






DFS & BFS
目录
概述
深度优先搜索和广度优先搜索是图论算法里的两种图的遍历方式,理解了两种搜索的原理之后,会发现算法和数据结构真的是不可分离的。
原理
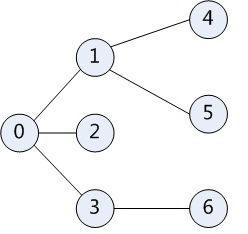
深度优先搜索
在访问图中的其中一个顶点时:- 把它标记为已访问;
- 递归地访问它的所有没有被标记过的邻居节点。
递归方法说明我们可以利用栈的特点来说明深度优先搜索,举一个例子就行了:
栈: FILO,先进后出,后进先出
假设遍历从0开始,那么
- 访问0,并标记为已访问,0入栈 (0)
- 先找到第一个节点1,访问它,并标记为已访问,1入栈 (1, 0)
- 再从1开始,访问1的邻接点4,并标记为已访问,4入栈 (4, 1, 0)
- 节点4没有邻接点了,4出栈,回到节点1,访问邻接点5,5入栈,并标记为已访问 (5, 1, 0)
- 节点5没有邻接点了,5出栈,回到节点1,节点1也没有邻接点了,1出栈,回到节点0 (0)
- 访问0的第二个邻接点2,2入栈,以此类推 (2, 0)
得到的深度优先搜索顺序应该是:0,1,4,5,2,3,6
这是一个不断入栈和出栈的过程广度优先搜索
在访问图中的其中一个顶点时:- 把它标记位已访问
- 先把所有邻接点遍历完,再遍历邻接点的所有邻接点
因此,遍历邻接点完成后,还要回到第一个邻接点处,来遍历其邻接点,再遍历第二个邻接点的邻接点,以此类推。可以用队列来说明广度优先搜索。
队列:FIFO,先进先出,后进后出
还是上面那张图来举例。
假设遍历从0开始,那么- 访问0,并标记为已访问
- 先找到第一个节点1,1入队 (1)
- 再相继找到余下的节点2和3,2,3相继入队 (3, 2, 1)
- 0没有邻接点了,队头出队,得到节点1 (3, 2)
- 访问1,并标记为已访问,重复以上步骤。
得到的广度优先搜索顺序应该是:0,1,2,3,4,5,6
这是一个不断入队和出队的过程
实现
原理弄清楚了,实现起来就很简单了,按照步骤写出来即可。
import java.util.*;
public class SearchTest {
public static void main(String[] args) {
Graph g = new Graph(7);
g.addEdge(0, 1);
g.addEdge(0, 2);
g.addEdge(0, 3);
g.addEdge(1, 4);
g.addEdge(1, 5);
g.addEdge(3, 6); // 按照节点关系的结构构造图
Search s = new Search(g);
System.out.println("dfs:");
s.dfs(0); // 从0开始搜索
s.clear();
System.out.println();
System.out.println("====================");
System.out.println("bfs:");
s.bfs(0);
}
}
class Search {
private boolean[] marked;
private int count;
private Graph G;
Queue<Integer> queue; // 用于bfs
public Search(Graph G) {
marked = new boolean[G.V()];
this.G = G;
queue = new LinkedList<Integer>();
}
/**
* v是顶点
*/
public void dfs(int v) {
marked[v] = true;
count++;
System.out.print(v + " "); // 以上三行,访问顶点并标记为已访问
for(int w: G.adj(v)) {
if(!marked[w]) dfs(w); // 若邻接点w没有被访问,以w为顶点,dfs
}
}
/**
* v为顶点
*/
public void bfs(int v) {
marked[v] = true;
count++;
System.out.print(v + " "); // 以上三行,访问顶点并标记为已访问
for(int w: G.adj(v)) {
if(!marked[w]) {
queue.offer(w); // 如果邻接点w没有被访问,放入队列
}
}
Integer head = queue.poll(); // v已经没有邻接点了,弹出队头
if(head != null) { // 如果队头存在
bfs(head); // 以队头为顶点,bfs
}
}
public int count() {
return count;
}
public void clear() {
count = 0;
for(int i = 0; i < marked.length; ++i) {
marked[i] = false;
}
}
}
@SuppressWarnings("unchecked")
class Graph {
private final int V; // 顶点数目
private int E; // 边的数目
private List<Integer>[] adj;
public Graph(int V) {
this.V = V;
adj = new ArrayList[V];
for(int v = 0; v < V; v++){
adj[v] = new ArrayList<>();
}
}
// 把顶点v和w连成一条边
public void addEdge(int v, int w) {
adj[v].add(w);
adj[w].add(v);
E++;
}
public int E() {
return E;
}
public int V() {
return V;
}
// 返回顶点v的所有邻接点的集合
public List<Integer> adj(int v) {
return adj[v];
}
}
//output
dfs:
0 1 4 5 2 3 6
====================
bfs:
0 1 2 3 4 5 6 Summary
DFS和BFS是两种图的遍历算法,很简洁,同时也是两种数据结构Stack和Queue的良好应用。
DataStructure & Algorithms –> Twins















 147
147

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









