






最近 有网友看我的“整合Kafka到Spark Streaming——代码示例和挑战”文章,
讲 kafka对象 放到 pool 并通过broadcast广播出去:
然后 在开发测试阶段 报错如下:


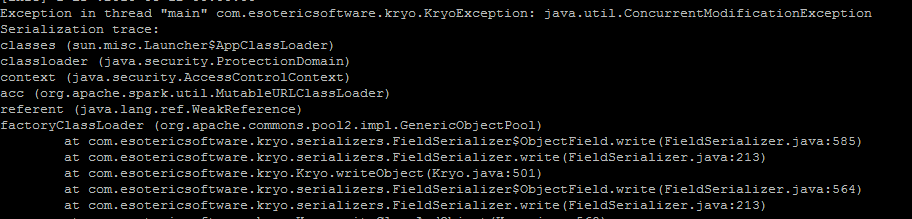
然后就找我,说“代码都跟你的差不多呀,为什么就报这个错呢?”
其实 对于广播操作,spark 肯定要序列号的,还有尽量不要把大对象广播出去,
后来 把代码要过来看了下,发现 createKafkaProducerPool这个方法 ,单独创建了一个类,同时这个类 extends Serializable ,我当时的感觉就是,如果createKafkaProducerPool方法 ,写在main方法 or Driver端 应该就肯定不会有这个问题,我也建议这样搞的,还有 我怀疑 集群是启用了Kryo序列号方式,而createKafkaProducerPool方法所在类竟然 extends Serializable ,不解
important:
The closures (anon function going inside RDD.map(…)) are serialized by Spark before distributing them. Hadoop does not have this problem because it binary-serializes the whole .jar and copies it over the network. Spark uses JavaSerialization by default, but it is very slow compared to, say, Kryo. So we use Kryo to do that by using a wrapper (Spark doesn’t support kryo-serde for closures, not yet).
And uptill now the org.dbpedia.extraction.spark.serializeKryoSerializationWrapper class has been working perfectly. Some freak extractors seem to fail though.
根据这个错误检索的文章
- https://github.com/dbpedia/distributed-extraction-framework/issues/9
- http://stackoverflow.com/questions/27277015/sparkcontext-broadcast-jedispool-not-work
- http://apache-spark-user-list.1001560.n3.nabble.com/why-does-quot-com-esotericsoftware-kryo-KryoException-java-u-til-ConcurrentModificationException-quo-tc23067.html
如果大家有遇到这样问题或者什么好想法,请回复,THX ~
版权声明:本文为博主原创文章,未经博主允许不得转载。















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









