






本文原创,如需转载,请注明作者和原文链接
1、集群搭建的前期准备 见 搭建分布式hadoop环境的前期准备---需要检查的几个点
2、解压tar.gz包
[root@node01 ~]# cd software/ [root@node01 software]# ll 总用量 179292 -rw-r--r-- 1 root root 183594876 2月 26 2019 hadoop-2.6.5.tar.gz [root@node01 software]# tar xf hadoop-2.6.5.tar.gz -C /opt/sxt/ [root@node01 software]# cd /opt/sxt/ [root@node01 sxt]# ll 总用量 0 drwxr-xr-x 9 root root 149 5月 24 2017 hadoop-2.6.5
3、HADOOP_HOME环境变量的配置
[root@node01 hadoop-2.6.5]# vi + /etc/profile
结果如图
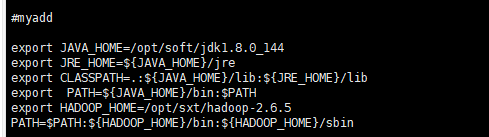
配置完毕之后,要重新的去读取一下这个文件
[root@node01 hadoop-2.6.5]# source /etc/profile
4、java环境变量配置文件的配置
转到目录,注意点:hadoop启动 的时候只会去加载这个目录下的配置文件,如果这个目录下有其他的文件夹的话,没有影响

JAVA_HOME的环境变量的二次设置(原因:因为你启动集群的时候的话,你如果不在这个hadoop的文件下设置某些项的话,他会去找你默认本地的java的配置路径,他会找Local ,但是由于是集群启动,根本没有Local这一说,所以你要在一些配置文件中去配置java的路径,让之启动的时候能够找到,如果你不二次配置的话,可能会出现 java command not found)
配置1: hadoop-env.sh 如果你是只是安装HDFS的话,只改这个配置文件就可以了,但是如果之后会用到mapreduce、yarn等,也需要第二三步的配置
[root@node01 hadoop]# vi hadoop-env.sh

配置2: mapred-env.sh
[root@node01 hadoop]# vi mapred-env.sh
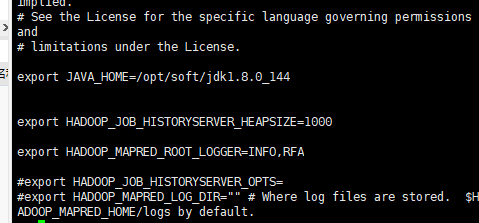
配置3: yarn-env.sh
[root@node01 hadoop]# vi yarn-env.sh
结果

5 hadoop的结点及副本配置文件配置
参考hadoop官网即可
Pseudo-Distributed Operation Hadoop can also be run on a single-node in a pseudo-distributed mode where each Hadoop daemon runs in a separate Java process. Configuration Use the following: etc/hadoop/core-site.xml:
------------------------------------------------------------------------- <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> </configuration> etc/hadoop/hdfs-site.xml: <configuration> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration>
配置1:core.env.xml
[root@node01 hadoop]# vi core-site.xml

配置2:
[root@node01 hadoop]# vi hdfs-site.xml

6、第五步配置的是NameNode的配置,这里需要去配置DataNode和SecondaryNameNode了
配置DataNode:slaves
[root@node01 hadoop]# vi slaves
配置第二主节点:默认是配置在 hdfs-site.xml 中的 ,第二个dfs.namenode.secondary.http-adress中的值:是第二主节点在的ip和以及端口号
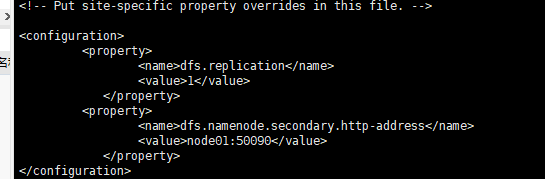
7、更改主结点,从结点的数据的存储位置。因为不更改的话默认是一个临时的文件夹,这样的话,系统可能不会经过你的允许就会删除这个文件!!
[root@node01 hadoop]# vi core-site.xml
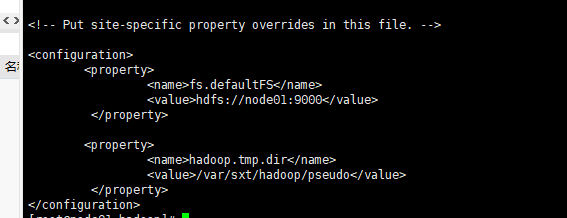
从此所有的配置完成,但是仍需要格式化namenode,生成fsimage文件
8、生成fsimage文件
格式化之前:

格式化命令
[root@node01 hadoop]# hdfs namenode -format #就是为了生成一个fsimage文件
格式化完成

出现
19/09/20 11:23:28 INFO common.Storage: Storage directory /var/sxt/hadoop/pseudo/dfs/name has been successfully formatted.
代表格式化成功
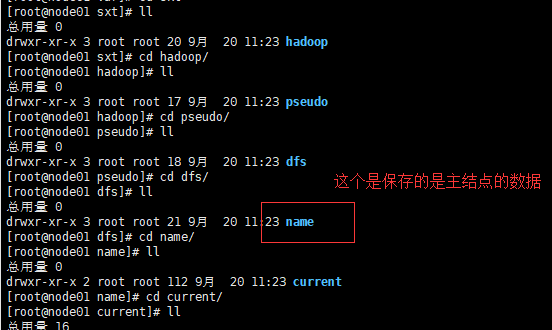
格式化之后,会生成一个目录和一些文件name .内容包括唯一ID、镜像文件等,(特别需要注意的是这个文件所在的位置自己在core-site.xml配置的属性hadoop.tmp.dir的值中设置的),而且在格式化主结点完毕之后。只会生成主结点的数据文件name,,对于从结点和第二主结点的数据文件(data、secondaryNameNode)是当集群启动的时候才会产生的
如下图:

其中包含:fsimage镜像文件,如sfiamge_00000000000
clusterID:集群的唯一标识的ID 这个ID是供集群使用的,集群中的每一个结点都有这样的一个集群ID,而且是一样的,如果不一样的话,就不代表是隶属于一个集群了,特别的需要注意的是:对于集群之前的namenode格式化,只能进行一次,因为进行多次的话,会导致每次都会产生一个新的clusterID,只是主结点的clusterID变了而其他的结点的并没有变,这样的话会导致整个集群启动的时候,一部分启动不起来,只要是集群ID不一样的,就不会启动,这就是多次格式化产生的问题!!!!

注意 :格式化的时候只会产生一个主结点的数据文件夹,name,具体的DataNode和第二主结点的文件夹是在启动集群的时候才会产生的!!!!
到此为止,所有的配置完成,可以启动集群了
启动集群
[root@node01 hadoop-2.6.5]# start-dfs.sh
遇见的问题
hadoop伪分布式集群启动出现错误[root@node01 hadoop-2.6.5]# start-dfs.sh
Starting namenodes on [node01] The authenticity of host 'node01 (::1)' can't be established.
ECDSA key fingerprint is SHA256:hCsbjhUULX1rayvyVwh4EVZzIh49utgmghXRynCvVDE. ECDSA key fing
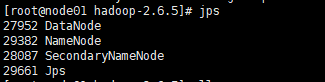
自己不知道是什么问题,jps进程查询也只有DataNode和SecondaryNameNode两个,没有主结点进程,之后从新的启动了一些集群,就有nameNode进程了,
如果有大佬知道的话,还请下方评论,告诉小白我哦,谢谢啦。
下面是第二次启动的时候并没有关闭第一次启动的集群出现的问题:让我们先关闭DataNode和secondaryNamenode两个结点

启动完毕之后,再次转到hadoop.tmp.dir的值指向的那个目录,就会多data和secondaryNameNode两个文件夹了,这分别是针对从结点和第二主节点的文件夹,具体看下图效果

特别需要注意的是:所有的结点的clusterID的值都应该是一样的,因为隶属于同一个集群。因为所有的结点都属于同一个集群,所以才会在集群启动的时候每个结点以不同的进程进行显示
- 具体的从结点中有无数据可以从下面的目录中来看
[root@node01 dfs]# cd data/ #这里的data代表的是从结点 [root@node01 data]# ll 总用量 0 drwxr-xr-x 3 root root 65 9月 20 14:23 current [root@node01 data]# cd current/ [root@node01 current]# ll 总用量 4 drwx------ 4 root root 72 9月 20 14:23 BP-782039128-127.0.0.1-1568949808230 -rw-r--r-- 1 root root 229 9月 20 14:23 VERSION [root@node01 current]# cd B* [root@node01 BP-782039128-127.0.0.1-1568949808230]# ll 总用量 0 drwxr-xr-x 4 root root 64 9月 20 14:25 current -rw-r--r-- 1 root root 0 9月 20 14:23 dncp_block_verification.log.curr drwxr-xr-x 2 root root 6 9月 20 14:23 tmp [root@node01 BP-782039128-127.0.0.1-1568949808230]# cd current/ [root@node01 current]# ll 总用量 8 -rw-r--r-- 1 root root 18 9月 20 14:25 dfsUsed drwxr-xr-x 2 root root 6 9月 20 14:23 finalized drwxr-xr-x 2 root root 6 9月 20 14:23 rbw -rw-r--r-- 1 root root 128 9月 20 14:23 VERSION [root@node01 current]# cd finalized/ [root@node01 finalized]# ll 总用量 0 [root@node01 finalized]# pwd /var/sxt/hadoop/pseudo/dfs/data/current/BP-782039128-127.0.0.1-1568949808230/current/finalized

- 一般的集群还会提供一个可视化的管理界面:浏览器访问我们的集群中的HDFS系统的话,默认的浏览器访问集群的端口是50070,而不是9000,9000是结点之间通信的端口
通过浏览器访问自己的集群:http://结点的ip地址或者别名:50070/ 如:http://192.168.27.102:50070/
结果界面

下面来查看自己的集群中的内容:但是还没向集群中上传文件,如果想要上传文件的话,需要先在nameNode的位置创建一个存放数据文件块的路径
未创建之前,从浏览器中存储的内容为空
创建的过程
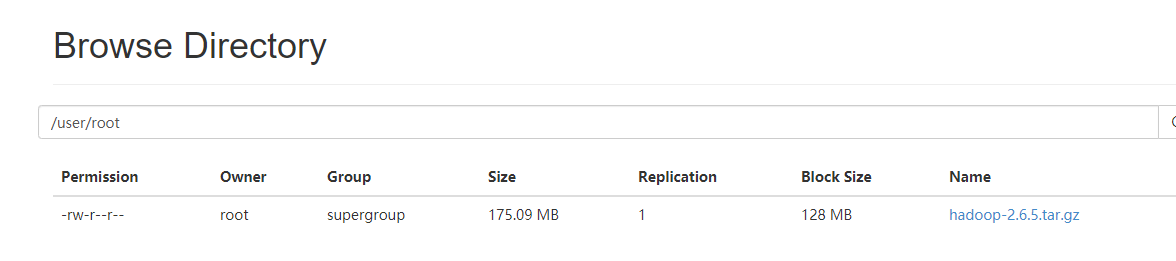
[root@node01 sbin]# hdfs dfs -mkdir -p /user/root
如果不清楚hdfs的命令的话:可以用命令查询
见下面

之后的结果

最后就可以向自己搭建起来的集群中上传数据文件了
上传命令语法

#上传文件
[root@node01 software]# ll
总用量 179292
-rw-r--r-- 1 root root 183594876 2月 26 2019 hadoop-2.6.5.tar.gz
[root@node01 software]# hdfs dfs -put hadoop-2.6.5.tar.gz /user/root
成功
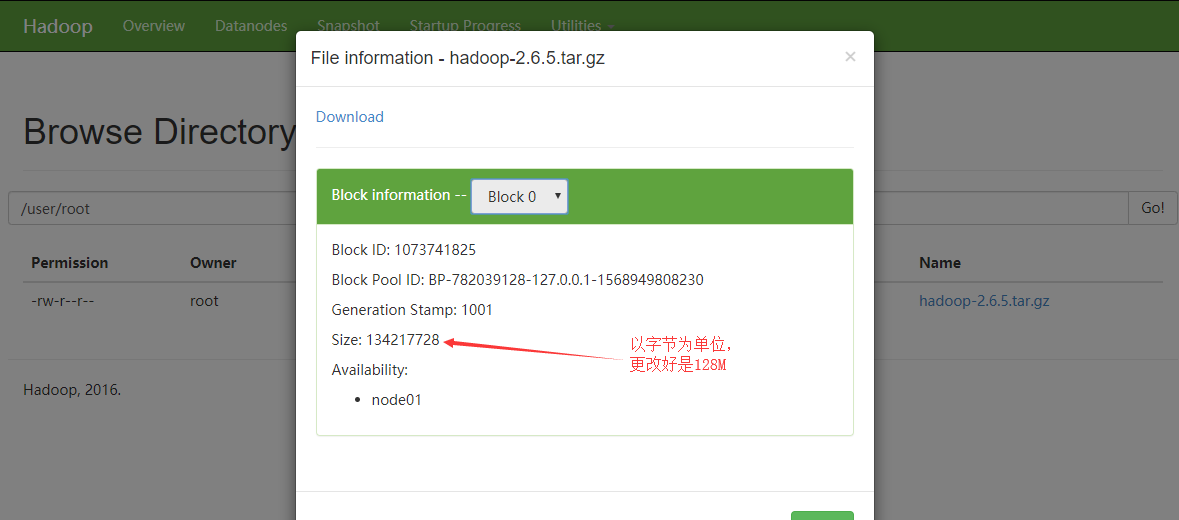
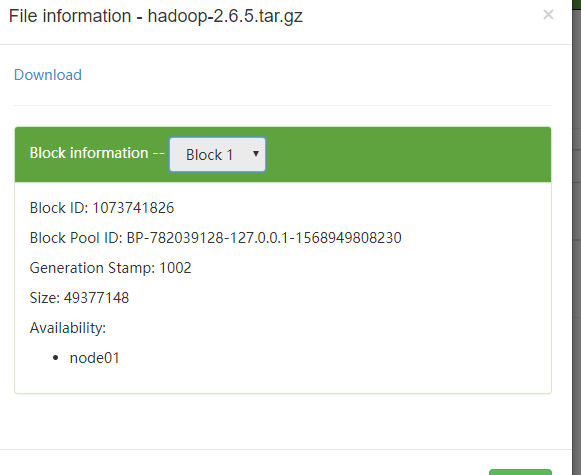
注意点:具体上传的这个文件不是整个的存储的,而是以块的形式存储的,这次上传文件总的大小是175M,所以会分成两块,一个默认的是128M,另一个是175-128M
块0
块1
控制台查看,块的存储形式
drwxr-xr-x 3 root root 17 9月 20 11:23 pseudo [root@node01 hadoop]# cd pseudo/ [root@node01 pseudo]# ll 总用量 0 drwxr-xr-x 5 root root 51 9月 20 14:04 dfs [root@node01 pseudo]# cd dfs/ [root@node01 dfs]# ll 总用量 0 drwx------ 3 root root 40 9月 20 15:26 data drwxr-xr-x 3 root root 40 9月 20 15:26 name drwxr-xr-x 3 root root 40 9月 20 15:27 namesecondary [root@node01 dfs]# cd data/ [root@node01 data]# ll 总用量 4 drwxr-xr-x 3 root root 65 9月 20 14:23 current -rw-r--r-- 1 root root 12 9月 20 15:26 in_use.lock [root@node01 data]# cd current/ [root@node01 current]# ll 总用量 4 drwx------ 4 root root 112 9月 20 16:00 BP-782039128-127.0.0.1-1568949808230 -rw-r--r-- 1 root root 229 9月 20 15:26 VERSION [root@node01 current]# cd B* [root@node01 BP-782039128-127.0.0.1-1568949808230]# ll 总用量 4 drwxr-xr-x 4 root root 64 9月 20 14:25 current -rw-r--r-- 1 root root 0 9月 20 16:00 dncp_block_verification.log.curr -rw-r--r-- 1 root root 164 9月 20 16:00 dncp_block_verification.log.prev drwxr-xr-x 2 root root 6 9月 20 15:26 tmp [root@node01 BP-782039128-127.0.0.1-1568949808230]# cd current/ [root@node01 current]# ll 总用量 8 -rw-r--r-- 1 root root 18 9月 20 14:25 dfsUsed drwxr-xr-x 3 root root 21 9月 20 15:57 finalized drwxr-xr-x 2 root root 6 9月 20 15:57 rbw -rw-r--r-- 1 root root 128 9月 20 15:26 VERSION [root@node01 current]# cd finalized/ [root@node01 finalized]# ll 总用量 0 drwxr-xr-x 3 root root 21 9月 20 15:57 subdir0 [root@node01 finalized]# cd subdir0/ [root@node01 subdir0]# ll 总用量 0 drwxr-xr-x 2 root root 114 9月 20 15:57 subdir0 [root@node01 subdir0]# cd subdir0/ [root@node01 subdir0]# ll 总用量 180700 -rw-r--r-- 1 root root 134217728 9月 20 15:57 blk_1073741825 -rw-r--r-- 1 root root 1048583 9月 20 15:57 blk_1073741825_1001.meta -rw-r--r-- 1 root root 49377148 9月 20 15:57 blk_1073741826 -rw-r--r-- 1 root root 385767 9月 20 15:57 blk_1073741826_1002.meta [root@node01 subdir0]# pwd /var/sxt/hadoop/pseudo/dfs/data/current/BP-782039128-127.0.0.1-1568949808230/current/finalized/subdir0/subdir0 [root@node01 subdir0]# pwd /var/sxt/hadoop/pseudo/dfs/data/current/BP-782039128-127.0.0.1-1568949808230/current/finalized/subdir0/subdir0
其中的 blk_1073741825 块就是我们的block0 blk_1073741826 是block1, blk_1073741825_1001.meta和 blk_1073741826_1002.meta 是两个块的元数据信息,用于验证块的完整性用的
至此,整个伪分布式集群的搭建完成!!!














 1176
1176











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









