






先简单讲讲只用HBase来实现分页的思路: HBase利用scan来扫描表,通过startKey,stopKey来确定扫描范围,在需要进行分页时可以结合HBase提供的PagefFilter过滤扫描的行数使scan返回N条数据达到分页的目的(N为每页的记数),此时有以下两种方案达可以达到分页目的: 1. 在得到scan结果后把上一页的最后一条数据作为scan下一页时的startKey,但是此时下一页的数据在传到客户端时就要排除第一条数据了(因为第一条的数据是上一页的) 2.在每次scan时多查询一条数据(即返回N+1)作为下一页的startKey 以上的方案存有个大前提:HBase的RowKey必须是序列增长(类似1,2,3,....)的,否则的话虽然能定位到下一页的startkey,但是当我要查询上一页/上N页时就不能够定位到此时的startkey了。 所以解决这个大前提的方案就是添加一个序列ID到RowKey中来帮助起始键定位到对应偏移量的位置,但是当你的RowKey存在其他字符(如汉字)时就不能简单的将序列ID添加到RowKey了。(所以仅仅通过HBase来实现分页还是比较麻烦的,特别是RowKey比较复杂的时候) 下面是具体的实现方案: 项目场景:按条件查询并实现分页(如按澳门,三亚,2016-01-02查询并分页) 这里我选择使用Phoenix来操作HBase,原因是对于简单条件的查询Phoenix速度快,并且Phoenix提供了生成序列ID的方法,对于熟悉SQL语句的开发者来说可以很好的提高开发效率。 步骤:(HBase中存在TRAVEL表) 1.在Phoenix中为TRAVEL表创建视图TRAVEL
CREATE VIEW TRAVEL (ROWKEY VARCHAR PRIMARY KEY,INFO.SP VARCHAR,INFO.EP VARCHAR,INFO.ST VARCHAR,INFO.ET VARCHAR);
(INFO为HBase表TRAVEL的列族名) 视图TRAVEL中的一段数据如下:
 2.建立sequence(序列)
2.建立sequence(序列)
CREATE SEQUENCE SEQ;
3.在Phoenix中新建表PAGETRAVEL
CREATE TABLE TRAVEL (ROWKEY VARCHAR PRIMARY KEY,INFO.SP VARCHAR,INFO.EP VARCHAR,INFO.ST VARCHAR,INFO.ET VARCHAR,PAGEID BIGINT);
(字段PAGEID就是帮助起始健定位对应偏移量的分页ID) 4.通过Phoenix的UPSERT SELECT将视图TRAVEL中的数据全部插入到PAGETRAVEL表中
UPSERT INTO PAGETRAVEL SELECT ROWKEY,SP,EP,ST,ET,NEXT VALUE FOR SEQ FROM TRAVEL;
PAGETRAVEL表中的部分数据如下:
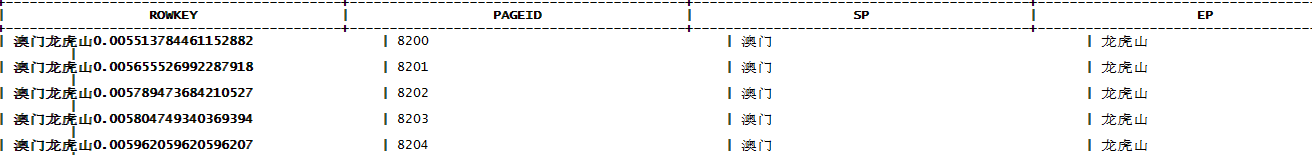 有了PAGEID后就可以轻易的确定每页起始键对应的偏移量。 5.得到每页起始键的偏移量(PAGEID)
有了PAGEID后就可以轻易的确定每页起始键对应的偏移量。 5.得到每页起始键的偏移量(PAGEID)
SELECT PAGEID FROM TRAVEL WHERE ROWKEY LIKE '澳门三亚%' AND ST >= '2016-01-02';
6.分页查询
SELECT * FROM TRVELS WHERE PAGEID > PAGEID*(PAGENUM-1)*N ORDER BY PAGEID LIMIT N WHERE ROWKEY LIKE '澳门三亚%';
(PAGENUM为当前页数)
关键代码实现:
public List findPageRecords(int currentPageNum, int pageSize,String ST,String SP,String EP) {
//得到每页起始键的偏移量,第一个参数为SQL语句,第二个参数为返回值类型的Class对象,第三个参数为占位符值(为可变参数)
int startkey = jdbcTemplate.queryForObject('SELECT * FROM TRAVELS WHERE ST >= ? AND ROWKEY LIKE ? LIMIT 1',Integer.class,ST,SP+EP+'%');
//第一个参数为SQL语句,第二参数的RowMapper将每一行结果映射成一个Java对象,方便将其他封装到JavaBean中,第三个参数为占位符值(为可变参数)
List travels = jdbcTemplate.query('SELECT * FROM TRAVELS where PAGEID >= ? AND ST >= ? AND ROWKEY LIKE ? limit 8',
new RowMapper() {
public Travel mapRow(ResultSet rs, int rowNum)
throws SQLException {
Travel travel = new Travel();
travel.setROWKEY(rs.getString('ROWKEY'));
travel.setURL(rs.getString('URL'));
travel.setSP(rs.getString('SP'));
travel.setEP(rs.getString('EP'));
travel.setST(rs.getString('ST'));
travel.setET(rs.getString('ET'));
travel.setSIGHTS(rs.getString('SIGHTS'));
travel.setALLDATE(rs.getString('ALLDATE'));
travel.setHOTEL(rs.getString('HOTEL'));
travel.setTOTALPRICE(rs.getString('TOTALPRICE'));
travel.setTRAFFIC(rs.getString('TRAFFIC'));
travel.setTRAVELTYPE(rs.getString('TRAVELTYPE'));
travel.setSUPPLIER(rs.getString('SUPPLIER'));
return travel;
}
},startkey+(currentPageNum - 1)*pageSize,ST,SP+EP+'%');
return travels;
}
总结:通过与Spring JDBC的集成,利用Phoneix可以很轻易的实现HBase分页极大地提高开发效率,并且Phoenix还提供了二级索引的功能。















 3440
3440











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









