






public class Test04 { public static void main(String[] args) { // TODO Auto-generated method stub //String str = "欢迎大家访问http://www.xiaojiang.cn了解、参观公司"; //String str = "网址:www.baidu.com"; String str = "网址:www.nwsuaf.edu.cn"; //String regex = "(http://)?www[.]\\w+\56{1}\\p{Alpha}+"; String regex = "(http://|www)\56?\\w+\56{1}\\w+\56{1}\\p{Alpha}+"; System.out.println("原字符串是:" + str + "替换后是:"); str = str.replaceAll(regex, "***"); System.out.println(str); String money = "89,235,678¥"; System.out.println(money + "转化成数字:"); String s = money.replaceAll("[,\\p{Sc}]" ,"");//"\\p{Sc}"可匹配任何货币符号 long number = Long.parseLong(s); System.out.println(number); } }
运行结果如下所示:
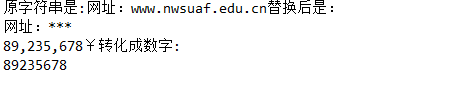
我认为上述的正则表达式无法匹配到字符串"www.baidu.com"但是它确实可以匹配到,这是什么原因不理解。
import java.util.regex.Matcher; import java.util.regex.Pattern; public class Test10 { public static void main(String[] args) { // TODO Auto-generated method stub Pattern p; Matcher m; String regex = "(http://|www)\56?\\w+\56{1}\\w+\56{1}\\p{Alpha}+"; p = Pattern.compile(regex); String s = "新浪:www.sina.cn,央视:http://www.cctv.com,西农:www.nwsuaf.edu.cn,无:www.edu.cn,百度:www.baidu.com"; System.out.println("原字符串是:" + s); m = p.matcher(s); while(m.find()) { String str = m.group(); System.out.println(str); } System.out.println("剔除字符串中的网站网址后得到的字符串:"); String result = m.replaceAll(""); System.out.println(result); } }
运行结果
















 219
219











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









