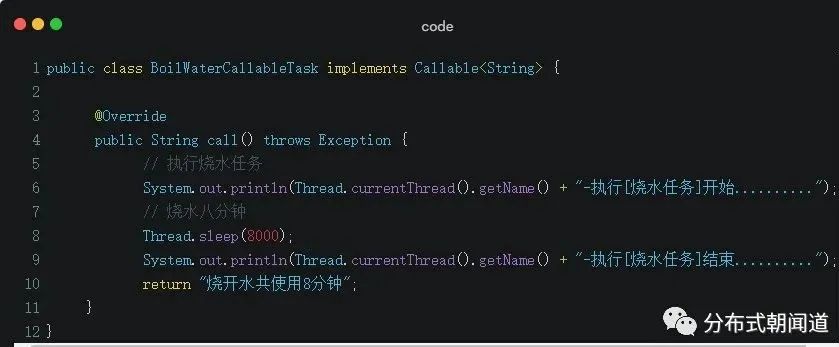
定义烧开水对应的异步任务Callable实现类,设置烧开水用时共需8分钟,并返回烧开水结果字符串。
通过线程池+callable+future执行异步任务
原材料已经准备完毕,接着就是我们的重头戏,通过线程池+callable+future执行异步任务。
直接看代码:
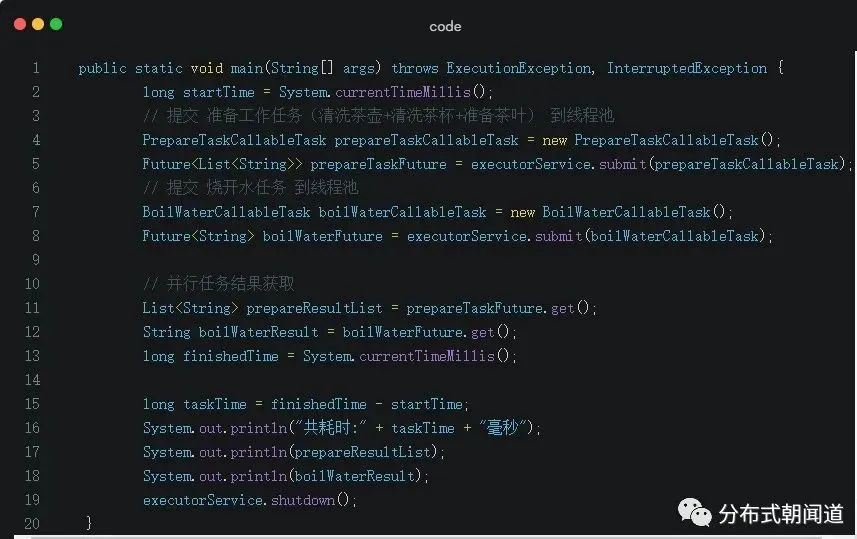
代码分析如下:
我们通过自定义的线程池并发提交了准备工作任务、烧开水任务到线程池;
通过对应任务提交返回的Future对象引用的get()方法并行获取任务执行结果;
最后打印任务执行总时间与任务执行结果。
运行结果如下:
pool-1-thread-1-执行[清洗茶壶]任务开始..........pool-1-thread-2-执行[烧水任务]开始..........pool-1-thread-1-执行[清洗茶壶]任务结束..........pool-1-thread-1-执行[清洗茶杯]任务开始..........pool-1-thread-1-执行[清洗茶杯]任务结束..........pool-1-thread-1-执行[准备茶叶]任务开始..........pool-1-thread-2-执行[烧水任务]结束..........pool-1-thread-1-执行[准备茶叶]任务结束..........共耗时:8002毫秒[清洗茶壶共使用2分钟, 清洗茶杯共使用5分钟, 准备茶叶共使用1分钟]烧开水共使用8分钟可以看到两个任务通过并发执行的方式,提升了执行效率。
思考:如果并行任务执行的时间不一样长会怎样?
上文中的“烧水泡茶”例子中,烧开水的时间 (8min)= 清洗茶壶 (2min) + 清洗茶杯 (5min) + 准备茶叶 (1min),也就是两个并行任务执行的时间刚好相同,
但是实际开发中,我们面临的往往是不同任务的并发执行,他们各自的执行时长也往往各不相同,放在这个例子中,如果准备工作中任意一个步骤耽误了时间,那么烧开水的时间就会小于准备时间。比如说,一下子来了很多客人,茶杯需要多准备几个,理想情况下,当水量不发生变更的情况下(每个人少喝两口),当开水烧好了,茶杯还是没有清洗干净。此时,流程图变成了这个样子:
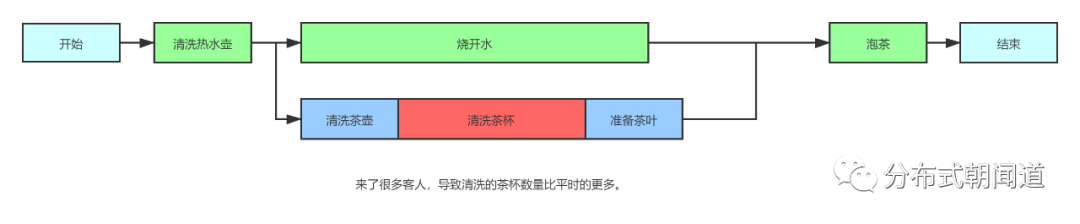
假设清洗茶杯的时间增加到了7分钟,则 准备时间 = 清洗茶壶 (2min) + 清洗茶杯 (7min) + 准备茶叶 (1min) = 10min 那么修改一下代码,再次执行,可以看到运行结果变成了:
pool-1-thread-1-执行[清洗茶壶]任务开始..........pool-1-thread-2-执行[烧水任务]开始..........pool-1-thread-1-执行[清洗茶壶]任务结束..........pool-1-thread-1-执行[清洗茶杯]任务开始..........pool-1-thread-2-执行[烧水任务]结束..........pool-1-thread-1-执行[清洗茶杯]任务结束..........pool-1-thread-1-执行[准备茶叶]任务开始..........pool-1-thread-1-执行[准备茶叶]任务结束..........共耗时:10002毫秒[清洗茶壶共使用2分钟, 清洗茶杯共使用7分钟, 准备茶叶共使用1分钟]烧开水共使用8分钟思考:多任务并发提交,如何提高运行效率?
总执行时长变为10分钟,那么我们就可以得出一个结论:
当存在多个并发任务执行时,最终消耗的时间为并发任务中执行时间最长的那个任务所花费的时间。
这个结论理解起来也很容易,多个任务并发执行,别的任务都执行完了,就剩下那个执行最慢的任务了,当最慢的任务执行完成的时候,全部任务也就执行完成了。这个过程有点类似“木桶原理”:
木桶能够承载的水量取决于最短的那条木板的长度,对应到我们的并发任务执行场景中来就是:要缩短并发任务执行的总时长,需要优先考虑优化执行最耗时的那个任务,根本上降低耗时任务执行所消耗的时间。
这也是我们这一小节题目的答案。
对串行流程采用多任务并发提交这个操作本身就已经大幅度提升了代码逻辑的执行效率;若想要进一步优化,我们应当优先关注多个任务中最耗时的那一个(或几个)任务,对其执行优化,能够显著提升整体任务流程的执行效率,缩短执行耗时。
思考:如果存在大量相同任务,如何使用并发任务提交来提升执行效率?
上文中提到的场景,执行步骤往往比较少量,能够通过流程化的编码实现。
可是现实总是多变的,有些场景下需要大批量提交多个任务,这种时候如果仍旧通过流程化的编码实现,代码本身会异常的冗余,可读性很低。
我们还是以本文的“烧水泡茶”的清洗茶杯流程为例:
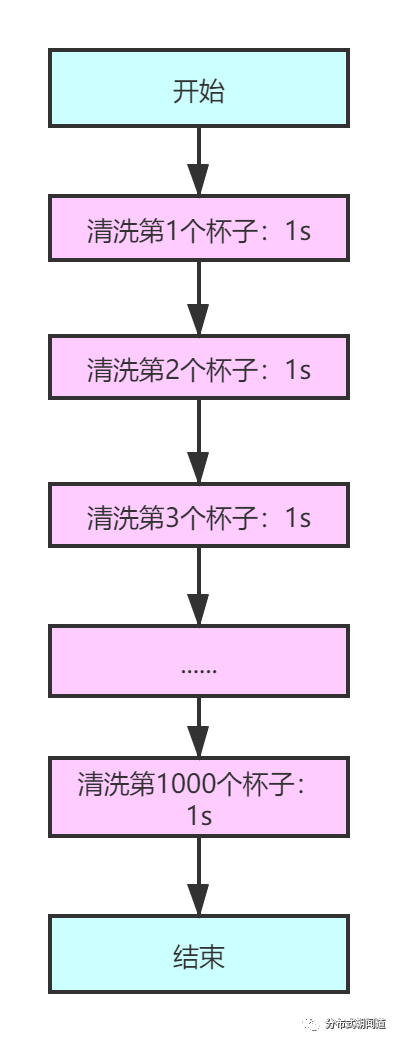
假设工人技法娴熟,洗一个茶杯只需要5秒,洗10个就是50秒,一个人能够执行得过来;
假设我们一次要洗1000个杯子,让一个人洗,需要耗费5000s,也就是约等于93分钟,接近一个半小时。想想也是一个恐怖的事情,假设这是一个大型的宴会,等到1000个杯子洗完,宴会都快结束了,宾客们还是没能喝上酒水。严重影响用户体验。
这种场景,对应到代码开发中,通常的做法就是通过循环调用,在一个线程中做大量重复工作:比如批量对账场景,在一个线程中对所有的商家执行对账,任务纯串行化,并发度完全没有,如果商家数量有几百万,耗时需要几个小时,效率很低。
这个时候,作为一个有追求的开发者,我们会下意识的想,是不是可以基于多线程并发任务提交,来并行执行这种大批量、重复度高的任务呢?
当然可以,就使用上文中的 线程池 + future + callable 就能够达到目的。
场景定义:多人同时洗杯子
我们就以多人洗杯子 这个业务场景进行案例实战模拟,为了缩短案例运行时间(本质上和现实没有区别),我们假设有1000个杯子,10个人洗,每人清洗100个杯子,每个杯子清洗时间平均耗时1秒,我们用并发任务批量提交的方式看一下相比于单人串行方式有多大的性能提升。
定义洗杯子Callable实现类CleanTeacup
我们还是编写一个洗杯子的Callable实现类CleanTeacupCallableTask:
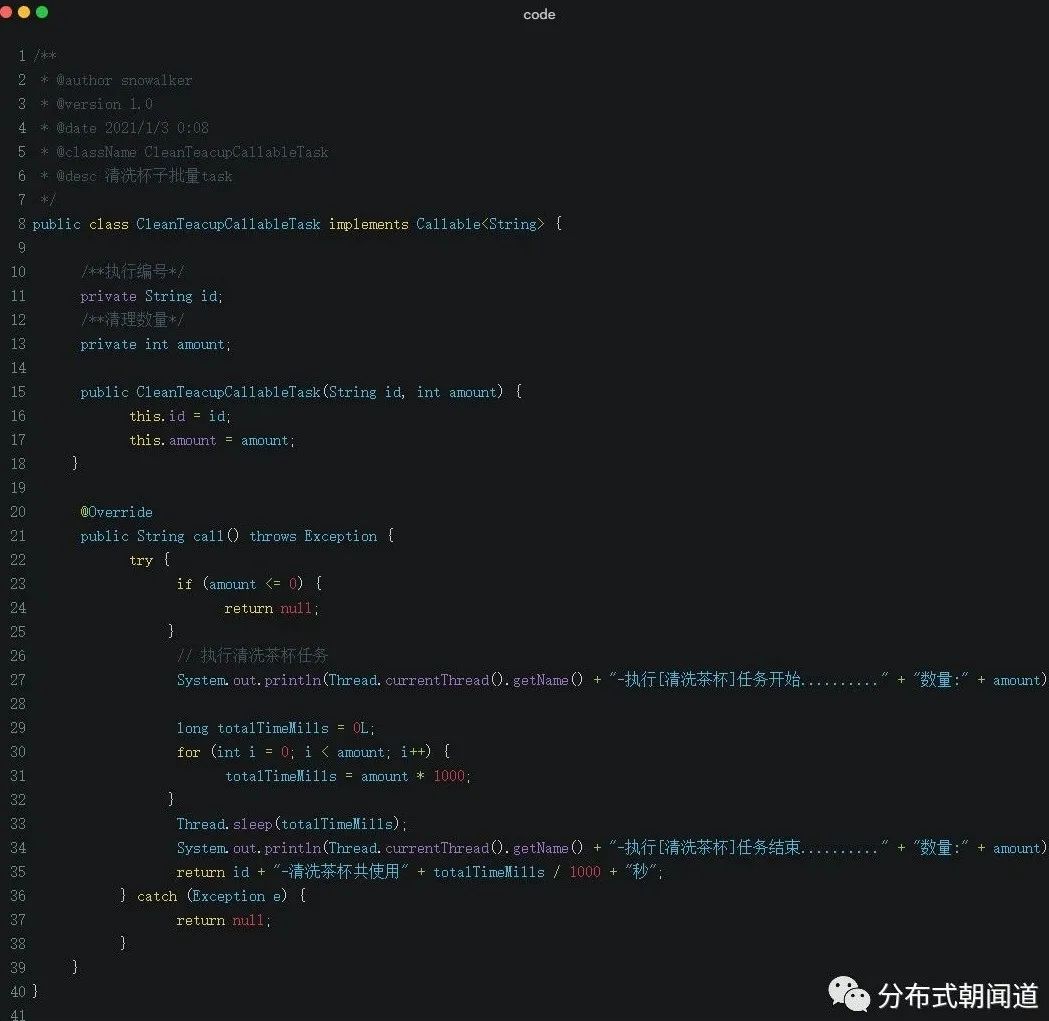
我们计划为每个工人分配一个茶杯清洗任务CleanTeacupCallableTask,它的构造方法接收两个参数:工人编号、需要清洗的茶杯数量。
则 每个工人需要花费的清洗总时长 = 单个茶杯清洗耗时 * 需要清洗的茶杯数量。
编写测试代码
我们接着编写测试代码,通过线程池批量提交茶杯并发清洗任务。
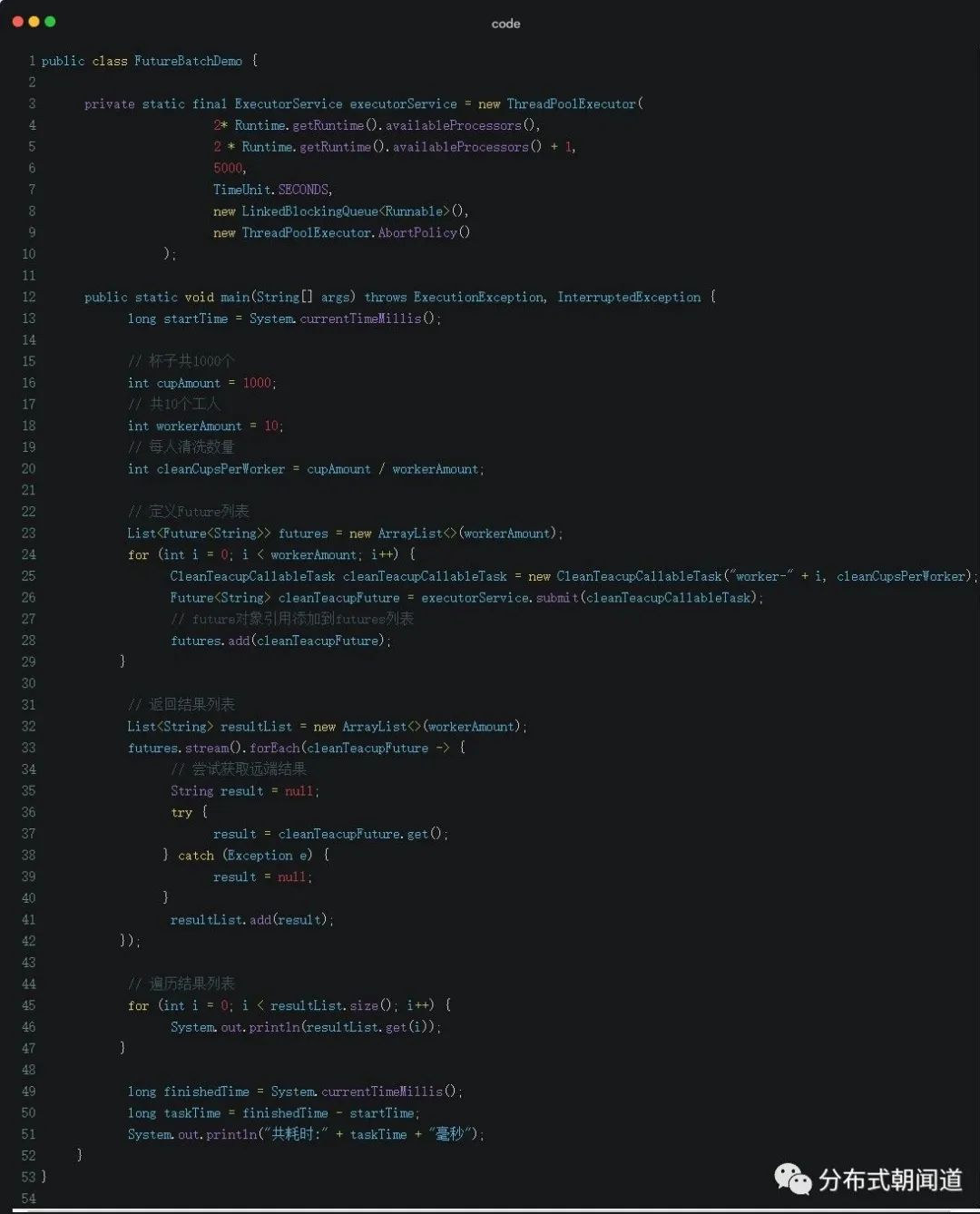
代码注释也比较详细,我们主要做了以下几件事情:
1.定义了待清洗的茶杯总数、清洗茶杯的工人数量,并计算得出每个工人需要清洗的茶杯数量;2.为每个工人提交一个茶杯清洗异步任务,并将返回的future对象引用封装到一个List中;3.遍历future列表,尝试获取远端的返回值,并将返回值封装到一个List中;4.打印结果并计算耗时。
多人同时洗杯子运行结果
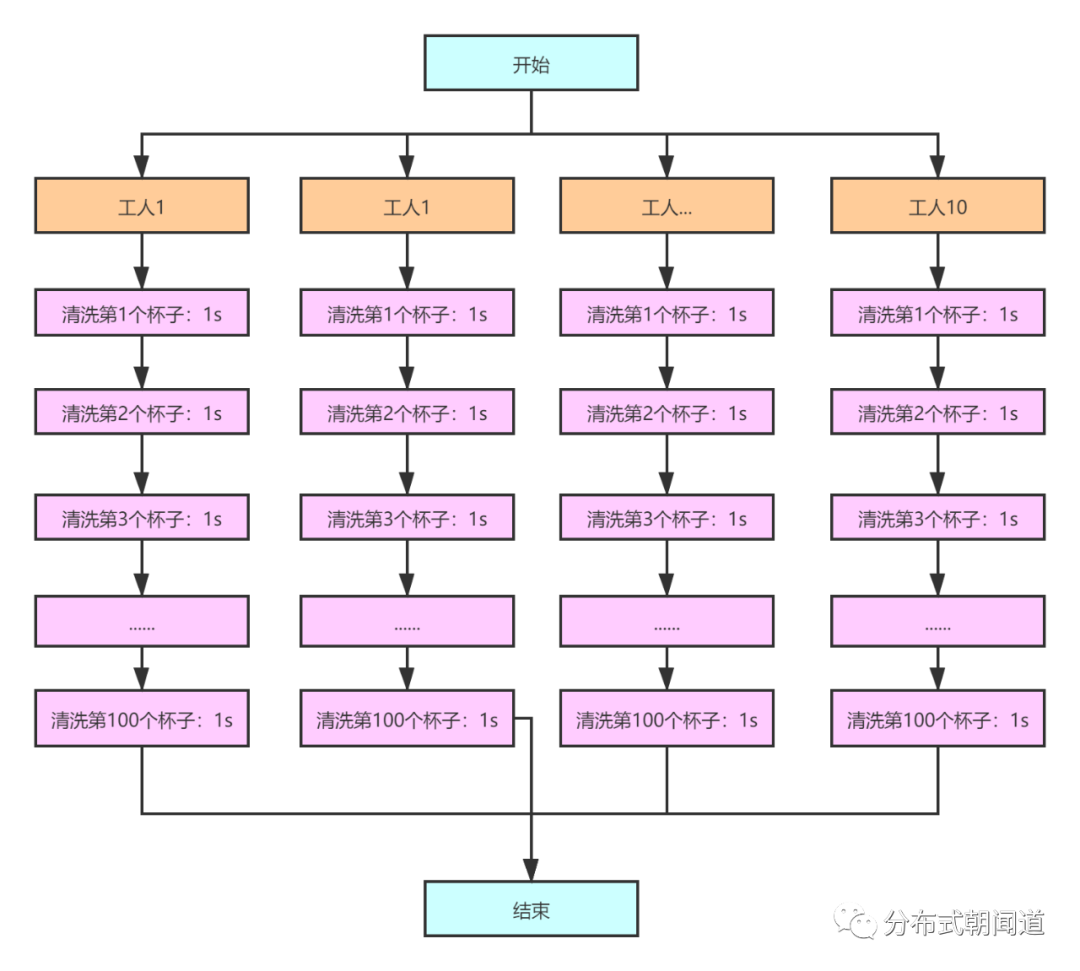
pool-1-thread-1-执行[清洗茶杯]任务开始..........数量:100pool-1-thread-5-执行[清洗茶杯]任务开始..........数量:100pool-1-thread-4-执行[清洗茶杯]任务开始..........数量:100pool-1-thread-3-执行[清洗茶杯]任务开始..........数量:100pool-1-thread-2-执行[清洗茶杯]任务开始..........数量:100pool-1-thread-7-执行[清洗茶杯]任务开始..........数量:100pool-1-thread-6-执行[清洗茶杯]任务开始..........数量:100pool-1-thread-9-执行[清洗茶杯]任务开始..........数量:100pool-1-thread-8-执行[清洗茶杯]任务开始..........数量:100pool-1-thread-10-执行[清洗茶杯]任务开始..........数量:100pool-1-thread-8-执行[清洗茶杯]任务结束..........数量:100pool-1-thread-3-执行[清洗茶杯]任务结束..........数量:100pool-1-thread-4-执行[清洗茶杯]任务结束..........数量:100pool-1-thread-9-执行[清洗茶杯]任务结束..........数量:100pool-1-thread-5-执行[清洗茶杯]任务结束..........数量:100pool-1-thread-2-执行[清洗茶杯]任务结束..........数量:100pool-1-thread-6-执行[清洗茶杯]任务结束..........数量:100pool-1-thread-7-执行[清洗茶杯]任务结束..........数量:100pool-1-thread-1-执行[清洗茶杯]任务结束..........数量:100pool-1-thread-10-执行[清洗茶杯]任务结束..........数量:100worker-0-清洗茶杯共使用100秒worker-1-清洗茶杯共使用100秒worker-2-清洗茶杯共使用100秒worker-3-清洗茶杯共使用100秒worker-4-清洗茶杯共使用100秒worker-5-清洗茶杯共使用100秒worker-6-清洗茶杯共使用100秒worker-7-清洗茶杯共使用100秒worker-8-清洗茶杯共使用100秒worker-9-清洗茶杯共使用100秒共耗时:100002毫秒可以看到,我们为10个工人分配了10个线程并发提交了10个茶杯清洗任务,10个工人同时开始了各自的茶杯清洗工作,最终当所有工人清洗完茶杯之后,共耗时100秒(PS:笔者使用的笔记本安装一颗8核心16线程CPU,能够同时开启16线程执行并行任务)。
这符合我们最初做的假设,即对于1000个杯子,10个工人并行清洗,每个杯子清洗平均耗时1s,只需要花费100秒;相同的工作由单个工人执行,则需要结结实实花费1000秒。通过并行方式,将任务执行效率提升了整整10倍,这是很直观的性能提升。
我们通过流程图展示这个具体的过程:
单个工人串行清洗杯子
多个工人并发清洗杯子
上文中,我们通过“烧水泡茶”、“多人清洗杯子”等案例,讲解了多步骤并发任务提交 以及 批量任务并发提交 的思路及代码实现,均达到了目的。
但是实际开发中,我们发现有的同学初衷是想通过并发任务提交方式提升系统执行效率,但由于“学艺不精”或者“一时糊涂”,使用了错误的方式,将并发代码最终通过串行方式运行了,并没能实现通过多线程方式提升业务逻辑运行效率的目的。
我们此处就看一下常见的错误使用方式是如何“巧夺天工”地将代码串行化的,我们还是以“烧水泡茶”案例来说明。
具体的任务编写代码没有什么问题,问题出在并发任务提交的逻辑编写上,错误使用方式的代码是这么写的:
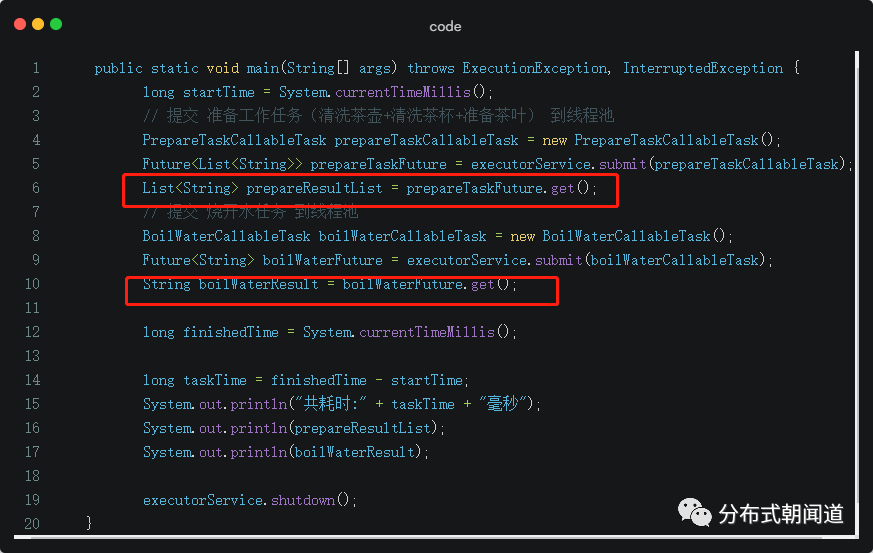
对比正确的写法,有没有发现问题出在哪儿?
相信聪明的你已经看出来了(笔者在图中也标记出来了),错误的写法是针对每个任务的提交结果分别进行了get()操作,当A任务提交之后就通过get()尝试获取结果,阻塞了主线程;当A任务执行结果获取到之后再提交B任务,并通过get()尝试获取结果,最终执行的结果如下:
pool-1-thread-1-执行[清洗茶壶]任务开始..........pool-1-thread-1-执行[清洗茶壶]任务结束..........pool-1-thread-1-执行[清洗茶杯]任务开始..........pool-1-thread-1-执行[清洗茶杯]任务结束..........pool-1-thread-1-执行[准备茶叶]任务开始..........pool-1-thread-1-执行[准备茶叶]任务结束..........pool-1-thread-2-执行[烧水任务]开始..........pool-1-thread-2-执行[烧水任务]结束..........共耗时:18003毫秒[清洗茶壶共使用2分钟, 清洗茶杯共使用7分钟, 准备茶叶共使用1分钟]烧开水共使用8分钟可以看到,两个任务执行时长 = 准备工作8分钟 + 烧开水8分钟 = 16分钟!
也就是说,这种错误的使用方式,将并发任务本质上写成了串行任务!(笔者在实际开发过程中就不止一次看到过这种写法,一时间惊为天人)如果是对实效性要求很高的业务场景,后果是很严重的(背锅警告)!尤其是实时对账、实时多接口查询等业务场景下,将大幅度提升系统的单次调用执行时长,严重影响接口RT;如果是2C业务,将直接影响到用户体验。
反思及总结
本文篇幅较长,内容虽看似简单,但暗藏着玄机。
我们通过一个“烧水泡茶”的例子引出并发任务提交的场景,并展示了代码具体应当如何编写。
随后,基于批量任务执行的场景,又给出了对应的代码案例,对于离线任务批处理,在线实时批量调用等场景,我们发现,通过线程池异步并发任务批量执行的方式能够大幅度提升业务执行效率。
文章最后,我们给出了一个并发任务编写的“bad case”,这警示我们:
对于技术细节,要尽量知其然,知其所以然。只知道皮毛很容易用错,尤其对于多线程的技术点,一旦用错,极易引发严重的后果。
文章中提供了大量的图示和运行结果展示,希望能够通过笔者笨拙的描述,对你在实战中运用 线程池+future+callable 方式,进行异步任务执行逻辑的编写有所帮助。
下期预告
你以为到这里就结束了?
熟悉笔者风格的同学马上就意识到,问题没有这么简单。
在Java8中,更新了新的异步任务执行框架--CompletableFuture,它提供了更为丰富的并发任务组合提交、回调等特性。
在这个技术日益内卷的时代,对底层干饭型程序员,唯有学习才能破局。那么我们下期就通过CompletableFuture继续讲解更多的异步任务并发执行的姿势,让我们不见不散。















 307
307











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









