






参考自《Language Implementation Patterns》第4章。
----------------------------------------------
识别语句时,需要关心元素的顺序,同时也要考虑元素之间的关系(嵌套);用树状结构较好(同时可参考xml及lisp,话说含嵌套的list应该就可以理解为tree了吧);parse在进行自顶向下解析的时候一般是可以描绘出parse tree的(它恰好是parse的执行轨迹)。比如在解析x=0;时是通过这样的规则的:
statement:assignment
|...
;
assignment:ID '=' expr
|...
;
expr:...
;
用(已经简化了的)解析树表示就是:
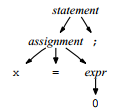
但是这其中涉及到的内部节点其实只在解析过程中有用,那些assignment这类的都只是中间表达形式,真正有用的是叶子节点(terminal);同时这样的树遍历起来也不方便。所以只要能解析(在这里就是抽象地表达赋值语句)并构建其他数据结构(可能下面的阶段会用到),用AST就行了。
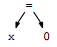
在AST中,操作符的优先级越高,位置越低;这和写规则的时候用到的中间变量的层次是一样的。比如含有+,-,*,/的单数字文法:
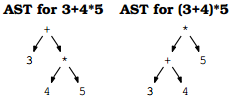
expr:expr+term|expr-term|term;
term:term*factor|term/factor|factor;
factor:digit|(expr);
digit:[0-9];
前序表达式可以唯一确定树的形式,这可以作为树的文本表示形式(又是lisp)。
对于不含可执行语句的语句,可定义伪操作(如graphivz);对输入中没有作为root节点的token时可定义虚token(如c中的声明)。
理论上说AST节点其实只要一种数据结构就OK了,这样设计的AST结构成为同型AST。下面是java的一个实现。
public class AST {
Token token;
List children;
public AST(Token token) {
this.token = token;
}
public void addChild(AST t) {
if (children == null)
children = new ArrayList();
children.add(t);
}
...
}
这里用于区分不同类型语句的其实是靠token的类型来完成的,就像这样tree.token.getType()。这样的设计渣的地方显而易见。首先类型token的属性而不是节点的属性,带来的性能上的问题很大;很明显一般来说这样的代码是需要重构的。其次如果要添加额外信息的话不管三七二十一所有节点都得加上,代价太大。虽然simple&stupid,但对于OO思想占主流的时代这样的数据结构显然不能令人满意啊(这不gcc都用C++写了)。因此有了异型AST(又分为规范子节点和不规则子节点两种),以后详述。















 1019
1019











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









