







在之前对HashMap有一个自己的总结文章,近期重新温习了一遍HashMap,发现又学到了很多新的知识点,并且原来的很多观点都是不太正确的;
加耀:浅谈HashMapzhuanlan.zhihu.com
以下是对hashMap新的总结:
HashMap的数据结构
Map是一种很重要的数据结构,在日常开发中几乎是无处不在用;在数据结构章节我们都知道数组查询效率高,但是增删效率低,而链表增删效率高,而查询效率低;也正是因为这一特性,HashMap采用的是数组加链表的结构;不过,数组结构存储区间连续,占用内存情况较为严重,而链表结构存储区间较为离散,占有内存比较宽松;
在JDK1.8之后,HashMap引入了红黑树的结构,当链表长度超过一定值(默认为8)时,则会将链表结构进行调整转变为红黑树结构;当红黑树中的元素数量小于8个时,则又会将结构体进行转变为链表结构;
此举为避免链表过深,导致查询效率低的情况;
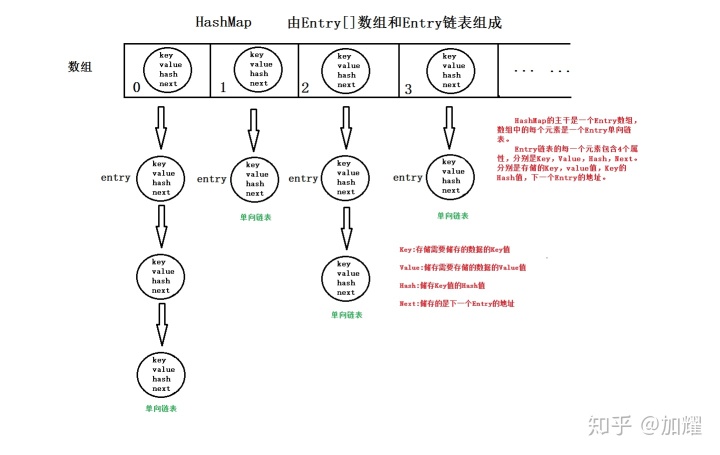
HashMap的默认初始容量为16,即在创建一个HashMap时,HashMap首先创建一个长度为16的空数组,当我们插入数据时,HashMap会根据插入的Key进行hash运算从而计算出当前数据应该存储在哪个数组下标中的链表结构中;
这里的hash函数运算在代码中的表现为:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}从函数中,可以看到,先是对存储的Key进行hashCode运算;首先,对存储的key进行判断,计算key的hashCode散列值,然后对n(数组的长度)进行无符号右移,再进行位运算;
计算下标的公式在JDK1.6之后可简化为位运算:
int index=hash&( Entry[].length - 1);
在JDK1.6之前是使用的取模计算;
int index =hash%Entry[].length;
位运算相比较取模运算,在运行效率上得到了明显的提升;
hashMap的取值过程
在上面我们简单介绍了一下HashMap的结构以及核心算法之一;下面我们再来看一下HashMap的取值过程;
在日常开发中我们经常使用HashMap的PUT和GET方法,当我们GET一个Key的时候,都经历了哪些过程呢;
假设我们往一个HashMap中put了一个Entry -> (“我是key”,“我是value”)的键值队,现在需要根据键查询到值的信息,这个过程如下所示:
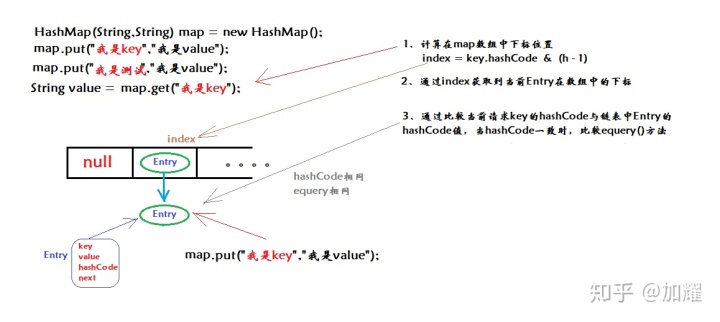
如上图所示,在HashMap中通过key找到value共可以归纳为三个步骤:
1、 计算被查找key的hashCode通过hash函数运算得到所存储的下标
2、 通过下标值定位到数组(桶)的位置
3、 遍历当前数组下维护的链表,通过比较hashCode及equery方法来判断当前Entry是否是我们需要查找的Entry;
4、 找到的话则进行返回,没有的话则遍历当前链表结构(或者是红黑树结构)
hashMap的存值过程
介绍完hashMap的取值过程,我们再来看一下hashMap的存值过程;
在上面我们已经知道了HashMap中计算Key存储位置是通过一个hash函数来计算出来的,然后将这个键值队存储到相对应的下标的链表中;
假设我们需要存储一个键值队为 (“我是key”,”我是value”),那么,通过上述公式计算,可以计算出当前键值队应该是存储在数组的下标为1的位置上;计算过程为 “我是key”.hashCode() & (16 - 1) ,采用HashMap默认的数组长度;
通过定位到存储的下标位置后,将这个键值队(Entry)插入到数组中链表结构中进行存储;而当有新的Entry也保存到这个数组下标时,则新的Entry会存储到链表的表头;如下图
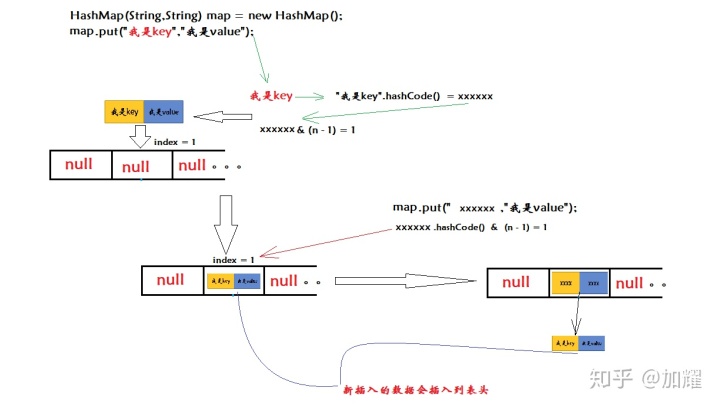
在这个计算下标的公式中,n代表的是当前map的容量值,默认为16,HashMap的默认加载因子为0.75;也就意味着当HashMap中存储的Entry数量达到16*0.75时会进行一次扩容操作;我们看一下源码中对hashMap的初始容量值的说明:
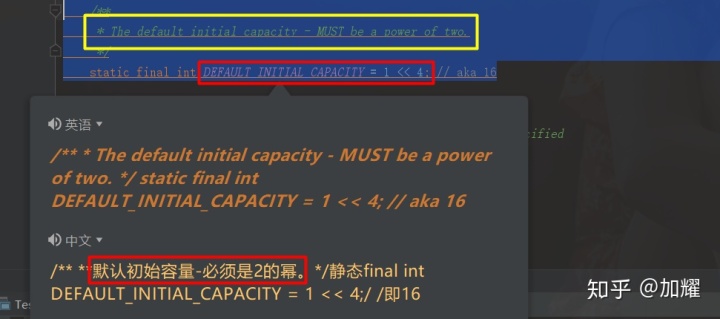
初始容量必须为2的幂次方,默认为16;根据位运算的规则,1 & 1 = 1 否则都等于0;而刚好 2^n – 1 的二进制值所有位数刚好都等于1;通过位运算后,从而保证插入数据的离散型,避免数据过于集中;我们可以通过通过编写一个小程序来看一下hash冲突率:
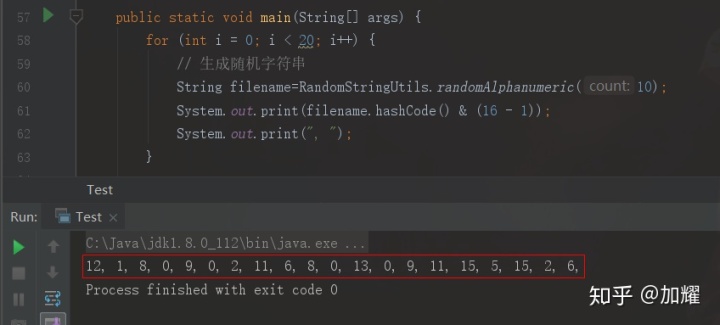
从上面这段程序可以看的出来,对数组而言,当前算法得到的hash离散型较高,hash冲突概率相对较低;
hashMap扩容过程
前面提到过,HashMap的默认初始容量为16,加载因子0.75;当我们通过HashMap的有参构造自定义一个初始容量时,给定的值必须是2的幂次方值;
怎么判断当前HashMap现在的容量值是多少呢?通过HashMap的API好像是查询不到的,这时候我们可以通过反射来获取;如下:
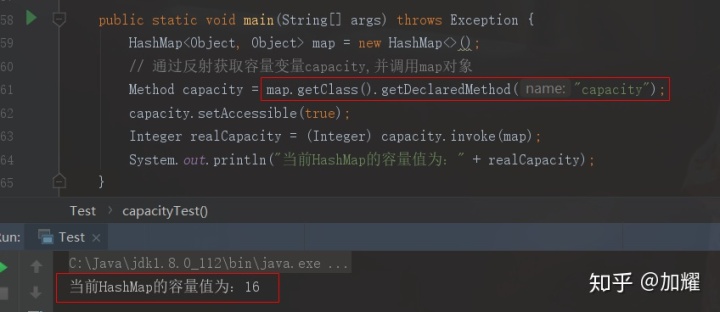
如上所示:HashMap的默认容量值为16;
根据加载因子规则,当 HashMap.Size > Capacity * LoadFactor 时,hashMap会进行一次扩容操作;一次扩容流程可划分为两个步骤:
1、resize : 创建一个新的Entry空数组,长度是原数组的2倍 2、rehash:遍历原Entry数组,把所有的Entry重新Hash到新数组。消耗性能
HashMap的扩容机制
1、 resize:当HashMap.Size > Capacity * LoadFactor时,HashMap会在原有的数组后再创建一个新的Entry空数组,调整后现有数组的长度为原来的2倍;
2、 rehash:当调整完数组长度后,hashMap会遍历整个当前map,将所有的Entry进行重新调整,根据Entry的key重新计算在新数组中存储的位置;这个过程会相对消耗性能;
我们可以编写一个小程序来看一下hashMap的扩容情况:
public static void main(String[] args) throws Exception {
// 指定当前HashMap的初始容量为4
HashMap<Object, Object> map = new HashMap<>(4);
for (int i = 0; i < 25 ; i++) {
// 生成随机字符串
String filename=RandomStringUtils.randomAlphanumeric(10);
System.out.print("当前map的存储容量值为:" + capacity(map) + ", size为:" + map.size());
map.put(filename,null);
System.out.print(", 添加Entry后size为:" + map.size() + ", 此时map的存储容量值为:" + capacity(map));
System.out.println();
}
}
/**
* 通过反射获取容量变量capacity,并调用map对象
*/
public static int capacity(HashMap map) throws Exception{
Method capacity = map.getClass().getDeclaredMethod("capacity");
capacity.setAccessible(true);
Integer realCapacity = (Integer) capacity.invoke(map);
return realCapacity;
}运行结果如下所示:
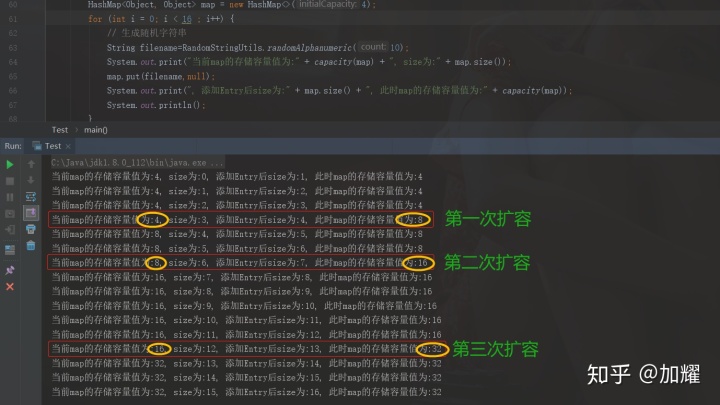
在程序中的运行流程,在put数据之前和之后都有做输出;可以看得出来,只有当HashMap.Size > Capacity * LoadFacto的时候,比如在上面第一次扩容之前,此时map中的size为3,容量为4,此时已经达到了阈值,但是很明显还没有被扩容,而在下一次put数据时才进行了扩容操作;从第二次扩容和第三次扩容可以看到结果都是一样的;
由于HashMap的扩容需要遍历整个map重新调整每个Entry的位置,比较消耗性能,所以在开发中使用HashMap时,如果已知需要存储的总的Entry数量,我们可以在实例化HashMap时,给定一个合理的初始容量,从而减少map的resize和rehash操作,从而提高程序的运行效率和map的安全性;
如下面这一段程序:
public static void main(String[] args) throws Exception {
HashMap<Object, Object> map = new HashMap<>(1024);
System.out.println("当前map的存储容量为:" + capacity(map) + ", map中存储的Entry数量为" + map.size());
for (int i = 0; i < 800 ; i++) {
if (i > 765 && i < 770){
System.out.print("当前map的存储容量值为:" + capacity(map) + ", size为:" + map.size());
}
map.put(RandomStringUtils.randomAlphanumeric(10),null);
if (i > 765 && i < 770){
System.out.print(", 添加Entry后size为:" + map.size() + ", 此时map的存储容量值为:" + capacity(map));
System.out.println();
}
}
}
/**
* 通过反射获取容量变量capacity,并调用map对象
*/
public static int capacity(HashMap map) throws Exception{
Method capacity = map.getClass().getDeclaredMethod("capacity");
capacity.setAccessible(true);
Integer realCapacity = (Integer) capacity.invoke(map);
return realCapacity;
} 我们看一下输出结果:
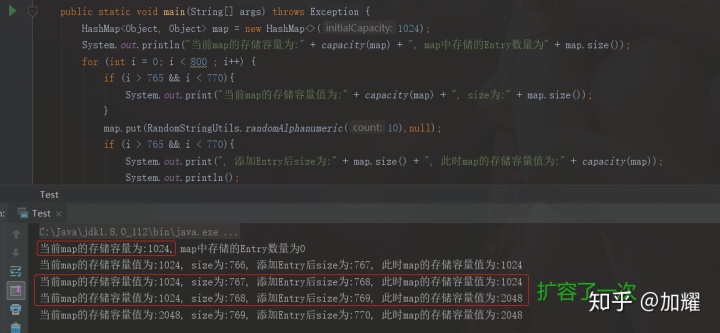
通过运行结果,我们可以看到,在程序中,往一个初始值为1024的hashMap中批量插入800个不同的Entry只进行了一次扩容操作;相反,如果我们使用hashMap默认的初始容量,此时则需要进行7次扩容操作,遍历7次map中的Entry;可想而知是严重影响性能的;
在实际开发中,我们以程序实际情况来定,通常情况下使用默认的16即可满足大多数情况;当数据量多初始容量小,扩容影响性能;当数据量少初始容量大,容量占用内存;
众所周知,HashMap是线程不安全的集合;因为HashMap在多线程的情况下,可能会造成一种环形链表;如:当threshold(临界值)满了的情况时,map需要进行扩容操作,两个线程都往map中插入数据,两个线程都会对map进行扩容操作,在这里面,会有很多很多不安全的情况出现;
2019年6月15日 18:03:18















 241
241











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









