







简介:《C语言精彩编程百例》一书通过100个实例深入探讨了C语言的核心概念和高级特性,附带源码,方便读者学习和实践。书中涵盖了数据类型、变量和常量、运算符、流程控制、函数、数组与指针、结构体与联合体、预处理器、文件操作以及错误处理等关键知识点,并通过实例代码巩固理论知识和提升编程技能。本书适合初学者和有经验的开发者,强调实践和源码分析的重要性。 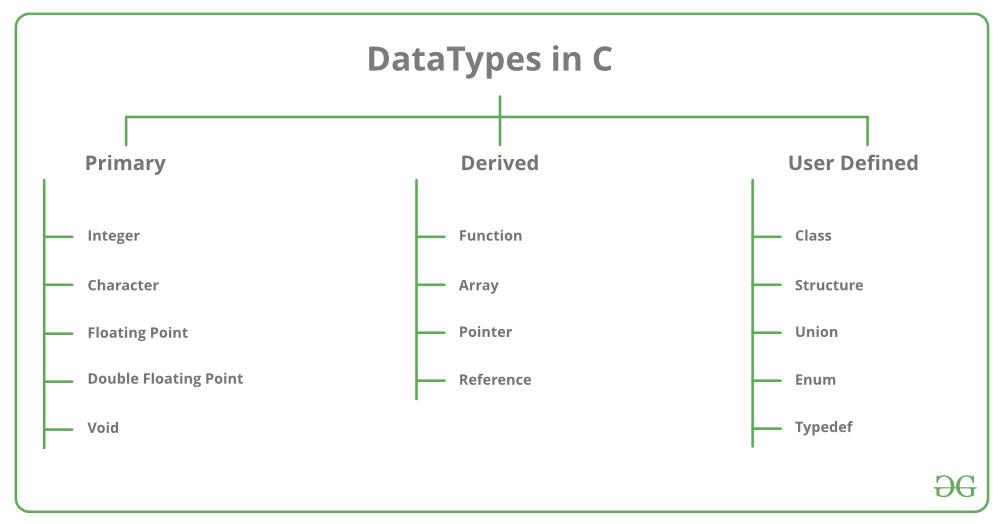
1. C语言基础概念和语法结构
1.1 C语言概述
C语言是一种广泛使用的计算机编程语言,它的设计哲学注重简洁和表达能力,允许程序员编写结构化、高效且可移植的代码。作为初学者了解C语言的基础概念和语法结构是学习旅程的第一步。
1.2 基本语法
C语言的程序结构从头文件包含开始,如 #include <stdio.h> ,用于输入输出功能。程序的主体是由函数构成的,通常包含一个主函数 main() 作为程序的入口点。
#include <stdio.h>
int main() {
printf("Hello, World!\n");
return 0;
}
1.3 变量和数据类型
在C语言中,变量是用于存储数据值的基本单位,必须先声明其类型和名称。基本数据类型包括整型( int )、浮点型( float 和 double )、字符型( char )等。
int number = 10; // 整型变量
double pi = 3.14159; // 浮点型变量
char letter = 'A'; // 字符型变量
了解这些基本概念后,开发者可以开始构建更复杂的程序逻辑,并逐步深入学习C语言的高级特性和应用。
2. C语言高级特性应用
2.1 高级数据结构
2.1.1 链表
链表是一种常见的数据结构,它由一系列节点组成,每个节点包含数据和指向下一个节点的指针。链表在C语言中的实现依赖于结构体和指针。
struct Node {
int data;
struct Node* next;
};
struct Node* head = NULL;
// 创建新节点
struct Node* createNode(int data) {
struct Node* newNode = (struct Node*)malloc(sizeof(struct Node));
if (newNode == NULL) {
// 内存分配失败处理
exit(1);
}
newNode->data = data;
newNode->next = NULL;
return newNode;
}
在创建链表时,首先分配内存给一个节点,然后将数据赋值给该节点。如果要将一个节点添加到链表的末尾,我们需要遍历整个链表,找到最后一个节点并将其next指针指向新创建的节点。
链表的搜索、插入和删除操作在最坏情况下需要O(n)的时间复杂度,其中n是链表中的节点数。相比于数组,链表在插入和删除操作中更有优势,因为这些操作不需要移动其他元素。
2.1.2 栈和队列
栈是一种后进先出(LIFO)的数据结构,可以通过数组或链表实现。栈的基本操作包括 push (入栈)、 pop (出栈)、 peek (查看栈顶元素)等。
#define MAXSIZE 100
int stack[MAXSIZE];
int top = -1;
void push(int data) {
if (top == MAXSIZE - 1) {
// 栈满
} else {
top++;
stack[top] = data;
}
}
int pop() {
if (top == -1) {
// 栈空
return -1;
} else {
int data = stack[top];
top--;
return data;
}
}
队列是一种先进先出(FIFO)的数据结构,其基本操作包括 enqueue (入队)和 dequeue (出队)。可以使用循环数组或链表来实现队列。
struct Queue {
struct Node* front;
struct Node* rear;
};
void enqueue(int data) {
struct Node* newNode = createNode(data);
if (q->rear == NULL) {
q->front = q->rear = newNode;
} else {
q->rear->next = newNode;
q->rear = newNode;
}
}
int dequeue() {
if (q->front == NULL) {
// 队列为空
return -1;
}
struct Node* temp = q->front;
int data = temp->data;
q->front = q->front->next;
if (q->front == NULL) {
q->rear = NULL;
}
free(temp);
return data;
}
栈和队列广泛应用于程序设计的许多方面,例如递归的实现、算法中各种搜索和排序问题的解决、内存管理等。
2.1.3 树和图
树是一种层次结构,由节点组成,每个节点都连接到零个或多个子节点。二叉树是树的一种特殊情况,每个节点最多有两个子节点。图是一种复杂的非线性数据结构,由节点(顶点)和连接这些节点的边组成。
树和图的实现通常涉及到递归和循环结构,对于图来说,深度优先搜索(DFS)和广度优先搜索(BFS)是两种基本的遍历方法。
2.2 模块化编程
2.2.1 模块化设计原则
模块化编程是将大型程序分解成小的、易于管理的模块的过程。模块化设计原则包括单一职责、接口清晰、模块独立和重用性。
单一职责原则要求一个模块只负责一项任务;清晰的接口意味着模块之间的交互应该简单明了;模块独立是模块化设计的核心,意味着修改一个模块不应该影响到其他模块;重用性强调在不同的上下文中可以使用相同的模块。
2.2.2 模块化编程实践
在C语言中,模块通常是通过函数和文件组织起来的。一个文件通常包含一组相关的函数,这些函数形成了一个模块。
例如,将与链表操作相关的所有函数放在一个名为 list.c 的文件中,而声明这些函数的头文件 list.h 则提供给其他需要使用链表操作的模块。
2.3 内存管理
2.3.1 动态内存分配
动态内存分配允许程序在运行时分配内存空间,其主要函数包括 malloc 、 calloc 、 realloc 和 free 。
void* malloc(size_t size);
void* calloc(size_t nmemb, size_t size);
void* realloc(void* ptr, size_t size);
void free(void* ptr);
malloc 函数分配指定字节的内存; calloc 函数分配内存,并将内存中的所有字节初始化为零; realloc 函数更改之前分配的内存块的大小; free 函数释放之前通过动态内存分配函数分配的内存。
2.3.2 内存泄漏的检测和预防
内存泄漏是指程序在申请内存后未能正确释放,导致这部分内存永远无法再次使用。为了避免内存泄漏,需要仔细管理每个 malloc 、 calloc 或 realloc 调用的 free 操作。
可以使用工具如Valgrind检测内存泄漏。此外,在编码时应当遵循最佳实践,比如使用智能指针(如果在使用C++)、记录动态内存分配的位置、在每个函数中检查分配的内存是否已释放等。
2.4 函数指针的使用
函数指针指向一个函数的地址,可以在运行时决定调用哪个函数,这在设计回调函数或命令模式时非常有用。
int (*funcPtr)(int, int);
int add(int a, int b) {
return a + b;
}
int subtract(int a, int b) {
return a - b;
}
funcPtr = add;
int result = funcPtr(5, 3);
// 结果为8
funcPtr = subtract;
result = funcPtr(5, 3);
// 结果为2
函数指针的使用使得程序能够更加灵活,在某些情况下可以提高效率,特别是在处理事件驱动编程或者实现复杂的控制逻辑时。
总结起来,高级数据结构、模块化编程、内存管理、函数指针等C语言的高级特性是构建高效、可维护和可扩展的C语言程序的关键。掌握这些特性对于任何希望深入学习C语言的开发者都是必不可少的。
3. C语言基本数据类型使用
3.1 整型数据类型
在编程语言中,整型数据类型是用于存储整数的基础数据类型,它包含了一系列的数值类型,用于存放没有小数部分的数字。C语言提供了多种整型数据类型以满足不同场景的需要。
3.1.1 整型变量的定义和初始化
在C语言中,常见的整型变量包括 int 、 short 、 long 以及无符号整型 unsigned 。这些类型的变量定义和初始化可以按照如下方式进行:
#include <stdio.h>
int main() {
int integerVar = 10; // 定义一个int类型的变量并初始化为10
short shortVar = 2; // 定义一个short类型的变量并初始化为2
long longVar = ***L; // 定义一个long类型的变量并初始化为***,后缀L表示这是一个long型常量
unsigned int unsignedVar = 12345u; // 定义一个unsigned int类型的变量并初始化为12345,后缀u表示这是一个unsigned型常量
printf("Integer: %d\n", integerVar);
printf("Short: %hd\n", shortVar);
printf("Long: %ld\n", longVar);
printf("Unsigned Integer: %u\n", unsignedVar);
return 0;
}
在这段代码中,我们声明了几种不同类型的整型变量,并初始化它们。 %d 、 %hd 、 %ld 和 %u 是格式化输出指令,用于输出 int 、 short 、 long 和 unsigned int 类型的变量。
3.1.2 整型变量的运算和转换
整型变量可以参与各种算术运算,包括加减乘除和取模等。同时,在不同整型数据类型之间,也可以进行强制类型转换。
#include <stdio.h>
int main() {
int a = 10;
short b = 5;
long c = 100;
unsigned int d = 20;
// 算术运算
int sum = a + b; // 结果为15
long product = a * c; // 结果为1000
// 强制类型转换
int castedShort = (int) b; // 将short转换为int类型
short castedInt = (short) a; // 将int转换为short类型
unsigned int castedLong = (unsigned int) c; // 将long转换为unsigned int类型
printf("Sum: %d\n", sum);
printf("Product: %ld\n", product);
printf("Casted from short to int: %d\n", castedShort);
printf("Casted from int to short: %hd\n", castedInt);
printf("Casted from long to unsigned int: %u\n", castedLong);
return 0;
}
在上述代码中,进行了整型变量之间的加法和乘法运算,并展示了不同整型数据类型之间的强制类型转换。需要注意的是,当进行类型转换时,如果超出原类型的表示范围,可能会导致数据丢失或溢出。
3.2 浮点型数据类型
浮点型数据类型用于处理带有小数点的数值。C语言标准库中的浮点型主要包括 float 和 double 两种类型。
3.2.1 浮点型变量的定义和初始化
浮点型变量的定义和初始化通常遵循以下语法结构:
#include <stdio.h>
int main() {
float floatVar = 3.14f; // 定义一个float类型的变量并初始化为3.14,后缀f表示这是一个float型常量
double doubleVar = 3.***; // 定义一个double类型的变量并初始化为3.***
printf("Float: %f\n", floatVar);
printf("Double: %lf\n", doubleVar);
return 0;
}
这里使用 %f 和 %lf 分别对 float 和 double 类型的变量进行格式化输出。
3.2.2 浮点型变量的运算和精度问题
浮点型变量可以进行加减乘除等运算,但需要注意的是,由于计算机表示浮点数的方式(IEEE 754标准)限制,会出现精度丢失问题。
#include <stdio.h>
int main() {
float a = 0.1f;
double b = 0.1;
double sum = a + b;
printf("Sum of 0.1f and 0.1: %lf\n", sum);
// 输出可能会有微小的误差,由于精度限制
return 0;
}
在这个例子中,我们尝试将 float 和 double 类型的变量进行加法运算,然后输出。由于精度限制,输出可能会略不同于实际的数学结果,这在进行高精度浮点数计算时需要特别注意。因此,在处理金融和科学计算领域时,可能会用到 long double 或者特别处理方式来减少误差。
以上是第三章关于C语言基本数据类型的介绍。通过本章内容,读者应该能够理解和掌握在C语言编程中如何使用基本数据类型,以及它们的初始化、运算、转换和精度问题。这些基础知识是后续学习更高级编程概念和技巧的基石。
4. 变量和常量的使用
4.1 变量的声明和定义
4.1.1 变量的作用域和生命周期
在C语言中,变量的声明是告诉编译器该变量的类型和名称,而定义则是为变量分配内存空间。变量的作用域决定了变量在程序中的可见范围和生命周期。
作用域的种类 : - 局部变量 :在函数或代码块内部声明的变量,其作用域限制在该函数或代码块内,生命周期从声明点开始,到代码块执行完毕结束。 - 全局变量 :在函数外部声明的变量,其作用域是全局的,可以在程序的任何地方被访问,生命周期从声明点开始,直到程序结束。
int globalVar = 10; // 全局变量,声明并定义
void function() {
int localVar = 5; // 局部变量,声明并定义
// 使用局部变量
}
int main() {
function(); // 调用函数,局部变量在函数执行时创建,执行完毕后销毁
// 可以使用全局变量
return 0;
}
在上例中, globalVar 是一个全局变量,它可以在 main 函数和 function 函数中被访问。 localVar 是一个局部变量,只能在 function 函数内部访问,一旦 function 执行完毕, localVar 将不再存在。
4.1.2 全局变量和局部变量
全局变量和局部变量的区别 : 1. 作用范围 :全局变量在整个程序中都可访问,而局部变量只能在其定义的函数或代码块内访问。 2. 生命周期 :全局变量在程序开始执行时创建,在程序结束时销毁。局部变量的生命周期从声明开始到其所在函数或代码块执行结束。 3. 存储位置 :全局变量存储在全局数据区,而局部变量存储在栈区。
使用注意事项 : - 避免不必要的全局变量使用,过多的全局变量会使得程序的各个部分耦合度过高,难以维护和重用。 - 局部变量可以隐藏同名的全局变量,这种情况下,局部变量会屏蔽全局变量。 - 局部变量在声明时应当初始化,防止使用未初始化的值。 - 在设计时应当尽可能缩小变量的作用域,减少潜在的作用域冲突。
全局变量和局部变量是编程中常用的概念,理解并合理使用它们对于编写可维护、可扩展的代码至关重要。在实际开发中,应当根据变量的使用需求和上下文来决定是使用全局变量还是局部变量。
5. 运算符与表达式的构建
5.1 算术运算符和表达式
5.1.1 算术运算符的使用
算术运算符是编程中最为常见的基础概念,C语言中的算术运算符包括加(+)、减(-)、乘(*)、除(/)和求余(%)。这些运算符可以用来执行基本的算术计算,其中加、减、乘、除运算符与数学上的使用相同,求余运算符用于取得两个整数相除后的余数。
例如,下面的代码段演示了基本的算术运算符的使用:
#include <stdio.h>
int main() {
int a = 10;
int b = 3;
// 加法
printf("加法运算结果:%d + %d = %d\n", a, b, a + b);
// 减法
printf("减法运算结果:%d - %d = %d\n", a, b, a - b);
// 乘法
printf("乘法运算结果:%d * %d = %d\n", a, b, a * b);
// 除法
printf("除法运算结果:%d / %d = %d\n", a, b, a / b);
// 求余
printf("求余运算结果:%d %% %d = %d\n", a, b, a % b);
return 0;
}
执行逻辑:这段代码首先包含了头文件 stdio.h ,随后在 main 函数中定义了两个整型变量 a 和 b 并初始化为10和3。之后使用 printf 函数输出了使用加、减、乘、除和求余运算符的计算结果。
参数说明: a 和 b 是整型变量, a + b 、 a - b 、 a * b 、 a / b 和 a % b 分别表示对这两个变量进行加法、减法、乘法、除法和求余运算。
逻辑分析:当涉及到整型数的除法时,结果仍然是整数,小数部分会被舍去(称为整数除法)。在求余运算中,使用 % 符号来获得两数相除的余数。这在编写需要进行模运算的程序时特别有用。
5.1.2 表达式的优先级和结合性
在C语言中,当一个表达式包含多个运算符时,运算符的优先级决定了运算的顺序。例如,乘法和除法的优先级高于加法和减法,因此在没有括号的情况下,乘除运算先于加减运算执行。
结合性定义了当优先级相同的情况下运算的顺序,算术运算符具有从左到右的结合性,意味着如果表达式中有多个优先级相同的运算符,计算是从左向右进行的。
举个例子:
int result = 6 * 2 + 2 * 3; // 先计算 6*2 和 2*3,然后相加,结果为 20
在没有括号的情况下,乘法先于加法执行,因为乘法运算符的优先级高于加法运算符。
5.2 关系和逻辑运算符
5.2.1 关系运算符的使用
关系运算符用于比较两个值之间的关系,包括大于(>)、小于(<)、大于等于(>=)、小于等于(<=)、等于(==)和不等于(!=)。它们的结果是逻辑值 true (1)或 false (0)。
下面是一个使用关系运算符的示例代码:
#include <stdio.h>
int main() {
int num1 = 10;
int num2 = 20;
if (num1 < num2) {
printf("num1小于num2\n");
}
if (num1 > num2) {
printf("num1大于num2\n");
} else if (num1 == num2) {
printf("num1等于num2\n");
} else {
printf("以上条件均不满足\n");
}
return 0;
}
执行逻辑:代码首先定义了两个整数变量 num1 和 num2 ,然后使用 if 语句检查它们之间的关系。第一个 if 语句检查 num1 是否小于 num2 ,第二个 if 语句检查 num1 是否大于 num2 ,如果不是,则检查是否等于 num2 。
参数说明:逻辑条件 num1 < num2 和 num1 > num2 使用了关系运算符,而 num1 == num2 使用了等于运算符来检查两个变量是否相等。
逻辑分析:关系运算符在条件语句和循环控制中非常有用,因为它们提供了决策的基础。在这个例子中,只有第一个条件满足,所以只打印了"num1小于num2"。
5.2.2 逻辑运算符的使用
逻辑运算符用于连接多个条件,决定程序中的执行路径。C语言中逻辑运算符包括逻辑与(&&)、逻辑或(||)和逻辑非(!)。逻辑与运算符当两边的条件都为真时结果才为真,逻辑或运算符只要两边的条件中有一个为真结果就为真,逻辑非运算符则是对条件的真假进行取反。
下面的代码演示了逻辑运算符的使用:
#include <stdio.h>
int main() {
int age = 20;
int height = 180;
// 逻辑与运算符
if (age >= 18 && height >= 175) {
printf("年龄大于等于18岁且身高大于等于175cm\n");
}
// 逻辑或运算符
if (age < 18 || height < 160) {
printf("年龄小于18岁或身高小于160cm\n");
}
// 逻辑非运算符
if (!(age >= 18 && height >= 175)) {
printf("年龄小于18岁或身高小于175cm\n");
}
return 0;
}
执行逻辑:代码定义了两个变量 age 和 height ,然后使用逻辑运算符来检查不同的条件组合。
参数说明:在第一个 if 语句中,使用了逻辑与运算符(&&),要求两个条件都满足(年龄大于等于18岁且身高大于等于175cm)。第二个 if 语句使用了逻辑或运算符(||),表示满足其中任一条件即可。第三个 if 语句展示了逻辑非运算符(!),它会反转后面的条件表达式的逻辑值。
逻辑分析:逻辑运算符允许我们在一个 if 语句中检查多个条件,使程序的决策过程更加灵活和强大。通过逻辑非运算符的使用,我们还能很容易地检查一个条件是否不满足。
在上述的示例中,我们学习了如何使用算术运算符、表达式、关系运算符以及逻辑运算符来执行基本的计算和决策。这些基础概念对于理解更复杂的编程概念至关重要,它们是构建可靠程序的基石。在之后的章节中,我们将深入探讨更高级的编程结构和概念。
6. 流程控制语句的运用
在软件开发中,流程控制是编写有效和高效程序的关键部分。它涉及到使用特定的语句来决定程序的执行路径。本章节将深入探讨C语言中流程控制语句的运用,包括条件判断和循环控制语句,这将帮助读者编写出结构清晰、逻辑严密的代码。
6.1 条件判断语句
条件判断语句是根据表达式的真假来选择执行不同的代码分支。在C语言中,最常见的条件判断语句是 if-else 结构和 switch-case 结构。
6.1.1 if-else结构
if-else 结构是条件判断的基础,它允许根据条件表达式的评估结果来执行不同的代码块。基础的 if 语句如下所示:
if (condition) {
// 条件为真时执行的代码块
} else {
// 条件为假时执行的代码块
}
if 语句可以嵌套使用,以处理更复杂的逻辑条件:
if (condition1) {
// 条件1为真时执行的代码块
} else if (condition2) {
// 条件2为真时执行的代码块
} else {
// 条件1和条件2都不为真时执行的代码块
}
6.1.2 switch-case结构
switch-case 结构是另一种条件判断语句,它根据变量的值执行对应的 case 分支。它在处理多个固定选项时比 if-else 结构更加清晰。
switch (variable) {
case value1:
// 当variable等于value1时执行的代码块
break;
case value2:
// 当variable等于value2时执行的代码块
break;
// 可以有更多的case分支
default:
// 当variable的值与所有case都不匹配时执行的代码块
}
break 语句用于退出 switch 结构,避免执行下一个 case 分支。如果缺少 break ,将会发生所谓的“case穿透”。
6.2 循环控制语句
循环控制语句用于重复执行代码块,直到满足特定条件为止。在C语言中,最常用的循环控制语句有 for 循环、 while 循环和 do-while 循环。
6.2.1 for循环的使用
for 循环适合在已知循环次数的情况下使用。它的结构如下:
for (initialization; condition; update) {
// 循环体
}
initialization 是初始化循环控制变量, condition 是循环条件, update 是每次循环后更新控制变量的方式。
6.2.2 while和do-while循环的使用
while 循环在条件为真时反复执行循环体。如果循环条件从一开始就不成立,循环体将不会执行:
while (condition) {
// 循环体
}
而 do-while 循环至少执行一次循环体,即使条件一开始就不成立:
do {
// 循环体
} while (condition);
在本章中,我们学习了C语言中流程控制语句的使用方法,这将有助于编写更加灵活和高效的程序。下一章我们将探讨函数的定义、调用、参数传递和返回值。
简介:《C语言精彩编程百例》一书通过100个实例深入探讨了C语言的核心概念和高级特性,附带源码,方便读者学习和实践。书中涵盖了数据类型、变量和常量、运算符、流程控制、函数、数组与指针、结构体与联合体、预处理器、文件操作以及错误处理等关键知识点,并通过实例代码巩固理论知识和提升编程技能。本书适合初学者和有经验的开发者,强调实践和源码分析的重要性。















 480
480

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









