






MySQL
数据库
MySQL checkpoint深入分析

一、日常关注的问题
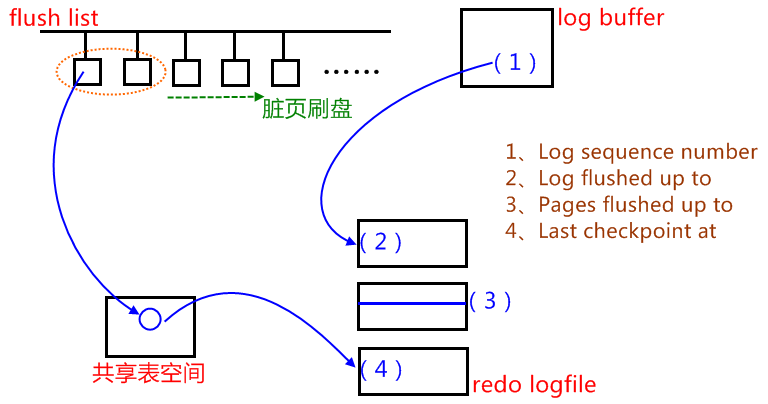
1、我们的日志生成速度?
1、每天生成多少日志、产生多少redo log
mysql> show global status like 'Innodb_os_log_written';+-----------------------+--------+
| Variable_name | Value |
+-----------------------+--------+
| Innodb_os_log_written | 107008 |
+-----------------------+--------+
1 row in set (0.01 sec)
2、如果redolog量大,需要修改如下参数,增加logfile的大小和组数
mysql> show variables like 'i%log_file%';+---------------------------+----------+
| Variable_name | Value |
+---------------------------+----------+
| innodb_log_file_size | 50331648 |
| innodb_log_files_in_group | 2 |
+---------------------------+----------+
2 rows in set (0.00 sec)
2、日志写入速度?
Log buffer有没有满、满的话为什么满
mysql> show variables like 'i%log_buffer%';+------------------------+----------+
| Variable_name | Value |
+------------------------+----------+
| innodb_log_buffer_size | 16777216 |
+------------------------+----------+
1 row in set (0.01sec)
mysql> show global status like '%log_pending%';+------------------------------+-------+
| Variable_name | Value |
+------------------------------+-------+
| Innodb_os_log_pending_fsyncs | 0 |
| Innodb_os_log_pending_writes | 0 |
+------------------------------+-------+
2 rows in set (0.01 sec)
3、脏页的写入速度?
1、Log buffer满了会hang住
2、Logfile满了不能被覆盖也会hang住
3、如果脏页写入速度慢的话,logfile满了也不能被覆盖,系统容易hang住,log buffer如果满了的话也容易hang住。
4、数据库启动时间是多少?
启动时,默认是要先恢复脏页。当然,能通过参数innodb_force_recovery启动控制。
如果innodb_buffer_pool很大,32G,极端情况可能有32G的脏页,这个时候如果崩了,恢复的话需要恢复这32G的脏页,时间非常长。
二、日志点分析
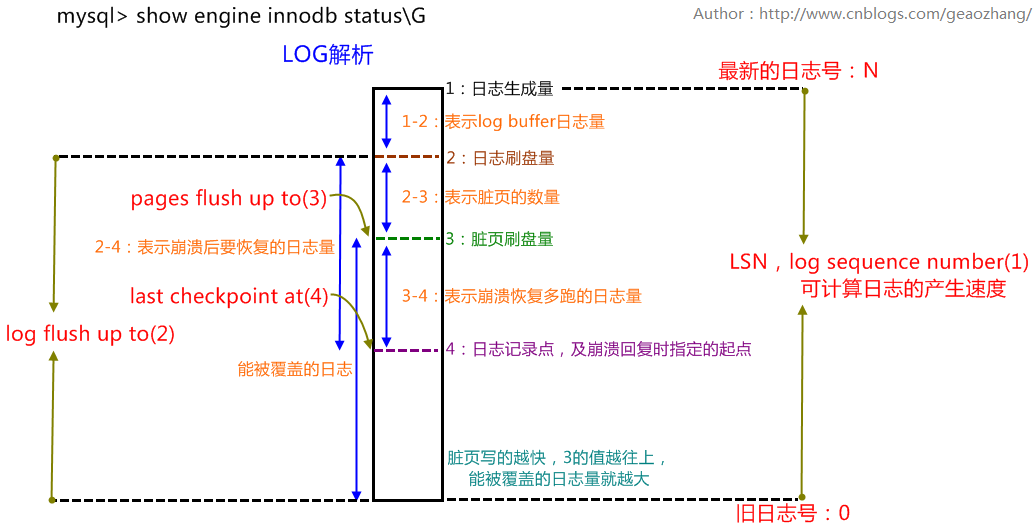
通过show engine innodb statusG解释一下LOG相关的四行参数的值:
Log sequence number 143942609---LSN:日志序列号(1)
//字节,日志生成的最新位置,最新位置出现在log buffer中
Log flushed up to 143942609---(2)
//字节,日志已经写入到log file的位置,1-2=log buffer日志量,最好是<=1M
Pages flushed up to 143942609---(3)
//字节,脏页的数量(日志字节数来衡量),2-3=脏页的数量(日志字节为单位)
Last checkpoint at 143942600---(4)
//字节,共享表空间上的日志记录点,最后一次检查点,及崩溃恢复时指定的起点,3-4就是崩溃恢复多跑的日志,值越大说明需要提升checkpoint的跟进速度
三、checkpoint
检查点,表示脏页写入到磁盘的时候,所以检查点也就意味着脏数据的写入。
1、checkpoint的目的
1、缩短数据库的恢复时间
2、buffer pool空间不够用时,将脏页刷新到磁盘
3、redolog不可用时,刷新脏页
2、检查点分类
1、sharp checkpoint:完全检查点,数据库正常关闭时,会触发把所有的脏页都写入到磁盘上(这时候logfile的日志就没用了,脏页已经写到磁盘上了)。
1、完全检查点,发生在数据库正常关闭的时候。
2、在数据库在运行时不会使用sharp checkpoint,在引擎内部使用fuzzy checkpoint,即只刷新一部分脏页,而不是刷新所有的脏页回磁盘。
2、fuzzy checkpoint:模糊检查点,部分页写入磁盘。
1、发生在数据库正常运行期间。
2、模糊检查点,不是sharp的就是模糊检查点(4种):master thread checkpoint、flush_lru_list checkpoint、async/sync flush checkpoint、dirty page too much checkpoint。
四、fuzzy checkpoint发生的4个条件
模糊检查点的发生,也就是脏页写入磁盘的情况。
1、master thread checkpoint
差不多以每秒或每十秒的速度从缓冲池的脏页列表中刷新一定比例的页回磁盘,这个过程是异步的,不会阻塞用户查询。
1、周期性,读取flush list,找到脏页,写入磁盘
2、写入的量比较小
3、异步,不影响业务
mysql> show variables like '%io_cap%';+------------------------+-------+
| Variable_name | Value |
+------------------------+-------+
| innodb_io_capacity | 200 |
| innodb_io_capacity_max | 2000 |
+------------------------+-------+
2 rows in set (0.01 sec)
4、通过capacity能力告知进行刷盘控制
通过innodb的io能力告知控制对flush list刷脏页数量,io_capacity越高,每次刷盘写入脏页数越多;
如果脏页数量过多,刷盘速度很慢,在io能力允许的情况下,调高innodb_io_capacity值,让多刷脏页。
2、flush_lru_list checkpoint
MySQL会保证,保证里面有多少可用的空闲页,在innodb 1.1.x版本之前,需要检查在用户查询线程中是否有足够的可用空间(差不多100个空闲页),显然这会阻塞用户线程,如果没有100个可用空闲页,那么innodbhi将lru列表尾端的页移除,如果这些页中有脏页,那么需要进行checkpoint。Innodb 1.2(5.6)之后把他单独放到一个线程page cleaner中进行,用户可以通过参数innodb_lru_scan_depth控制lru列表中可用页的数量,默认是1024。
读取lru list,找到脏页,写入磁盘。
mysql> show variables like '%lru%depth';+-----------------------+-------+
| Variable_name | Value |
+-----------------------+-------+
| innodb_lru_scan_depth | 1024 |
+-----------------------+-------+
1 row in set (0.01 sec)
此情况下触发,默认扫描1024个lru冷端数据页,将脏页写入磁盘(有10个就刷10,有100个就刷100个……)
3、async/sync flush checkpoint
log file快满了,会批量的触发数据页回写,这个事件触发的时候又分为异步和同步,不可被覆盖的redolog占log file的比值:75%--->异步、90%--->同步。
当这两个事件中的任何一个发生的时候,都会记录到errlog中,一旦errlog出现这种日志提示,一定需要加大logfile。
Async/Sync Flush Checkpoint是为了保证重做日志的循环使用的可用性。在InnoDB 1.2.x版本之前,Async Flush Checkpoint会阻塞发现问题的用户查询线程,而Sync Flush Checkpoint会阻塞所有的用户查询线程,并且等待脏页刷新完成。从InnoDB 1.2.x版本开始——也就是MySQL 5.6版本,这部分的刷新操作同样放入到了单独的Page Cleaner Thread中,故不会阻塞用户查询线程。
4、dirty page too much checkpoint
很明显,脏页太多检查点,为了保证buffer pool的空间可用性的一个检查点。
1、脏页监控,关注点
mysql> show global status like 'Innodb_buffer_pool_pages%t%';+--------------------------------+-------+
| Variable_name | Value |
+--------------------------------+-------+
| Innodb_buffer_pool_pages_data | 2964 |
| Innodb_buffer_pool_pages_dirty | 0 |
| Innodb_buffer_pool_pages_total | 8191 |
+--------------------------------+-------+
3 rows in set (0.00sec)
mysql> show global status like '%wait_free';+------------------------------+-------+
| Variable_name | Value |
+------------------------------+-------+
| Innodb_buffer_pool_wait_free | 0 |
+------------------------------+-------+
1 row in set (0.00 sec)
1、Innodb_buffer_pool_pages_dirty/Innodb_buffer_pool_pages_total:表示脏页在buffer 的占比
2、Innodb_buffer_pool_wait_free:如果>0,说明出现性能负载,buffer pool中没有干净可用块
2、脏页控制参数
mysql> show variables like '%dirty%pct%';+--------------------------------+-----------+
| Variable_name | Value |
+--------------------------------+-----------+
| innodb_max_dirty_pages_pct | 75.000000 |
| innodb_max_dirty_pages_pct_lwm | 0.000000 |
+--------------------------------+-----------+
2 rows in set (0.01 sec)
1、默认是脏页占比75%的时候,就会触发刷盘,将脏页写入磁盘,腾出内存空间。建议不调,调太低的话,io压力就会很大,但是崩溃恢复就很快;
2、lwm:low water mark低水位线,刷盘到该低水位线就不写脏页了,0也就是不限制。
注意:上面在调整的时候,要关注系统的写性能iostat -x。
内容来源于网络,如有侵权请联系客服删除














 259
259











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









