






1、链表和顺序表
链表是很常见的数据结构,链表总是会和线性顺序表来比较。
1.1、顺序表
- 具有随机存储的特性,给定位置就能通过计算找到数据所在位置,因为在分配存储空间的时候,是连续分配的,所以读取很快。
- 因为事先要开辟一块空间,过大会造成空间浪费,过小会溢出,所以在存储位置长度的数据时,表现不是很好。
在插入和删除元素时,涉及到元素的移动,最坏情况下要移动表里所有元素,效率不高。
1.2、链表
- 通过指向下一结点的指针,来找到下一个元素,每个节点要存储数据信息和指向下一结点的指针,从空间利用率上来说,不如顺序表。
- 不具有随机存储的特点,例如想找到下标为5的元素,顺序表可以直接访问,而链表必须逐个调整,最后才能找到这个元素。
插入、删除效率高,相较于顺序表的移动元素,链表只需调整指针指向的元素。
1.3、比较
- 对于随机读取次数多,且对插入、删除需求小的时候,可以用顺序表来存储,更合理。
- 对于插入、删除需求频繁的时候,可以用链表来存储,更合理。
如果内存中碎片多,此时可能无法开辟一块连续的大空间,从而无法创建顺序表,此时可以使用链表。
2、单链表
2.1、两种类型
有许多种链表,单链表就是很常见的一种链表类型。即只能从前向后遍历,无法从后向前遍历。其中单链表又有带头和不带头之分,听起来怎么有点吓人……- 不带头链表中第一个结点就是我们所存储的元素的结点。
带头链表中第一个结点存储的元素为空,这个就是所谓的头,第二个结点才是我们存储的元素。
2.2、比较
- 不带头链表在第一个结点之前插入和删除第一个结点的时候,会出现特殊情况,使得操作不方便。
带头链表,因为第一个有效的结点实际上是第二结点,所以避免了上述的情况。
3、基于C++的代码
3.1、给出类的基本构造
#include <iostream>
using namespace std;
template<class T>
class Node
{
private:
Node* link;
T element;
public:
Node* getLink(){return link;}
T getElement(){return element;}
void setElement(T x){element = x;}
void setLink(Node<T>* x){link = x;}
};
template<class T>
class SingleList
{
public:
SingleList() { first = new Node<T>; first->setLink(NULL); length = 0; };
~SingleList();
bool isEmpty() const;
int Length() const;
bool Find(int i, T& x)const;
Node<T>* Find(int i)const;
int Search(T x)const;
bool Insert(int i, T x);
bool Delete(int i);
bool Update(int i, T x);
void Clear();
void Output(ostream& out)const;
private:
Node<T>*first;
int length;
};- Node类是结点类
- isEmpty返回bool类型,判断表是否为空
- Length返回表长度
- Find(int i, T& x),找到第i个结点,并将结点内的值放在x中保存
- Find(int i) 找到第i个结点并返回
- Search找到指定元素,并返回其位置
- Insert向指定位置插入元素
- Delete删除指定位置元素
- Update更新指定位置元素
- Clear清除表
Output输出表中元素
3.2、类的实现
template<class T>
void SingleList<T>::Output(ostream& out) const
{
if (length==0)
{
out<<"The SingeList is null";
return;
}
Node<T>*p = first->getLink();
while (p != NULL)
{
out << p->getElement() << " ";
p = p->getLink();
}
out << endl;
}
template<class T>
void SingleList<T>::Clear()
{
Node<T>*p = first->getLink();
while (p != NULL)
{
Node<T>* q = p;
p = p->getLink();
delete q;
}
length = 0;
}
template<class T>
bool SingleList<T>::Update(int i, T x)
{
Node<T>* p = Find(i);
if (p == NULL) return false;
p->setElement(x);
return true;
}
template<class T>
bool SingleList<T>::Delete(int i)
{
Node<T>*p;
if (i == 0)
p = first;
else
{
p = Find(i - 1);
if (p == NULL)return false;
}
//找到第i-1个结点
Node<T>*q = p->getLink();//q是第i个结点
p->setLink(q->getLink());//第i-1个结点指向第i+1个结点
delete q;//删除第i个结点
length--;//减小长度
return true;
}
template<class T>
bool SingleList<T>::Insert(int i, T x)
{
Node<T>*p;
if (i==0)
p = first;
else
{
p = Find(i - 1);
if (p == NULL)return false;
}
//以上是找到第i-1个结点,越界判断在Find函数里
Node<T>* newNode = new Node<T>;//生成新插入的结点
newNode->setElement(x);//赋值
newNode->setLink(p->getLink());//新结点指向原来的第i个结点
p->setLink(newNode);//第i-1个结点指向新结点
length++;//表长度增加
return true;
}
template<class T>
int SingleList<T>::Search(T x) const
{
if (length == 0)//如果表里没有元素,则直接返回
{
cout << "The SingleList is null!";
return -1;
}
Node<T>*p = first->getLink();
int position = 0;//位置信息
while (p != NULL)
{
if (p->getElement() == x) return position;//找到元素,返回位置
p = p->getLink();
position++;
}
cout << "Don't find the element!";
return -1;
}
template<class T>
Node<T>* SingleList<T>::Find(int i) const
{
if (i > length - 1 || i < 0)//越界检查
{
cout << "Out of Bounds!";
return NULL;
}
Node<T>* p = first->getLink();//从第一个有效元素开始查找
for (int j = 0; j < i; j++)
{
p = p->getLink();//逐个调整,知道指向第i个元素
}
return p;
}
template<class T>
bool SingleList<T>::Find(int i, T& x) const
{
Node<T>* p = Find(i);
if (p == NULL) return false;
x = p->getElement();
return true;
}
template<class T>
int SingleList<T>::Length() const
{
return length;
}
template<class T>
bool SingleList<T>::isEmpty() const
{
if (length == 0) return true;
else return false;
}
template<class T>
SingleList<T>::~SingleList()
{
Node<T>*p;
while (first != NULL)
{
p = first->getLink();//找到当前删除结点的下一个结点
delete first;//删除当前结点
first = p;
}
}除了删除和插入以外,其他的方法实现起来都不困难,唯一有些复杂的就是插入和删除,要想好先后执行的操作,从老师的PPT里找到的图片
[插入和删除.png](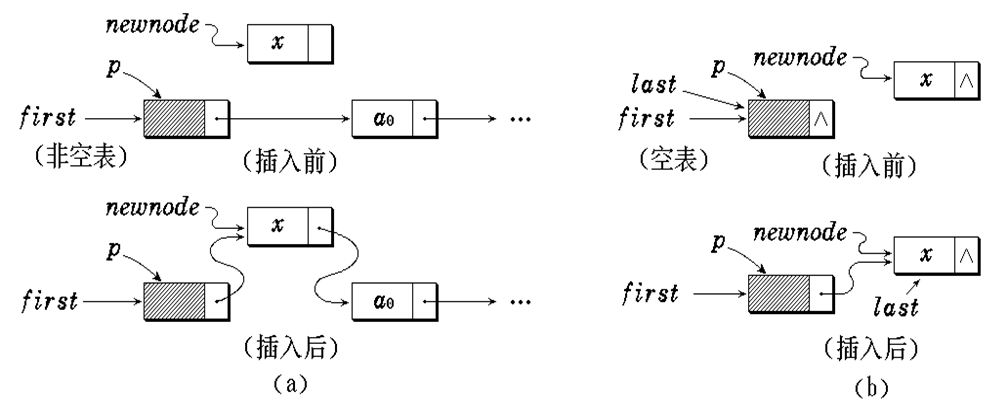
)
- 插入时,先将新结点指向原来的第i个结点,再让第i-1个结点指向新结点。
- 删除时,找到第i-1个结点和第i个结点,让第i-1个结点指向第i+1个结点,删除第i个结点。
至此整个基本的带头单链表就完成了,让我们来测试一下吧!
4、测试
测试代码如下
#include "SingleList.h"
#include "iostream"
using namespace std;
int main()
{
SingleList<int> newlist;
newlist.Insert(0, 1);
newlist.Insert(0, 2);
newlist.Insert(0, 3);
newlist.Insert(0, 4);
newlist.Insert(2, 20);
newlist.Output(cout);
newlist.Delete(1);
newlist.Output(cout);
cout<<newlist.Length()<<endl;
cout << newlist.isEmpty() << endl;
cout << newlist.Search(1)<<endl;
cout << newlist.Search(5)<<endl;
int n;
newlist.Find(1, n);
cout << n << endl;
cout << newlist.Find(2)->getElement()<<endl;
newlist.Update(2, 55);
newlist.Output(cout);
newlist.Clear();
newlist.Find(0);
cin >> n;
return 0;
}我们先预测一下输出,应该是
4 3 20 2 1
4 20 2 1
4
0
3
don't find the element!
20
2
4 20 55 1
out of bounds!
运行程序
运行结果符合我们的预期,这样就基本实现了单链表















 3560
3560











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









