






在前面几课里的学习算法的思路都是给定数据集以后。确定基于此数据集的最佳如果H函数,通过学习算法确定最佳如果H的各个參数,然后通过最佳如果函数H得出新的数据集的结果。在这一课里介绍了一种新的思路,它的核心思想是直接计算各种如果的最高概率,然后拟合各个如果的最高概率參数,并利用拟合得到的如果概率,计算出新的数据集的概率,选取概率最高的如果直接得出分类类别。
整个生成学习算法的精髓在于条件概率的使用。在二元分类里,也能够称为分别算法。在给定的数据集里确定p(y) 和p(x|y),然后根据贝叶斯定理。得到
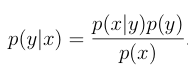
当中x|y=1)p(y=1)+p(x|y=0)p(y=0)。
为得到每种如果的最高概率,所以可知
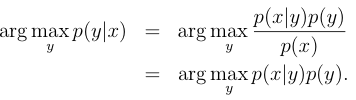
1、高斯分别算法(Gaussian discriminant analysis,GDA)
多元正太分布的函数这里就不具体展开了,以后会另开一个关于机器学习中的经常使用数学的博客专题。高斯分别算法面对的是连续变量x。在高斯分别分析模型
y~Bernoulli(φ )
x|y=0 ~N(μ0,Σ )
x|y=1∼ N(μ1,Σ)
所以它们的概率分布函数是:

在概率分布函数里的參数φ, Σ, μ0 and μ1 ,能够通过最大似然概率计算。似然概率函数为

最大化似然概率,可确定各參数值例如以下:
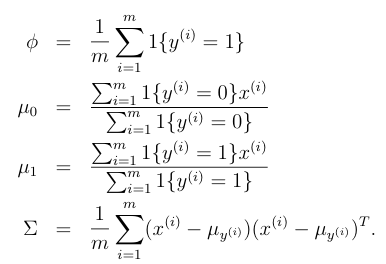
2、高斯分别算法和logistic回归算法的比較
两者都是针对分类问题。可是如果p(x|y)满足多元高斯分布,则能够推导出p(y|x)满足logistic回归。反之则不然。这说明高斯分别算法具有更好的模型如果性,在训练的时候须要更少的数据。在数据集大的时候,高斯分别算法比logistic回归算法更有效,一般而言。我们也觉得在数据集小的时候,高斯分别算法也更有效。logsitic回归算法具有更好的鲁棒性,在数据集明显不符合高斯分布的时候,logistic回归算法的效率比高斯分别算法的效率好。因此。实践中用到的很多其它的是logistic回归算法。
此外,当x|y = 0 ∼ Poisson(λ0) ,x|y = 1 ∼ Poisson(λ1) (满足指数簇)时,p (y|x)满足logistic回归。















 1044
1044

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









