






一、聚类模型简述。
聚类算法属于无监督学习,样本标记信息未知,通过学习数据本身的内在性质和规律,试图将数据集划分为若干个相似子集。
聚类模型区别于分类模型的主要有一下几点:
1. 数据集无标注,我不知道数据具体有几类,而是通过机器聚类告诉我这个数据集可以有几个类属性。
2. 在学习过程中无需调参。
3. 聚类过程是根据样本数据自身的性质聚合的。
二、 聚类算法流程
聚类算法的处理流程和分类算法大致相似:
1. 数据收集
2. 数据预处理阶段
3. 聚类模型聚类阶段
4. 模型调参
三、 K-Means算法
1. 算法伪码表示:
数据集d(样本表示为 D1, D2,..., Dn)
人为选取K值(K < n):
随机选择K个样本点当做初始聚类的簇中心,并记录K个坐标(M1,M2,..., Mk )
伪代码如下:
loop1:
loop2 样本 D1 to Dn:
loop3 簇心M1 to Mk:
计算 distance = Distance(Di , Mj)
选择 min(distance )最小的Mj 作为对样本 Si的分类
loop3 end
loop2 end (所有样本点完成分类)
例如:
以计算平均值(means)的方式重新计算蔟中心 记录新聚簇中心(Mn1, Mn2,..., MnK)
比较 新蔟心坐标 和 旧簇心坐标:
if 新蔟心坐标 == 旧簇心坐标
loop1 end
else:
下次循环的簇心 = 新簇心坐标
loop1 continue
2. 算法过程描述
K-Means算法过程大致为:
① 人手动选择K值(期望模型聚类出几个结果)
② 在样本点平面内,随机选取K个样本点, 作为初始聚簇中心
③ 遍历数据集每个样本点, 计算样本点到K个聚簇中心的距离
④ 选择距离最小的聚簇中心, 将此样本点归到这个蔟中心中
⑤ 在所有样本遍历完后, 遍历K聚簇中心,计算这K个簇心向量的均值,记录当前均值坐标,当做下一次聚类的簇心
⑥ 比较 新聚蔟中心 == 旧聚蔟中心?;
⑦ 当 ⑥ 成立时,算法结束;反之, 重复执行前面6步,直至聚蔟中心不在发生变化,算法结束
3. 示例
假设有如下样本点
|
样本点
|
坐标
|
|
x1
|
(1,2)
|
|
x2
|
(3, 5)
|
|
x3
|
(2, 4)
|
|
x4
|
(11, 22)
|
|
x5
|
(13, 15)
|
| x6 |
(30, 20)
|
|
x7
|
(32, 22)
|
|
x8
|
(34, 20)
|
|
x9
|
(11, 22)
|
|
x10
|
(3, 6)
|
我要将上面10个样本点分成三类, 那么 K=3, 且选定了 3个簇C1、C2和C3,设初始聚簇中心坐标为 O1 = (2, 5) , O2 = (12, 15), O3 = (30,21)
遍历样本点x1 to x10 分别计算到C1, C2和 C3的距离(因为是2维度空间,使用欧氏距离):
C1 = (2, 5) , C2 = (12, 15), C3 = (30,21)
① X1(1,2):
P(x1 -> O1) =
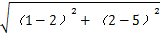 =
=
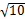
=
P ( x1 -> O2 ) =
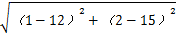 > P(x1 -> O1)
> P(x1 -> O1)
> P(x1 -> O1)
P (x1 -> O3 ) =
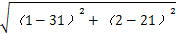 > P ( x1 -> O2 )
> P ( x1 -> O2 )
> P ( x1 -> O2 )
所以将 X1归为 C1类。
② 重复执行上面①部分, 直至 X10 归类结束。
③ 生成了 数据和类别的 映射关系
C1 = {x1, x2, X3, X10}
C2 = {x4, x5, x9}
C3 = {x6, x7, X8}
④ 以均值(means)方式计算并生成C1, C2, C3的新聚蔟中心
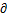 1 ,
1 ,
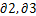
⑤ 计算 X1 to X10到新聚蔟中心
1 ,
的距离
⑥ 重复执行上述5步骤, 直至聚簇中心 坐标不再改变
4. 性能度量:
当我们建立一个聚类模型时,我如何评估我的聚类模型,这是个问题。
分类的目标是寻找某些参数使得代价函数(cost/loss function)函数最小; 而聚类的目标是使聚类的簇内相速度高,且簇外相似度低(可以理解为每个簇簇内更聚合,簇与簇间距最大)
那么评估模型的有两种方法:
① 外部指标: 将聚类结果与某个“参考模型”进行比较
给定参考簇划分C*,对数据集D={x1,x2,..., xm} ,通过聚类得到的簇划分为C ={C1,C2,..., Cn} ,λ 与 λ∗分别表示C和C*对应的簇标记向量,两两配对考虑,有如下定义

SS , SD,DS,DD其和分类的混淆矩阵相似。 SS表示 C中属于相同簇相同簇,且在C*中属于相同簇的样本对(因为定义的条件是两两匹配的),可以近似理解为 true positive的样本对数。
因为每个样本只能隶属于1个簇心,所以 a+ b+ c+ d= m(m-1)/2
② 内部指标: 直接参考聚类结果,不需要其他模型


6. 距离计算:
2中红字部分对应的就是样本点到K簇心的距离计算其实是点到点的计算方式。距离计算又称做 “距离度量”,主要有三种:闵可夫斯基距离(闵氏距离)、曼哈顿距离和欧氏距离,前者是有两者的推广,从1、2维空间扩展到欧氏空间。
 (来自wiki)
(来自wiki)
5. Sklearn算法实现。
1 from sklearn.cluster import KMeans
2 clf = KMeans(n_clusters=K,n_jobs= -2) # n_clusters = k, k个聚簇中心
3 clf.fit(dataset) # 训练模型
原型: class sklearn.cluster.KMeans(n_clusters=8, init='kmeans++', n_init=10, max_iter=300, tol=0.0001, precompute_distances='auto', verbose=0, random_state=None, copy_x=True, n_jobs=1, algorithm='auto')
算法参数:
n_clusters : int, optional, default: 8, K值,默认为8. init : {‘k-means++’, ‘random’ or an ndarray} 'k-means ++':以智能方式为k均值聚类选择初始聚类中心,以加速收敛。 'random':从初始质心的数据中随机选择k个观测值(行) 如果传递了ndarray,它应该是形状(n_clusters,n_features)并给出初始中心。 n_init:int,默认值:10, 使用不同质心种子运行k-means算法的时间。最终结果将是n_init连续运行的最佳输出。 max_iter : int, default: 300,单次运行最大迭代次数 tol : float, default: 1e-4 ; 收敛程度 precompute_distances : {‘auto’, True, False}, 'auto':如果n_samples * n_clusters> 1200万,不预先计算距离。这相当于使用双精度每个作业大约100MB的开销‘; True:始终预计算距离;False:始终不预计算距离 verbose : int, default 0, 详细模式 random_state : int, RandomState instance or None, optional, default: None 。 int,则random_state是随机数生成器使用的种子;RandomState instance: random_state是随机数生成器;None: RandomState实例为np.random copy_x : boolean, default True。 True: 不修改源数据; False:修改源数据 n_jobs : int , 并行计算的CPU数 algorithm : “auto”, “full” or “elkan”, default=”auto” ; K-means algorithm to use, 完整的EM算法为“full”: “elkan”变体更有效,但目前不支持稀疏数据; auto” chooses “elkan”密集数据, “full”为稀疏数据。 属性: cluster_centers_:array,[n_clusters,n_features]; 簇心 坐标 labels_: 每个样本的标签 inertia_ : float , 样本到最近簇心距离和















 142
142











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









