






字符编码
字符串其实也是一种数据类型,但是字符串还有一个烦人的问题是编码。

我们知道计算机智能处理数字,如果要计算机处理文本,就必须先把文本转换为数字。最早的计算机采用8个比特为一个字节,一个字节能表示的最大整数就是255(八位二进制最大数11111111=十进制255),想表示更大的数就需要更多的字节。两个字节可以表示的最大数就是二进制下16个1即1111111111111111等于十进制下65535。
最早计算机只使用在英语范围内,所以最早只有127个字符,也就是英文大小写、数字和一些符号,这个编码表就是ASCII编码。这要处理中文明显不够,至少需要两个字节,所以中国制定了自己的GB2312编码。就这样各国产生了各国的标准,不可避免的会发生冲突,所以早期软件多语言混合的文本会显示乱码。于是发展出了Unicode,它把所有语言统一到一套编码,就解决了乱码的问题。
后来为了解决Unicode编码体型过大,方便传输和存储的目的,发展出了UTF-8,我们现在网页源码上最常见的信息就表明该网页是UTF-8编码,Python编写过程中也要做相应的标注,告诉Python解释器读取源码时按照UTF-8编码读取。
# -*- coding: UTF-8 -*-在计算机内存中,统一使用的是Unicode编码,当需要保存或者传输时,转换为UTF-8编码。
Python字符串
Python3中,字符串以Unicode编码,也就是说Python支持多语言,例如:
>>> print('你好!Hello!こんにちは!Bonjour!')你好!Hello!こんにちは!Bonjour!对于单字符编码,Python提供了一个ord()函数,用来获取字符的整数表示,chr()则把编码转换为对应的字符:
>>> ord('木')26408>>> ord('O')79>>> ord('人')20154>>> chr(75)'K'>>> chr(24352)'张'知道了字符的整数编码,我们可以用十六进制来写,这两种方式完全等效。
>>> '木人张''木人张'encode与decode
Python的字符串str,在内存中以Unicode编码,一个字符会对应若干字节。如果要网络传输或者存储,就要把str变为以字节为单位的bytes。bytes类型:b左前缀单引号或双引号
x = b'ABC'bytes在这里每个字符只占一个字节。encode:unicode编码的str可以用encode()编码为指定编码的bytes
>>> 'Woodmanzhang'.encode('ascii')b'Woodmanzhang'>>> 'Woodmanzhang'.encode('utf-8')b'Woodmanzhang'>>> '木人张'.encode('utf-8')b'xe6x9cxa8xe4xbaxbaxe5xbcxa0'>>> '木人张'.encode('ascii')Traceback (most recent call last):File "", line 1, in '木人张'.encode('ascii')UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-2: ordinal not in range(128)中文超出了ASCII编码范围,就直接报错了。bytes中无法ASCII编码的字节,用x##显示
decode:从网络或磁盘读取的数据是bytes,使用decode()解码为str
>>> b'Woodmanzhang'.decode('ascii')'Woodmanzhang'>>> b'xe6x9cxa8xe4xbaxbaxe5xbcxa0'.decode('utf-8')'木人张'如果bytes中含有无法解码的字节,decode会报错,可以使用errors=’ignore’忽略错误

len()函数
用来统计字符串str包含多少字符,如果括号内换成bytes,统计计算的就是字节数
>>> len('Woodmanzhang')12>>> len('木人张')3>>> len(b'Woodmanzhang')12>>> len('木人张'.encode('utf-8'))9>>> len(b'xe6x9cxa8xe4xbaxbaxe5xbcxa0')9格式化
我们经常收到短信或者提示信息:“亲爱的XX你好,你XX月话费XX元,余额XX元。”这里XXX是变化的变量,所以需要一种格式化字符串的方式在管理这些数据。Python格式化使用%实现
>>> 'Hello,%s' % '木人张''Hello,木人张'>>> '你好,%s,您的账户还有%d元。' %('木人张',1)'你好,木人张,您的账户还有1元。'%就是用来格式化字符串的,%占位符有几个,后面就有几个变量,或者直接赋值,按顺序对应。如果只有一个占位符,可以去掉括号。占位符 替换内容%d 整数%f 浮点数%s 字符串%x 十六进制整数格式化%指定补零和小数位数的使用:
>>> print('%2d-%02d' % (3, 1)) 3-01>>> print('%.2f' % 3.1415926)3.14%s永远起作用,把任意数据类型转换为字符串
>>> '年龄:%s.会员:%s' % (35,True)'年龄:35.会员:True'如果是要使用百分号%呢?用%来转义%,也就是%%表示一个%(百分号)
>>> '增长率:%d%%' % 10'增长率:10%'format()
格式化字符串的另一种方法,用传入的参数依次替换字符串内的占位符{0}、{1}、….
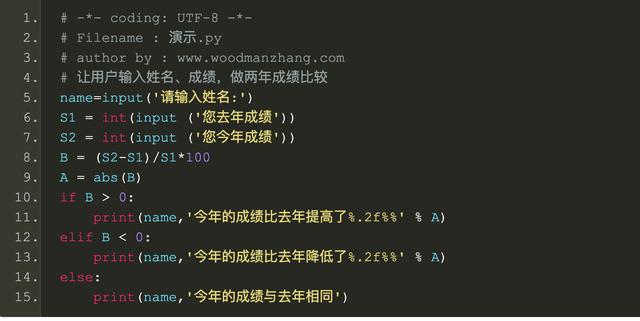
>>> '你好,{0},您的成绩提升了{1:.1f}%'.format('木人张',10.00)'你好,木人张,您的成绩提升了10.0%'演示
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









