






迁移.net framework的项目,有块读取txt中文转码的问题,普通的不能再普通的代码,想都没想直接copy过去,也没测,结果今天就被坑了。Core是3.1版本,这是原来的代码:
string content =System.IO.File.ReadAllText(fileFullPath, Encoding.Default);
System.IO.File.WriteAllText(fileFullPath, content, Encoding.UTF8);
很基础的功能,网上一搜一大堆。但是Core直接运行读取中文还是乱码,看似一个小问题,百度之,渐渐的发现这是一个小坑坑,于是乎,开始刨根问底。
首先发现两个环境下 Encoding.Default 这个东西是不同的。官方API解释:链接
瞅瞅这是人话吗,为什么Core就始终返回utf8呢?看了一眼.net framework下的 Encoding.Default,是这个东东。
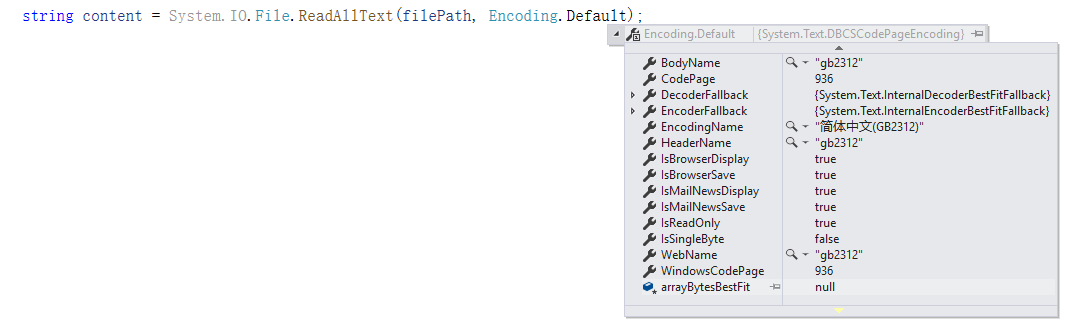
所以换个编码就应该就OK了(当然中文本来就是GB2312),结果现实啪啪打脸,居然报错了(脑补一个笑哭的表情)。
string content1 = System.IO.File.ReadAllText(filePath, Encoding.GetEncoding("GB2312"));
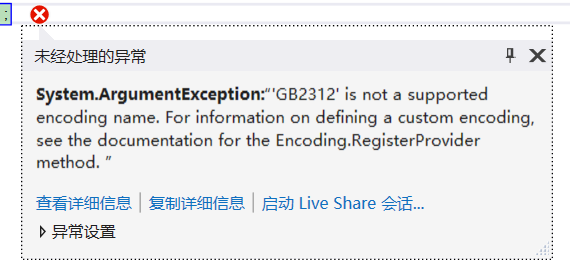
Encoding.RegisterProvider(CodePagesEncodingProvider.Instance);
至此,读取中文正常。
但是,按照标准程序员的思维,这写死肯定不对啊。既然人家不支持了,顺着思路肯定是想办法获取正确的编码然后进行读取。因为txt默认是ANSI编码,所以找了一个.Net Core 读取ansi编码的方法,大家可以参考一下。贴上这位大哥的地址:https://www.cnblogs.com/ives/p/10346498.html。
一番断点测试,发现,其实并没有返回正确的编码格式,只是默认GB2312,那跟写死还是没有区别,于是在茫茫代码中,发现一句:Encoding.GetEncoding(0);
又一番断点测试,发现,在没有注册编码前,Encoding.GetEncoding(0) 等同于 Encoding.Default,但是注册后 Encoding.GetEncoding(0) 等同于 Encoding.GetEncoding("GB2312")。再次仔细阅读API,稍微理解了一下这句话,我理解的意思大概是:这么注册一下再获取默认编码的时候,程序就知道用GB2312了。

总结: 1、.Net Framework 读取txt用 Encoding.Default 默认就是 GB2312。
2、.Net Core必须注册编码方法Encoding.RegisterProvider(CodePagesEncodingProvider.Instance); 并且用Encoding.GetEncoding(0) 读取。
3、官方文档解释的还是很到位的,就是感觉看起来有点难理解,也不知道是翻译的问题,还是小弟水平有限。(再脑补一个笑哭的表情)














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









