






spider爬虫,适合meta传参的爬虫(列表页,详情页都有数据要爬取的时候)
crawlspider爬虫,适合不用meta传参的爬虫
scrapy genspider -t crawl it it.com
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from Sun.items import SunItem
class DongguanSpider(CrawlSpider):
name = 'dongguan'
# 修改允许的域
allowed_domains = ['sun0769.com']
# 修改起始的url
start_urls = ['http://wz.sun0769.com/index.php/question/questionType?type=4']
rules = (
# 构建列表url的提取规则
Rule(LinkExtractor(allow=r'questionType'), follow=True),
# 构建详情页面url提取规则
# 'html/question/201711/352271.shtml'
Rule(LinkExtractor(allow=r'html/question/\d+/\d+.shtml'), callback='parse_item'),
)
def parse_item(self, response):
# print (response.url,'--------')
# 构建item实例
item = SunItem()
# 抽取数据,将数据存放到item中
item['number'] = response.xpath('/html/body/div[6]/div/div[1]/div[1]/strong/text()').extract()[0].split(':')[-1].strip()
item['title'] = response.xpath('/html/body/div[6]/div/div[1]/div[1]/strong/text()').extract()[0].split(':')[-1].split(' ')[0]
item['link'] = response.url
data = ''.join(response.xpath('//div[@class="c1 text14_2"]/text()|//div[@class="contentext"]/text()').extract())
item['content'] = data.replace('\xa0','')
# print(item)
# 返回数据
yield item

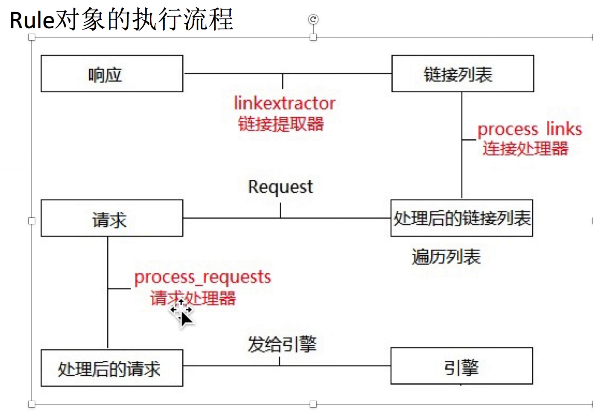
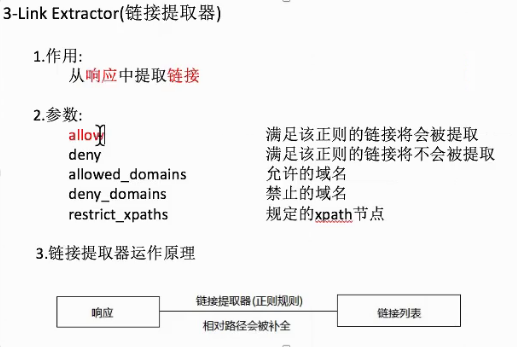
链接提取器的使用
scrapy shell http://hr.tencent.com/position.php
>>> from scrapy.linkextractors import LinkExtractor
>>> le = LinkExtractor(allow=('position_detail.php\?id=\d+&keywords=&tid=0&lid=0'))
或者直接 le = LinkExtractor(allow=('position_detail.php')) 也可以
>>> links=le.extract_links(response)
>>> for link in links:
... print(link)
...
>>> for link in links:
... print(link.url)
...

















 562
562











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









