






注意:前面讲到的各种操作都是一次http请求操作一条数据,如果想要操作多条数据就会产生多次请求,所以就有了mget和bulk批量操作,mget和bulk批量操作是一次请求可以操作多条数据
1、mget批量操作(查询)
批量操作(同一个索引同一个表里的批量查询)
说明:

#mget批量操作(同一个表里的批量查询)
GET _mget
{
"docs":[
{
"_index":"索引名称",
"_type":"表名称",
"_id":id号
},
{
"_index":"索引名称",
"_type":"表名称",
"_id":id号
}
]
}
代码:
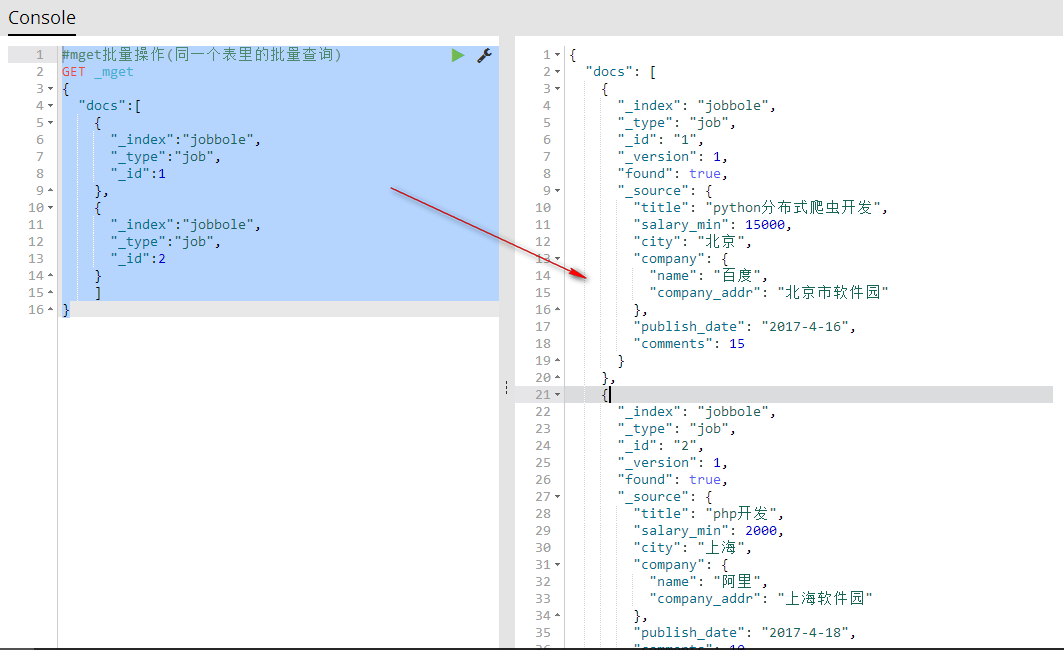
#mget批量操作(同一个表里的批量查询)
GET _mget
{
"docs":[
{
"_index":"jobbole",
"_type":"job",
"_id":1
},
{
"_index":"jobbole",
"_type":"job",
"_id":2
}
]
}
批量操作(同一个索引同一个表里的不同id批量查询)
#批量操作(同一个索引同一个表里的不同id批量查询)
GET jobbole/job/_mget
{
"ids":[1,2]
}
批量操作(同一个索引不同表里的批量查询)
#mget批量操作(同一个索引不同表里的批量查询)
GET jobbole/_mget
{
"docs":[
{
"_type":"job",
"_id":1
},
{
"_type":"job2",
"_id":1
}
]
}
批量操作(不同索引不同表里的批量查询,相当于数据库的组合查询)
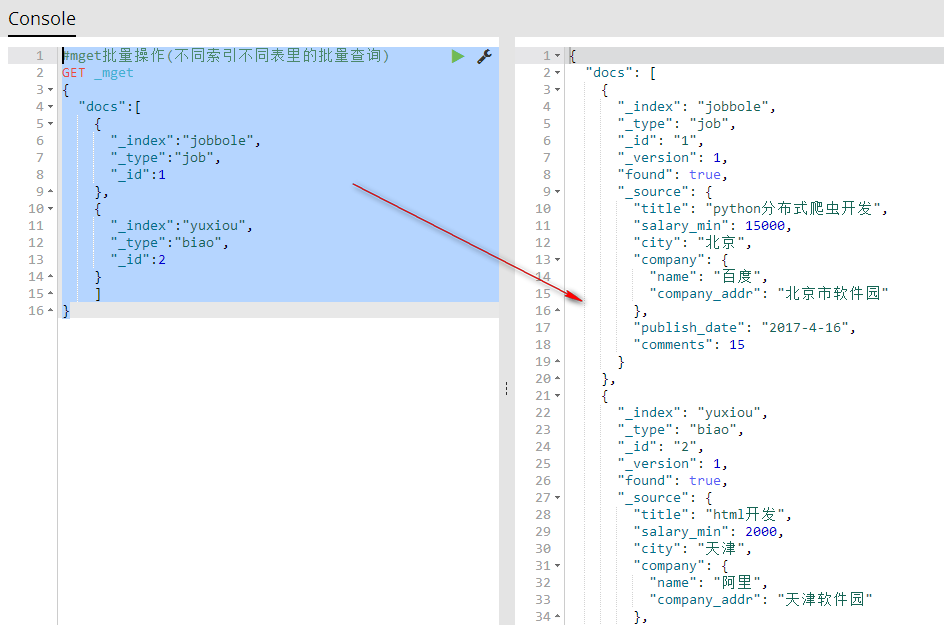
#mget批量操作(不同索引不同表里的批量查询)
GET _mget
{
"docs":[
{
"_index":"jobbole",
"_type":"job",
"_id":1
},
{
"_index":"yuxiou",
"_type":"biao",
"_id":2
}
]
}
2、bulk批量操作(增删改)
批量导入可以合并多个操作,比如index,delete,update,create等等。也可以帮助从一个索引导入到另一个索引

bulk批量操作批量添加数据
说明:添加一条数据由两行代码实现,第一行设置添加数据的索引名称、表、id,第二行设置添加数据的字段和值
#_bulk批量添加数据
POST _bulk
#设置添加数据的索引名称、表、id
{"index":{"_index":"jobbole","_type":"job","_id":"4"}}
#设置添加数据的字段和值
{"title": "爬虫开发","salary_min": 15000,"city": "北京","company": {"name": "百度","company_addr": "北京市软件园"},"publish_date": "2017-4-16","comments": 15}
#设置添加数据的索引名称、表、id
{"index":{"_index":"jobbole","_type":"job","_id":"5"}}
#设置添加数据的字段和值
{"title": "微信开发","salary_min": 15000,"city": "北京","company": {"name": "百度","company_addr": "北京市软件园"},"publish_date": "2017-4-16","comments": 15}
代码:
POST _bulk
{"index":{"_index":"jobbole","_type":"job","_id":"4"}}
{"title": "爬虫开发","salary_min": 15000,"city": "北京","company": {"name": "百度","company_addr": "北京市软件园"},"publish_date": "2017-4-16","comments": 15}
{"index":{"_index":"jobbole","_type":"job","_id":"5"}}
{"title": "微信开发","salary_min": 15000,"city": "北京","company": {"name": "百度","company_addr": "北京市软件园"},"publish_date": "2017-4-16","comments": 15}

bulk批量操作批量创建数据(添加)
POST _bulk
{"create":{"_index":"jobbole","_type":"job","_id":"6"}}
{"title": "开发","salary_min": 100,"city": "北京","company": {"name": "百度","company_addr": "北京市软件园"},"publish_date": "2017-4-16","comments": 15}
bulk批量操作批量删除数据
POST _bulk
{"delete":{"_index":"jobbole","_type":"job","_id":"5"}}
{"delete":{"_index":"jobbole","_type":"job","_id":"6"}}
bulk批量操作批量修改数据
POST _bulk
{"update":{"_index":"jobbole","_type":"job","_id":"1"}}
{"doc":{"title": "开发","salary_min": 100,"city": "北京","company": {"name": "百度","company_addr": "北京市软件园"},"publish_date": "2017-4-16","comments": 15}}















 618
618











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









