






vue+django2.0.2-rest-framework 生鲜项目
Django下的 REST framework
Django REST framework 框架是一个用于构建Web API 的强大而又灵活的工具。
通常简称为DRF框架 或 REST framework。
DRF框架是建立在Django框架基础之上,由Tom Christie大牛二次开发的开源项目。
特点
- 提供了定义序列化器Serializer的方法,可以快速根据 Django ORM 或者其它库自动序列化/反序列化;
- 提供了丰富的类视图、Mixin扩展类,简化视图的编写;
- 丰富的定制层级:函数视图、类视图、视图集合到自动生成 API,满足各种需要;
- 多种身份认证和权限认证方式的支持;
- 内置了限流系统;
- 直观的 API web 界面;
- 可扩展性,插件丰富
目前支持的python、django版本:
- Python (2.7, 3.2, 3.3, 3.4, 3.5, 3.6)
- Django (1.10, 1.11, 2.0)
1)安装drf依赖包
coreapi (1.32.0+) - Schema generation support. Markdown (2.1.0+) - Markdown support for the browsable API. # 已安装 django-filter (1.0.1+) - Filtering support. # 已安装 django-crispy-forms - Improved HTML display for filtering. # 已安装 django-guardian (1.1.1+) - Object level permissions support.
2)Mxshop下setting中注册:
rest_framework
crispy_forms
INSTALLED_APPS = [ 'django.contrib.auth', 'django.contrib.admin', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'apps.users.apps.UsersConfig', 'apps.goods.apps.GoodsConfig', 'apps.trade.apps.TradeConfig', 'apps.user_operation.apps.UserOperationConfig', 'xadmin', 'crispy_forms', 'DjangoUeditor', 'rest_framework', ]
3)配置drf文档的url
首先,导入drf中的include_docs_urls
from rest_framework.documentation import include_docs_urls
# 自动化文档,1.11版本中注意此处前往不要加$符号 path('docs/', include_docs_urls(title='生鲜电商')), # 调试登录 path('api-auth/', include('rest_framework.urls')),
1、rest_framework下的serializers,类似django下的form组件:serializers.Serializer (django下 form.Form)
REST framework首测:rest framework中的serializers组件
1)goods文件夹下面新建serializers.py,类似django中的form组件
用drf的序列化实现商品列表页展示,代码如下:
# goods/serializers.py from rest_framework import serializers class GoodsSerializer(serializers.Serializer): name = serializers.CharField(required=True,max_length=100) click_num = serializers.IntegerField(default=0) goods_front_image = serializers.ImageField()
2)goods/views.py:get方法
# googd/views.py from rest_framework.views import APIView from goods.serializers import GoodsSerializer from .models import Goods from rest_framework.response import Response class GoodsListView(APIView): ''' 商品列表 '''
# get方法,获取数据,客户端输入网址时触发 def get(self,request,format=None): goods = Goods.objects.all() goods_serialzer = GoodsSerializer(goods,many=True) return Response(goods_serialzer.data)
3)Mxshop/urls.py配置:
from goods.views import GoodsListView urlpatterns = [ # 商品列表页 path('goods/', GoodsListView.as_view(),name="goods_list"), ]
浏览器输入网址:http://127.0.0.1:8000/goods/
页面效果: 关于路径相关,会自动补全路径

注:右上角log in ,可用admin超级用户登录
2)serializers的post方法,goods/views.py的GoodsListView添加post方法,客户端提交数据时会触发:
# googd/views.py from rest_framework.views import APIView from goods.serializers import GoodsSerializer from .models import Goods from rest_framework.response import Response from rest_framework import status class GoodsListView(APIView): ''' 商品列表 ''' # get方法,获取数据,客户端输入网址回车时触发 def get(self,request,format=None): goods = Goods.objects.all() goods_serialzer = GoodsSerializer(goods,many=True) return Response(goods_serialzer.data) # post方法,客户端输入数据提交时触发 def post(self,request,format=None): serializer = GoodsSerializer(data = request.data) # 将用户输入数据传入到GoodsSerializers中,类似django中form的post方法 if serializer.is_valid(): # 判断数据是否一致,没错误 serializer.save() # 保存 return Response(serializer.data,status=status.HTTP_201_CREATED) return Response(serializer.errors,status=status.HTTP_400_BAD_REQUEST)
goods/serializers.py中添加create方法,goods/views.py中的GoodsListView触发post函数时,调用GoodsSerializer中的create方法
from rest_framework import serializers from goods.models import Goods class GoodsSerializer(serializers.Serializer): name = serializers.CharField(required=True,max_length=100) click_num = serializers.IntegerField(default=0) goods_front_image = serializers.ImageField() def create(self,validated_data): # 保存数据到数据库 return Goods.object.create(**validated_data)
2、rest_framework下的serializers,类似django下的form组件:serializers.ModelSerializer (django下 form.ModelForm)
ModelSerializer中,不需要自己添加字段(Serializers中需要手动添加model中的字段),因为ModelSerializer会自动到相应的model模块中找对应所需字段
另外,关于外键,不做任何处理,外键字段会自动显示关联表的id,如需显示关联表所有,则需做处理:
GoodsSerializer嵌套CategorySerializer
# goods/serializers.py from rest_framework import serializers from .models import Goods,GoodsCategory #Serializer实现商品列表页 # class GoodsSerializer(serializers.Serializer): # name = serializers.CharField(required=True,max_length=100) # click_num = serializers.IntegerField(default=0) # goods_front_image = serializers.ImageField() # Category的CategorySerializer class CategorySerializer(serializers.ModelSerializer): class Meta: model = GoodsCategory fields = "__all__" #ModelSerializer实现商品列表页 #Goods类的GoodsSerializer class GoodsSerializer(serializers.ModelSerializer): #手动添加字段,如model中有则会覆盖字段。 #此为外键字段,实例化,会获取关联表的所有数据 category = CategorySerializer() class Meta: model = Goods fields = '__all__'
页面效果:

GenericView实现商品列表页
1、用generics:generics.py
GenericAPIView继承view.APIView,封装了很多方法,比APIView功能更强大


class GenericAPIView(views.APIView): """ Base class for all other generic views. """ # You'll need to either set these attributes, # or override `get_queryset()`/`get_serializer_class()`. # If you are overriding a view method, it is important that you call # `get_queryset()` instead of accessing the `queryset` property directly, # as `queryset` will get evaluated only once, and those results are cached # for all subsequent requests. queryset = None serializer_class = None # If you want to use object lookups other than pk, set 'lookup_field'. # For more complex lookup requirements override `get_object()`. lookup_field = 'pk' lookup_url_kwarg = None # The filter backend classes to use for queryset filtering filter_backends = api_settings.DEFAULT_FILTER_BACKENDS # The style to use for queryset pagination. pagination_class = api_settings.DEFAULT_PAGINATION_CLASS def get_queryset(self): """ Get the list of items for this view. This must be an iterable, and may be a queryset. Defaults to using `self.queryset`. This method should always be used rather than accessing `self.queryset` directly, as `self.queryset` gets evaluated only once, and those results are cached for all subsequent requests. You may want to override this if you need to provide different querysets depending on the incoming request. (Eg. return a list of items that is specific to the user) """ assert self.queryset is not None, ( "'%s' should either include a `queryset` attribute, " "or override the `get_queryset()` method." % self.__class__.__name__ ) queryset = self.queryset if isinstance(queryset, QuerySet): # Ensure queryset is re-evaluated on each request. queryset = queryset.all() return queryset def get_object(self): """ Returns the object the view is displaying. You may want to override this if you need to provide non-standard queryset lookups. Eg if objects are referenced using multiple keyword arguments in the url conf. """ queryset = self.filter_queryset(self.get_queryset()) # Perform the lookup filtering. lookup_url_kwarg = self.lookup_url_kwarg or self.lookup_field assert lookup_url_kwarg in self.kwargs, ( 'Expected view %s to be called with a URL keyword argument ' 'named "%s". Fix your URL conf, or set the `.lookup_field` ' 'attribute on the view correctly.' % (self.__class__.__name__, lookup_url_kwarg) ) filter_kwargs = {self.lookup_field: self.kwargs[lookup_url_kwarg]} obj = get_object_or_404(queryset, **filter_kwargs) # May raise a permission denied self.check_object_permissions(self.request, obj) return obj def get_serializer(self, *args, **kwargs): """ Return the serializer instance that should be used for validating and deserializing input, and for serializing output. """ serializer_class = self.get_serializer_class() kwargs['context'] = self.get_serializer_context() return serializer_class(*args, **kwargs) def get_serializer_class(self): """ Return the class to use for the serializer. Defaults to using `self.serializer_class`. You may want to override this if you need to provide different serializations depending on the incoming request. (Eg. admins get full serialization, others get basic serialization) """ assert self.serializer_class is not None, ( "'%s' should either include a `serializer_class` attribute, " "or override the `get_serializer_class()` method." % self.__class__.__name__ ) return self.serializer_class def get_serializer_context(self): """ Extra context provided to the serializer class. """ return { 'request': self.request, 'format': self.format_kwarg, 'view': self } def filter_queryset(self, queryset): """ Given a queryset, filter it with whichever filter backend is in use. You are unlikely to want to override this method, although you may need to call it either from a list view, or from a custom `get_object` method if you want to apply the configured filtering backend to the default queryset. """ for backend in list(self.filter_backends): queryset = backend().filter_queryset(self.request, queryset, self) return queryset @property def paginator(self): """ The paginator instance associated with the view, or `None`. """ if not hasattr(self, '_paginator'): if self.pagination_class is None: self._paginator = None else: self._paginator = self.pagination_class() return self._paginator def paginate_queryset(self, queryset): """ Return a single page of results, or `None` if pagination is disabled. """ if self.paginator is None: return None return self.paginator.paginate_queryset(queryset, self.request, view=self) def get_paginated_response(self, data): """ Return a paginated style `Response` object for the given output data. """ assert self.paginator is not None return self.paginator.get_paginated_response(data) 复制代码 用的时候需要定义queryset和serializer_class GenericAPIView里面默认为空 queryset = None serializer_class = None ListModelMixin里面list方法帮我们做好了分页和序列化的工作,只要调用就好了 ListModelMixin源码 实现如下: 复制代码 from goods.serializers import GoodsSerializer from .models import Goods from rest_framework.response import Response from rest_framework import mixins from rest_framework import generics class GoodsListView(mixins.ListModelMixin,generics.GenericAPIView): '商品列表页' queryset = Goods.objects.all() serializer_class = GoodsSerializer def get(self,request,*args,**kwargs): return self.list(request,*args,**kwargs)
使用generics.ListAPIView:ListAPIView继承于GenericAPIView、mixins.ListModelMixin,
mixins.ListModelMixin:封装了get方法
generics.GenericAPIView:主要负责过滤、分页等
创建GoodsListView,继承于generics.ListAPIView
使用generics.ListAPIView这种方式,需定义queryset和serializer_class,在GenericAPIView内部代码都默认为空 ,不需要再重写get方法:
- queryset = None
- serializer_class = None
如下代码,同样能实现获取商品列表页数据的功能
需要注意的是:如果不是直接继承于generics.ListAPIView类,而是分为继承ListModelMixin、GenericAPIView,则需要在GoodsListView中重写get方法,如不重写会报错(不让以get方法去访问url)。原因是:ListAPIView中已经写好get方法,继承后可以直接用,而ListModelMixin中并没有实现get方法,因此需要我们重载get方法
from rest_framework import generics class GoodsListView(generics.ListAPIView): queryset = Goods.objects.all()[:10] serializer_class = GoodsSerializer
2、使用generics.ListAPIView,可以帮助我们很容易使用分页,只需要在setting中配置下分页相关的:
# Mxshop/setting.py REST_FRAMEWORK = { 'DEFAULT_PAGINATION_CLASS': 'rest_framework.pagination.LimitOffsetPagination', # 源码已不提供默认的分页类 'PAGE_SIZE':10, }
goods/views.py重新定义GoodsListView(注释掉之前的类):
from rest_framework import generics from .model import Goods class GoodsListView(generics.ListAPIView): queryset = Goods.objects.all() serializer_class = GoodsSerializer
这样就在上面的基础上实现了分页:
记住,此时页面跟之前的页面有所不一样,多了:
"count": 104, "next": "http://127.0.0.1:8000/goods/?limit=10&offset=10", "previous": null,
另外,图片路径等也完全补全了(域名也自动追加上去了)
3、还可以自定义分页相关:
goods/views.py:
此时可以不用setting中REST_FRAMEWORK相关的配置,可以注释掉
from rest_framework import generics from .model import Goods
from rest_framework.pagination import PageNumberPagination # 分页自定义化设置,此时可以注销setting.py中的REST_FRAMEWORK class GoodsPagination(PageNumberPagination): page_size = 10 page_size_query_param = 'page_size' #每页10个数据 page_query_param = 'p' #url过滤信息,不再显示‘page=**’,而是显示‘p=**’ max_page_size =最大100个数据 class GoodsListView(generics.ListAPIView): queryset = Goods.objects.all() serializer_class = GoodsSerializer pagination_class = GoodsPagination #将自定义分页添加进来
Viewsets和router完成商品列表页
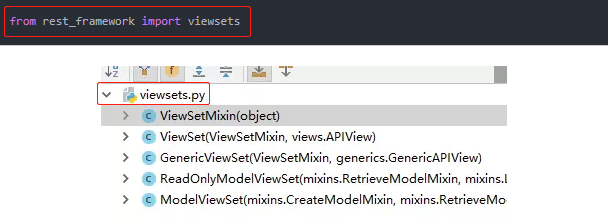
目前主要接触GenericViewSet:
# 继承于 ViewSetMixin,跟 generics.GenericAPIView class GenericViewSet(ViewSetMixin, generics.GenericAPIView):
ViewSetMixin中重写了as_view方法可以让我们的注册url变得更加简单:
动态设置as_view、Serializer方法

ViewSets和Routers配套使用
首先不使用Routers的情况:
goods/views.py
from rest_framework import generics from .model import Goods from rest_framework.pagination import PageNumberPagination # 分页自定义化设置,此时可以注销setting.py中的REST_FRAMEWORK class GoodsPagination(PageNumberPagination): page_size = 10 page_size_query_param = 'page_size' #每页10个数据 page_query_param = 'p' #url过滤信息,不再显示‘page=**’,而是显示‘p=**’ max_page_size = 100 #最大100个数据 from rest_framework import viewsets from rest_framework import mixins class GoodsListViewSet(mixins.ListModelMixin, viewsets.GenericViewSet): #mixins.ListModelMixin:提供get等方法 queryset = Goods.objects.all() serializer_class = GoodsSerializer pagination_class = GoodsPagination #将自定义分页添加进来
Mxshop/url.py:配置url
goods_list = GoodsListViewSet.as_view({ 'get': 'list', 'post':'create', })
即将get请求绑定到list之上,post绑定到create上,类似:
def get(self, request, *args, **kwargs): return self.list(request, *args, **kwargs)
然后在Mxshop/url.py下的urlpatterns中配置上述url:
此时,url中不需要再加as_view()了
旧:
urlpatterns = [ path('goods/', GoodsListView.as_view(),name="goods-list"), ]
新:
urlpatterns = [ # 商品列表页 path('goods/', goods_list,name="goods-list"), ]
但是我们可以更厉害一点,直接不用进行这个get 与list的绑定,通过router的结合使用,可以更简单
1)在url.py中导入DefaultRouter,并注册goods:
from rest_framework.routers import DefaultRouter # 导入 router = DefaultRouter() #实例化router # 注册goods router.register(r'goods', GoodsListViewSet,base_name="goods")
2)url.py中配置router的url路径:
urlpatterns = [ # router的path路径 re_path('^', include(router.urls)),
#此时,关于商品列表页的url就可以注释掉了:
# path('goods/', goods_list,name="goods-list"),
]
'''
此时,因goods已经注册到router中,当页面访问goods页面时,在url中没有找到对应的路径,会到router中查找是否有与goods相关的url信息,
找到则会触发相应的get或post等方法(router已自动配置好get/list,post/create等的绑定)
'''
注:router自动帮我们配置了get 和list,create 和 post等等的绑定
drf的APIView、GenericView、viewsets和router的原理
genericViewSet 是最高的一层
往下
GenericViewSet(viewsets) ----drf
GenericAPIView ---drf
APIView ---drf
View ----django
这些view功能的不同,主要的是有mixin的存在
mixins总共有五种:
CreateModelMixin
ListModelMixin
UpdateModelMixin
RetrieveModelMixin
DestoryModelMixin
课程中,我们着重使用Viewset.py中的GenericViewSet ,GenericViewSet 继承于 generic.GenericAPIView 、ViewSetMixin
ViewSet类与View类其实几乎是相同的,但提供的是read或update这些操作,而不是get或put 等HTTP动作。同时,ViewSet为我们提供了默认的URL结构, 使得我们能更专注于API本身。
Router提供了一种简单,快速,集成的方式来定义一系列的urls

drf的request和response介绍
REST framework 的 Request 类扩展与标准的 HttpRequest,并做了相应的增强,比如更加灵活的请求解析(request parsing)和认证(request authentication)。
REST framwork 的 Request 对象提供了灵活的请求解析,允许你使用 JSON data 或 其他 media types 像通常处理表单数据一样处理请求。
request.data 返回请求主题的解析内容。这跟标准的 request.POST 和 request.FILES 类似,并且还具有以下特点:
- 包括所有解析的内容,文件(file) 和 非文件(non-file inputs)。
- 支持解析
POST以外的 HTTP method , 比如PUT,PATCH。 - 更加灵活,不仅仅支持表单数据,传入同样的 JSON 数据一样可以正确解析,并且不用做额外的处理(意思是前端不管提交的是表单数据,还是 JSON 数据,
.data都能够正确解析)。
.data 具体操作,以后再说~
request.query_params 等同于 request.GET,不过其名字更加容易理解。
为了代码更加清晰可读,推荐使用 request.query_params ,而不是 Django 中的 request.GET,这样那够让你的代码更加明显的体现出 ----- 任何 HTTP method 类型都可能包含查询参数(query parameters),而不仅仅只是 'GET' 请求。
.parser
APIView 类或者 @api_view 装饰器将根据视图上设置的 parser_classes 或 settings 文件中的 DEFAULT_PARSER_CLASSES 设置来确保此属性(.parsers)自动设置为 Parser 实例列表。
通常不需要关注该属性......
如果你非要看看它里面是什么,可以打印出来看看,大概长这样:
[<rest_framework.parsers.JSONParser object at 0x7fa850202d68>, <rest_framework.parsers.FormParser object at 0x7fa850202be0>, <rest_framework.parsers.MultiPartParser object at 0x7fa850202860>]
包含三个解析器 JSONParser,FormParser,MultiPartParser。
注意: 如果客户端发送格式错误的内容,则访问
request.data可能会引发ParseError。默认情况下, REST framework 的APIView类或者@api_view装饰器将捕获错误并返回400 Bad Request响应。 如果客户端发送的请求内容无法解析(不同于格式错误),则会引发UnsupportedMediaType异常,默认情况下会被捕获并返回415 Unsupported Media Type响应。
Responses
与基本的 HttpResponse 对象不同,TemplateResponse 对象保留了视图提供的用于计算响应的上下文的详细信息。直到需要时才会计算最终的响应输出,也就是在后面的响应过程中进行计算。 — Django 文档
REST framework 通过提供一个 Response 类来支持 HTTP 内容协商,该类允许你根据客户端请求返回不同的表现形式(如: JSON ,HTML 等)。
Response 类的子类是 Django 的 SimpleTemplateResponse。Response 对象使用数据进行初始化,数据应由 Python 对象(native Python primitives)组成。然后 REST framework 使用标准的 HTTP 内容协商来确定它应该如何渲染最终响应的内容。
当然,您也可以不使用 Response 类,直接返回常规 HttpResponse 或 StreamingHttpResponse 对象。 使用 Response 类只是提供了一个更好的交互方式,它可以返回多种格式。
除非由于某种原因需要大幅度定制 REST framework ,否则应该始终对返回 Response 对象的视图使用 APIView 类或 @api_view 装饰器。这样做可以确保视图执行内容协商,并在视图返回之前为响应选择适当的渲染器。
与普通 HttpResponse 对象不同,您不会使用渲染的内容实例化 Response 对象。相反,您传递的是未渲染的数据,可能包含任何 Python 对象。
由于 Response 类使用的渲染器不能处理复杂的数据类型(比如 Django 的模型实例),所以需要在创建 Response 对象之前将数据序列化为基本的数据类型。
你可以使用 REST framework 的 Serializer 类来执行序列化的操作,也可以用自己的方式来序列化。
构造方法: Response(data, status=None, template_name=None, headers=None, content_type=None)
参数:
data: 响应的序列化数据。status: 响应的状态代码。默认为200。template_name: 选择HTMLRenderer时使用的模板名称。headers: 设置 HTTP header,字典类型。content_type: 响应的内容类型,通常渲染器会根据内容协商的结果自动设置,但有些时候需要手动指定。
还没有渲染,但已经序列化的响应数据。
状态码
将会返回的响应内容,必须先调用 .render() 方法,才能访问 .content 。
只有在 response 的渲染器是 HTMLRenderer 或其他自定义模板渲染器时才需要提供。
用于将会返回的响应内容的渲染器实例。
从视图返回响应之前由 APIView 或 @api_view 自动设置。
内容协商阶段选择的媒体类型。
从视图返回响应之前由 APIView 或 @api_view 自动设置。
.renderer_context
将传递给渲染器的 .render() 方法的附加的上下文信息字典。
从视图返回响应之前由 APIView 或 @api_view 自动设置。
Response 类扩展于 SimpleTemplateResponse,并且响应中也提供了所有常用的属性和方法。例如,您可以用标准方式在响应中设置 header:
response = Response() response['Cache-Control'] = 'no-cache'
.render()
与其他任何 TemplateResponse 一样,调用此方法将响应的序列化数据呈现为最终响应内容。响应内容将设置为在 accepted_renderer 实例上调用 .render(data,accepted_media_type,renderer_context) 方法的结果。
通常不需要自己调用 .render() ,因为它是由 Django 处理的。
drf的过滤操作
drf的filter用法 http://www.django-rest-framework.org/api-guide/filtering/
1)drf的 Filtering 依赖django_filters,需先安装django_filters:
pip install django_filters #之前已安装好
2)在setting中app注册 django_filters:
INSTALLED_APPS = [ 'django_filters', ]
3)goods/views.py 中添加过滤操作:
from django_filters.rest_framework import DjangoFilterBackend class GoodsListViewSet(mixins.ListModelMixin,viewsets.GenericViewSet): '''商品列表页''' queryset = Goods.objects.all() # 分页 pagination_class = GoodsPagination serializer_class = GoodsSerializer filter_backends = (DjangoFilterBackend,) # 设置filter过滤字段 filter_fields = ('name','shop_price')
此时,浏览器访问goods页面,会多出一个 过滤器 ,可用来过滤,但此时的过滤是绝对匹配,也就是说,输入匹配词必须是完整的,而且区间的过滤无法实现,比如过滤价格在100到200之间的
页面效果:

* 要想能实现区间过滤,需要自定义filter过滤类:
在goods app中新建 filter.py:
# goods/filters.py import django_filters from .models import Goods class GoodsFilter(django_filters.rest_framework.FilterSet): ''' 自定义过滤器,实现区间过滤 商品过滤的类 ''' #filters.NumberFilter有两个参数,field_name是要过滤的字段,lookup是执行的行为,‘小与等于本店价格’ price_min = django_filters.NumberFilter(field_name="shop_price", lookup_expr='gte') #注:第一个参数原先叫 name , 现已改成 field_name price_max = django_filters.NumberFilter(field_name="shop_price", lookup_expr='lte') class Meta: model = Goods fields = ['price_min', 'price_max']
goods/views.py 做下修改:
from django_filters.rest_framework import DjangoFilterBackend from goods import filter class GoodsListViewSet(mixins.ListModelMixin,viewsets.GenericViewSet): '''商品列表页''' queryset = Goods.objects.all() # 分页 pagination_class = GoodsPagination serializer_class = GoodsSerializer filter_backends = (DjangoFilterBackend,) # filter_fields = ('name','shop_price') # 设置filter的类为我们自定义的类 filter_class = GoodsFilter
此时,页面过滤器效果:

* 接下来实现name的模糊搜索:
在goods/filter.py中添加模糊搜索的字段:
# lookup_expr = 'contains' :类似数据库模糊查询的like参数,contains加'i'表示不区分大小写 name = django_filters.CharFilter(field_name = 'name' , lookup_expr = 'icontains') #lookup_expr = 'icontains',此句不写,表示绝对匹配
goods/filter.py:
class GoodsFilter(django_filters.rest_framework.FilterSet): ''' 自定义过滤器,实现区间过滤 商品过滤的类 ''' #filters.NumberFilter有两个参数,name是要过滤的字段,lookup是执行的行为,‘小与等于本店价格’ price_min = django_filters.NumberFilter(field_name="shop_price", lookup_expr='gte') price_max = django_filters.NumberFilter(field_name="shop_price", lookup_expr='lte') name = django_field.CharFilter(filter_name = 'name' , lookup_expr = 'icontains') class Meta: model = Goods fields = ['price_min', 'price_max','name']
此时,页面过滤器效果:
搜索'水果'时,能查到所有name中包含'水果'字样的数据

drf的搜索和排序
过滤用的是 django_filter,搜索跟搜索用的是rest_framework下的 Filter、OrderingFilter。
我们不一定在这个类里面使用它自带的过滤方法。还可以自定义我们的过滤方法,这个在后面会讲到。
1)Filter 搜索功能
goods/views.py中,
导入:
from rest_framework import filters
GoodsListViewSet类中添加:
filter_backends = (filters.SearchFilter)
search_fields = ('name', 'goods_brief', 'goods_desc') #搜索时,会匹配search_fields中配置的所有字段
goods/views.py代码:
from rest_framework import filters #新增导入 class GoodsListViewSet(mixins.ListModelMixin,viewsets.GenericViewSet): '''商品列表页''' queryset = Goods.objects.all() # 分页 pagination_class = GoodsPagination # 序列化 serializer_class = GoodsSerializer filter_backends = (DjangoFilterBackend,filters.SearchFilter) # 设置filter过滤字段 # filter_fields = ('name','shop_price') # 设置filter的类为我们自定义的类 filter_class = GoodsFilter # 设置我们的search字段 search_fields = ('name', 'goods_brief', 'goods_desc')
此时,页面过滤器效果:

search_fields:具有多种搜索方式
^:Starts-with search.匹配以...开头=:Exact matches.完全匹配@:Full-text search. (Currently only supported Django's MySQL backend.) 全文搜索$:Regex search.表示以正则表达式搜索
search_fields = ('^username', '=email')
2)OrderingFilter :排序
goods/views.py:
class GoodsListViewSet(mixins.ListModelMixin,viewsets.GenericViewSet): '''商品列表页''' queryset = Goods.objects.all() # 分页 pagination_class = GoodsPagination # 序列化 serializer_class = GoodsSerializer # 过滤、搜索、排序 filter_backends = (DjangoFilterBackend,filters.SearchFilter,filters.OrderingFilter) # 设置filter过滤字段 # filter_fields = ('name','shop_price') # 设置filter的类为我们自定义的类 filter_class = GoodsFilter # 设置我们的search字段 search_fields = ('name', 'goods_brief', 'goods_desc') # 设置排序 ordering_fields = ('sold_num', 'add_time')
此时,页面过滤器效果:

总结:
- 在view_base.py文件中,通过django自身的原生view实现了商品列表页。
- 可以用- model_to_dict方法,自己序列化,进阶的话使用 Serializer - JSonresponse 序列化
- 用rest_framework相关的:api view generics - viewsets ,进行序列化及过滤、搜索、排序等操作














 781
781











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









