






目录
class tf.train.RMSPropOptimizer
class tf.train.ExponentialMovingAverage
tf.global_variables_initializer()
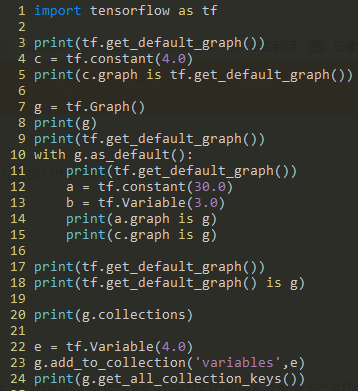
Class Graph 返回目录
定义
tensorflow是数据流图,所有的运算都要预先定义在图上

若没有指定图,程序会有一个默认的注册图,可以通过 tf.get_Default_graph 得到当前的默认图,若要在当前默认图中加上新的运算,只需要简单地进行定义就好了
tf.Graph.as_default() 是一个上下文管理器,这个函数会覆盖当前的默认图在指定的上下文中重新定义默认图

在图上定义的节点可以通过collection一次性取出变量集合
Properties
collections Returns the names of the collections known to this graph.
Methods
add_to_collection(name,value) Stores value in the collection with the given name, Note that collections are not sets, so it is possible to add a value to a collection several times.

add_to_collections(names,value) 把value加入到多个collection里面
as_default() returns a context manager that makes this Graph the default graph


control_dependencies(control_inputs) returns a context manager that specifies control dependencies

device(device_name_or_function) returns a context manager that specifies the default device to use

None起到了消除当前设置的作用
finalize() Finalizes this graph, making it reaad-only, no new oprations can be added to graph
get_all_collection_keys() Returns a list of collections used in this graph
get_collection(name,scope=None) Returns a list of values in the collection with the given name

get_name_scope() Returns the current name scope
name_scope(name) Returns a context manager that creates hierarchical names for operations

Utility functions (Wrapper)
- tf.device() tf.Graph().device()
- tf.name_scope tf.Graph().name_scope()
- tf.control_dependencies() tf.Graph().control_dependencies()
- tf.get_default_graph()
- tf.add_to_collection() tf.Graph().add_to_collection()
- tf.get_collection() tf.Graph().get_collection()
- tf.GraphKeys()
tf.get_variable() 返回目录

Gets an existing variable with these parameters or create a new one, This function prefixes the name with the current variable scope and performs reuse checks
对于reuse=True的变量可以通过名字获取该变量,如果没有名字的话就会报错,想要用get_variable创建新变量的话就需要在reuse=False的环境下
1 def foo(): 2 with tf.variable_scope("foo",reuse=True): 3 v = tf.get_variable("v",[1]) 4 return v 5 v1 = foo()

1 def foo(): 2 with tf.variable_scope("foo",reuse=False): 3 v = tf.get_variable("v",[1]) 4 return v 5 v1 = foo() 6 v2 = foo()


- 当
tf.get_variable_scope().reuse = = False时,作用域就是为创建新变量所设置的 - 当
tf.get_variable_scope().reuse = = True时,作用域是为重用变量所设置
想要解决上面的问题,由两种方法,一个自动改,一个手动改
在Tensorflow1.4有定义reuse=tf.AUTOREUSE 就可以同时兼顾这两种情况

不用上面的方法,就要手动修改reuse的状态
1 import tensorflow as tf 2 3 def foo(): 4 with tf.variable_scope("foo"): 5 v = tf.get_variable("v",[1]) 6 return v 7 v1 = foo() 8 tf.get_variable_scope().reuse_variables() 9 v2 = foo() 10 print(v1==v2) 11 print(v1.name,v2.name) 12 13 def foo2(): 14 with tf.variable_scope("foo2",reuse=True): 15 v = tf.Variable(3,name="v1") 16 return v 17 v1 = foo2() 18 v2 = foo2() 19 print(v1==v2) 20 print(v1.name,v2.name) 21 22 v1 = tf.Variable(3,name="v") 23 v2 = tf.Variable(3,name="v") 24 print(v1==v2) 25 print(v1.name,v2.name)
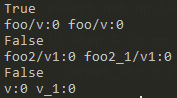
上面这种方式会使tf.get_variable_scope().reuse_variables()后面所有的作用域都可以reuse变量,所有不可取,通常都是在一个上下文管理器内部使用,如下:
1 with tf.variable_scope("image_filters") as scope: 2 result1 = my_image_filter(image1) 3 scope.reuse_variables() 4 result2 = my_image_filter(image2)
tf.Variable初始化如下:
1 conv1_weights = tf.Variable(tf.random_normal([5, 5, 32, 32]),name="conv1_weights") 2 conv1_biases = tf.Variable(tf.zeros([32]), name="conv1_biases")
tf.get_variable()初始化是要在参数里设置初始化器的:
tf.constant_initializer(value)initializes everything to the provided value, 常量初始化tf.random_uniform_initializer(a, b)initializes uniformly from [a, b], 均匀分布tf.random_normal_initializer(mean, stddev)initializes from the normal distribution with the given mean and standard deviation.正态分布
1 weights = tf.get_variable("weights", kernel_shape,initializer=tf.random_normal_initializer()) 2 biases = tf.get_variable("biases", bias_shape,initializer=tf.constant_initializer(0.0))
tf.train.global_step() 返回目录
global_step refer to the number of batches seen by the graph. Everytime a batch is provided, the weights are updated in the direction that minimizes the loss. global_step just keeps track of the number of batches seen so far.
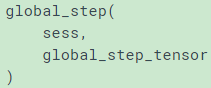

先要创建一个变量来存放global_step的值,这时,用tf.Variable创建就可以,10是初始值, trainable一定要设置成False,这样梯度传播时就不会修改global_step,注意name='global_step'一定不能变,因为这已经放在了系统变量中,global_step_tensor取名是可以随意取的,一般都是直接取名为global_step;
tf.train.global_step()用来获取当前sess的global_step值
建立global_step变量的方法如下:
1 global_step = tf.Variable(0,trainable=False,name='global_step') 2 global_step = tf.get_variable('global_step',[],initializer=tf.constant_initializer(0),trainable=False)
本来是需要手动对global_step进行+1操作,但是在实际应用中,操作会在'tf.train.Optimizer.apply_gradients'内部完成 如果是使用minimize,注意要将global_step作为参数传入minimize
1 global_step = tf.Variable(0,trainable=False) 2 increment_op = tf.assign_add(global_step,tf.constant(1)) 3 sess = tf.Session() 4 init = tf.global_variables_initializer() 5 sess.run(init) 6 for step in range(0,10): 7 .... 8 sess.run(increment_op)
tf.train.exponential_decay() 返回目录

指数衰减公式如下:

staircase=True 表示 global_step/decay_steps 是整数操作,所以衰减图像时阶梯状的 decay_steps表示经过多少步衰减一次
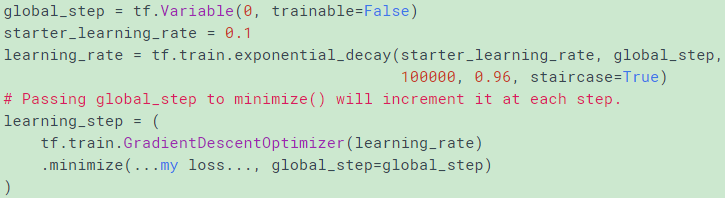
这个唯一问题就是只能等距衰减
要想不等距衰减学习率,只能手动设置if-else赋值了
class tf.train.RMSPropOptimizer() 返回目录

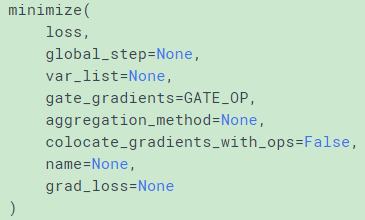
This method simply combines calls compute_gradients() and apply_gradients(). If you want to process the gradient before applying them call compute_gradients() and apply_gradients() explicitly instead of using this function.
minimize = compute_gradients() + apply_gradients()

This is the first part of minimize(). It returns a list of (gradient, variable) pairs where "gradient" is the gradient for "variable". Note that "gradient" can be a Tensor, an IndexedSlices, or None if there is no gradient for the given variable.
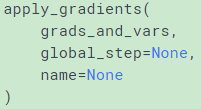
This is the second part of minimize(). It returns an Operation that applies gradients.
tf.get_collection() 返回目录
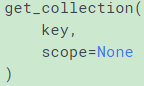
Wrapper for Graph.get_collection() using the default graph
Return a list of values in the collection with the given name.
就是把图中是属于key这一类的变量一块取出来,常见的key有tf.GraphKeys这个类里面的
tf.GraphKeys 返回目录
Standard names to use for graph collections

- tf.GraphKeys.GLOBAL_VARIABLES: 所有 Variable objects
- tf.GraphKeys.LOCAL_VARIABLES: local to each machine, subset of Variable
- tf.GraphKeys.MODEL_VARIABLES: Variable objects used in the model for inference( feed forward)
- tf.GraphKeys.TRAINABLE_VARIABLES: Variable objects that will be trained by an optimizer (tf.Variable(trainable=True) default is True)
- tf.GraphKeys.SUMMARIES: the summary tensor objects that have been created in the graph, 在图上定义的所有的summary对象 tf.summary.merge_all(key=tf.GraphKeys.SUMMARIES)
- tf.GraphKeys.MOVING_AVERAGE_VARIABLES: all variables that maintain their moving averages, if ExponetialMovingAverage object is created and apply() method is called on a list of variables,these variables will be added to the collection
- tf.GraphKeys.REGULARIZATION_LOSSES: regularization losses collected during graph construction
- tf.GraphKeys.LOSSES: tf.losses.add_loss(loss,loss_collection=tf.GraphKeys.LOSSES) tf.losses.get_losses(scope=None,loss_collection=tf.GraphKeys.LOSSES)
- tf.GraphKeys.UPDATE_OPS batch_norm中的moving_mean and moving_variance的更新操作(滑动平均)是要tf.add_to_collection(tf.GraphKeys.UPDATE_OPS,update_moving_mean),然后作为train_op的denpendency
可以通过wrapper方便获取以上collection
- tf.trainable_variables() : tf.GraphKeys.TRAINABLE_VARIABLES 训练时,更新其中所有变量
- tf.moving_average_variables() : tf.GraphKeys.MOVING_AVERAGE_VARIABLES 当ExponentialMovingAverage 的apply方法应用到变量上时,那些变量都会自动加入到MOVING_AVERAGE_VARIABLES中
还可以自定义collection的名字,比如
1 tf.add_to_collection("losses",l1) 2 tf.add_to_collection("losses",l2) 3 losses = tf.get_collection("losses") 4 loss_total = tf.add_n(losses)
tf.global_variables_initializer() 返回目录
在整个session运行之前,图中所有的变量Variable必须被初始化
1 sess = tf.Session() 2 init = tf.global_variables_initializer() 3 sess.run(init)
在执行初始化后,Variable中的值生成完毕,不会再变化
class tf.train.ExponentailMovingAverage 返回目录
When training a model, it is often beneficial to maintain moving averages of the trained parameters. Evaluations that use averaged parameters sometimes produce significantly better results than the final trained values.
The apply() method adds shadow copies of trained variables and add ops that maintain a moving average of the trained variables in their shadow copies. It is used when building the training model. The ops that maintain moving averages are typically run after each training step. The average() and average_name() methods give access to the shadow variables and their names. They are useful when building an evaluation model, or when restoring a model from a checkpoint file. They help use the moving averages in place of the last trained values for evaluations.
就是说对某些变量在训练过程中就创建一个影子变量,训练过程不断更新它的结果,之后用于test阶段(就是保存变量的统计平均值)
shadowVariable = decay*shadowVariable + (1-decay)*variable
shadow variables are created with trainalbe=False 用其来存放ema的值
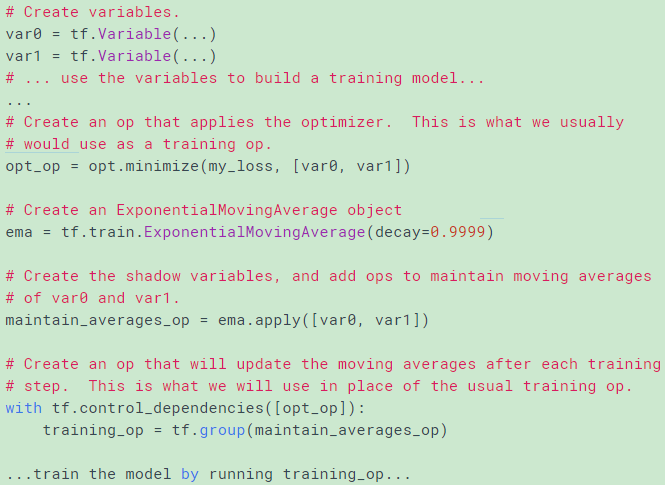
有两种在测试阶段使用moving averages的方法
- use the average() method which returns the shadow variable for a given variable
- load the checkpoint files by shadow variable names: using average_name()

checkpoint文件中保存的变量名是shadow_var0_name,从文件中找到该变量然后载入到var0变量中
tf.train.ExponentialMovingAverage.variables_to_restore(moving_avg_variables=None)
Returns a map of names to Variables to restore.
Args:
moving_avg_variables: a list of variables that require to use of the moving variable name to be restored. If None, it will default to variables.moving_average_variables() + variables.trainable_variables()
tf.group() tf.tuple() 返回目录

当有很多tensor或op想要一起run,这两个函数很方便
1 w = tf.Variable(1) 2 mul = tf.multiply(w, 2) 3 add = tf.add(w, 2) 4 group = tf.group(mul, add) 5 tuple = tf.tuple([mul, add])
# sess.run(group)和sess.run(tuple)都会求Tensor(add),Tensor(mul)的值。
区别是,tf.group()返回的是`op`。tf.tuple()返回的是list of tensor。
#这样就会导致,sess.run(tuple)的时候,会返回 Tensor(mul),Tensor(add)的值.而 sess.run(group)不会
可以认为group只是将多个op结点连接到一个结点上,当run这个结点时,其他的结点都要run,不会返回所有结点的结果
而tuple只是作为一个列表进行同时运行
注意: tf.group(*[mul,add])需要把括号去掉, tf.tuple([mul,add])需要括号
tf.ConfigProto() 返回目录



1 # Using the `close()` method. 2 sess = tf.Session() 3 sess.run(...) 4 sess.close() 5 6 # Using the context manager. 7 with tf.Session() as sess: 8 sess.run(...)
tf.train.get_checkpoint_state() 返回目录

Returns CheckpointState proto from the "checkpoint" file.
If the "checkpoint" file contains a valid CheckpointState proto, returns it.
1 ckpt = tf.train.get_checkpoint_state(FLAGS.pretrained_model_checkpoint_path) 2 if os.path.isabs(ckpt.model_checkpoint_path): 3 saver.restore(sess,ckpt.model_checkpoint_path) 4 else:
5 saver.restore(sess,os.path.join(FLAGS.pretrained_model_checkpoint_path,ckpt.model_checkpoint_path))
tf.train.get_checkpoint_state是个class,它的属性ckpt.model_checkpoint_path是在checkpoint文件的第一行

其实直接saver.restore(sess,"/home/ling.hu/imagenet_model/inception_log/lsun_train/model.ckpt-129999")
tf.concat() 返回目录


concat的 axis方向维度concat后增加,非axis方向维度不变
tf.reduce_mean() 返回目录


对axis方向所有的元素进行求平均,axis方向维度变为1,其他方向不变
keep_dims=False, the rank is reduced by 1; True的话,retains reduced dimensions with length 1
tf.expand_dims() 返回目录
对tensor进行增加维度,但是不增加元素, 要增加元素的增加维度就用concat

Inserts a dimension of 1 into a tensor's shape

tf.gfile.Glob() 返回目录

1 def data_files(self): 2 """Returns a python list of all (sharded) data subset files. 3 4 Returns: 5 python list of all (sharded) data set files. 6 Raises: 7 ValueError: if there are not data_files matching the subset. 8 """ 9 tf_record_pattern = os.path.join(FLAGS.data_dir, '%s-*' % self.subset) 10 data_files = tf.gfile.Glob(tf_record_pattern) 11 if not data_files: 12 print('No files found for dataset %s/%s at %s' % (self.name, 13 self.subset, 14 FLAGS.data_dir)) 15 return data_files
tf.sparse_to_dense 返回目录
1 sparse_to_dense( 2 sparse_indices, 3 output_shape, 4 sparse_values, 5 default_value=0, 6 validate_indices=True, 7 name=None 8 )
1 # If sparse_indices is scalar 2 dense[i] = (i == sparse_indices ? sparse_values : default_value) 3 4 # If sparse_indices is a vector, then for each i 5 dense[sparse_indices[i]] = sparse_values[i] 6 7 # If sparse_indices is an n by d matrix, then for each i in [0, n) 8 dense[sparse_indices[i][0], ..., sparse_indices[i][d-1]] = sparse_values[i]
Args:
sparse_indices: A 0-D, 1-D, or 2-DTensorof typeint32orint64.sparse_indices[i]contains the complete index wheresparse_values[i]will be placed.output_shape: A 1-DTensorof the same type assparse_indices. Shape of the dense output tensor.sparse_values: A 0-D or 1-DTensor. Values corresponding to each row ofsparse_indices, or a scalar value to be used for all sparse indices.default_value: A 0-DTensorof the same type assparse_values. Value to set for indices not specified insparse_indices. Defaults to zero.validate_indices: A boolean value. If True, indices are checked to make sure they are sorted in lexicographic order and that there are no repeats.name: A name for the operation (optional).
常用于将数字标签转换成onehot标签
为什么要使用tf.expand_dims扩维:
1 t1=tf.constant([1,2,3]) 2 t2=tf.constant([4,5,6]) 3 #concated = tf.concat(1, [t1,t2])这样会报错 4 t1=tf.expand_dims(tf.constant([1,2,3]),1) 5 t2=tf.expand_dims(tf.constant([4,5,6]),1) 6 concated = tf.concat(1, [t1,t2])#这样就是正确的
使用tf.expand_dims(vectore,1)将行向量vector转换成一个nx1的列向量
1 BATCHSIZE=6 2 label=tf.expand_dims(tf.constant([0,2,3,6,7,9]),1) 3 index=tf.expand_dims(tf.range(0, BATCHSIZE),1) 4 concated = tf.concat(1, [index, label])
结果如下:

1 onehot_labels = tf.sparse_to_dense(concated, tf.pack([BATCHSIZE,10]), 1.0, 0.0)
最后一步,调用tf.sparse_to_dense输出一个onehot标签的矩阵,输出的shape就是行数为BATCHSIZE,列数为10的矩阵,指定元素值为1.0,其余元素值为0.0














 1142
1142











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









