







 本文介绍了Tesseract OCR引擎的概述、下载安装过程,特别是如何在命令行中使用。针对Windows 8.1系统,详细阐述了安装路径、命令行参数的使用,如-l参数指定语言库,-psm参数设定页面分割模式。还提到了提高识别率的技巧,如图片预处理,并提及了训练Tesseract以提高识别准确性。
本文介绍了Tesseract OCR引擎的概述、下载安装过程,特别是如何在命令行中使用。针对Windows 8.1系统,详细阐述了安装路径、命令行参数的使用,如-l参数指定语言库,-psm参数设定页面分割模式。还提到了提高识别率的技巧,如图片预处理,并提及了训练Tesseract以提高识别准确性。
原文地址:http://blog.csdn.net/whatday/article/details/38493551
1.Tesseract-OCR引擎简介
OCR(Optical Character Recognition):光学字符识别,是指对图片文件中的文字进行分析识别,获取的过程。
Tesseract的OCR引擎最先由HP实验室于1985年开始研发,至1995年时已经成为OCR业内最准确的三款识别引擎之一。然而,HP不久便决定放弃OCR业务,Tesseract也从此尘封。
数年以后,HP意识到,与其将Tesseract束之高阁,不如贡献给开源软件业,让其重焕新生--2005年,Tesseract由美国内华达州信息技术研究所获得,并求诸于Google对Tesseract进行改进、消除Bug、优化工作。
2.Tesseract-OCR的下载安装
google下载地址:http://code.google.com/p/tesseract-ocr
需要下载安装程序(tesseract-ocr-setup-3.02.02.exe)和语言库,默认有英文的语言库只能识别英文,所以还需要下载中文语言库,
由于google经常打不开,所以通过代理下载后,上传到了CSDN,
安装程序下载地址:http://download.csdn.net/detail/whatday/7740469
简体中文语言库下载地址:http://download.csdn.net/detail/whatday/7740531
繁体中文语言库下载地址:http://download.csdn.net/detail/whatday/7740429
安装tesseract-ocr-setup-3.02.02.exe 默认安装就可以了,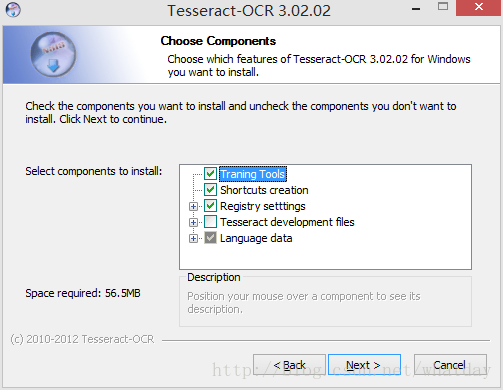
因为如果选择了其他项,安装程序会自动从网上下载,语言库和其他文件,有很大一部分是从google下载,由于不能打开所以会出错,先默认安装上,需要什么文件再下载就行。
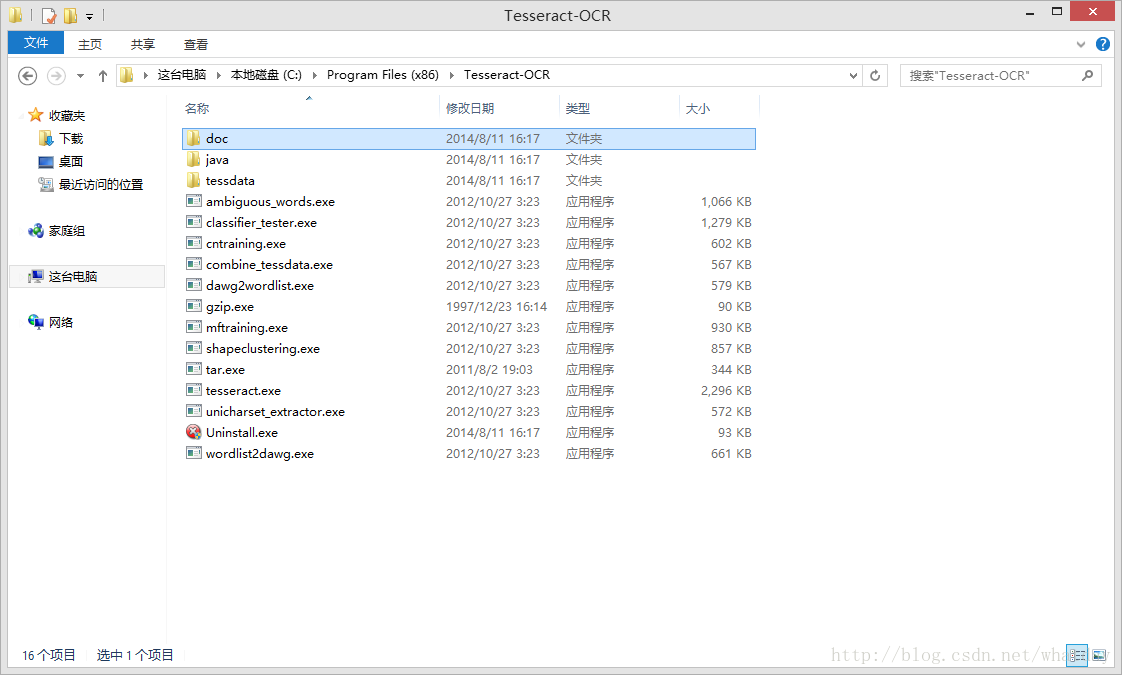
我系统是windows8.1 默认安装好后目录如下:
其中tesseract.exe是主程序, tessdata目录是存放语言文件 和 配置文件的,下载或自己生成的语言文件放到此目录里就可以了。
3.Tesseract-OCR的命令行使用
打开DOS界面,输入tesseract:
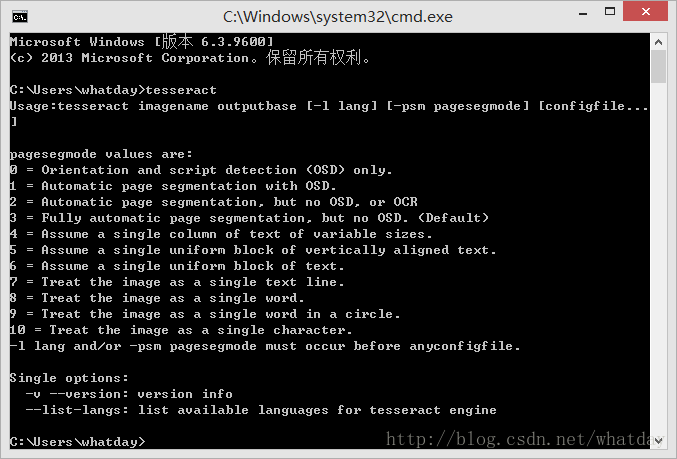
如果出现如上输出,表示安装正常。
我准备了一张验证码1.png放在D盘根目录下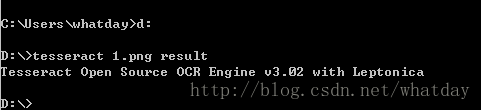
其中 1.png是验证码图片 result是结果文件的名称 默认是.TXT文件 执行成功后会在验证码图片所在位置生成result.txt 打开结果为:
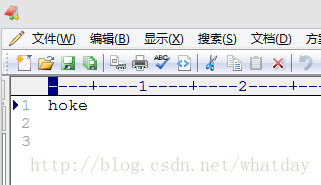
命令详解:
Usage:tesseract imagename outputbase [-l lang] [-psm pagesegmode] [configfile...]
pagesegmode values are:
0 = Orientation and script detection (OSD) only.
1 = Automatic page segmentation with OSD.
2 = Automatic page segmentation, but no OSD, or OCR
3 = Fully automatic page segmentation, but no OSD. (Default)
4 = Assume a single column of text of variable sizes.
5 = Assume a single uniform block of vertically aligned text.
6 = Assume a single uniform block of text.
7 = Treat the image as a single text line.
8 = Treat the image as a single word.
9 = Treat the image as a single word in a circle.
10 = Treat the image as a single character.
-l lang and/or -psm pagesegmode must occur before anyconfigfile.
tesseract imagename outputbase [-l lang] [-psm pagesegmode] [configfile...]
tesseract 图片名 输出文件名 -l 字库文件 -psm pagesegmode 配置文件
例如:
tesseract code.jpg result -l chi_sim -psm 7 nobatch
-l chi_sim 表示用简体中文字库(需要下载中文字库文件,解压后,存放到tessdata目录下去,字库文件扩展名为 .raineddata 简体中文字库文件名为: chi_sim.traineddata)
-psm 7 表示告诉tesseract code.jpg图片是一行文本 这个参数可以减少识别错误率. 默认为 3
configfile 参数值为tessdata\configs 和 tessdata\tessconfigs 目录下的文件名
4.Tesseract-OCR的QA合集
A.ImageMagick是什么?
ImageMagick是一个用于查看、编辑位图文件以及进行图像格式转换的开放源代码软件套装
我在这里之所以提到ImageMagic
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 832
832

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









