






solr管理界面解释
当 Solr 在 Tomcat 服务器上部署成功后,我们可以登录 Solr 网页版的管理界面进行基本的操作。
一、首先来了解一下 Solr 页面各个功能模块的基本功能是什么?这里主要包括 Dashboard(仪表盘)、Logging(日志)、 Core Admin(索引库管理)、 Java Properties(Java 属性)、 Thread Dump(线程管道)、 Core Selector(Core 选择器)几部分组成,接下来将一一介绍。
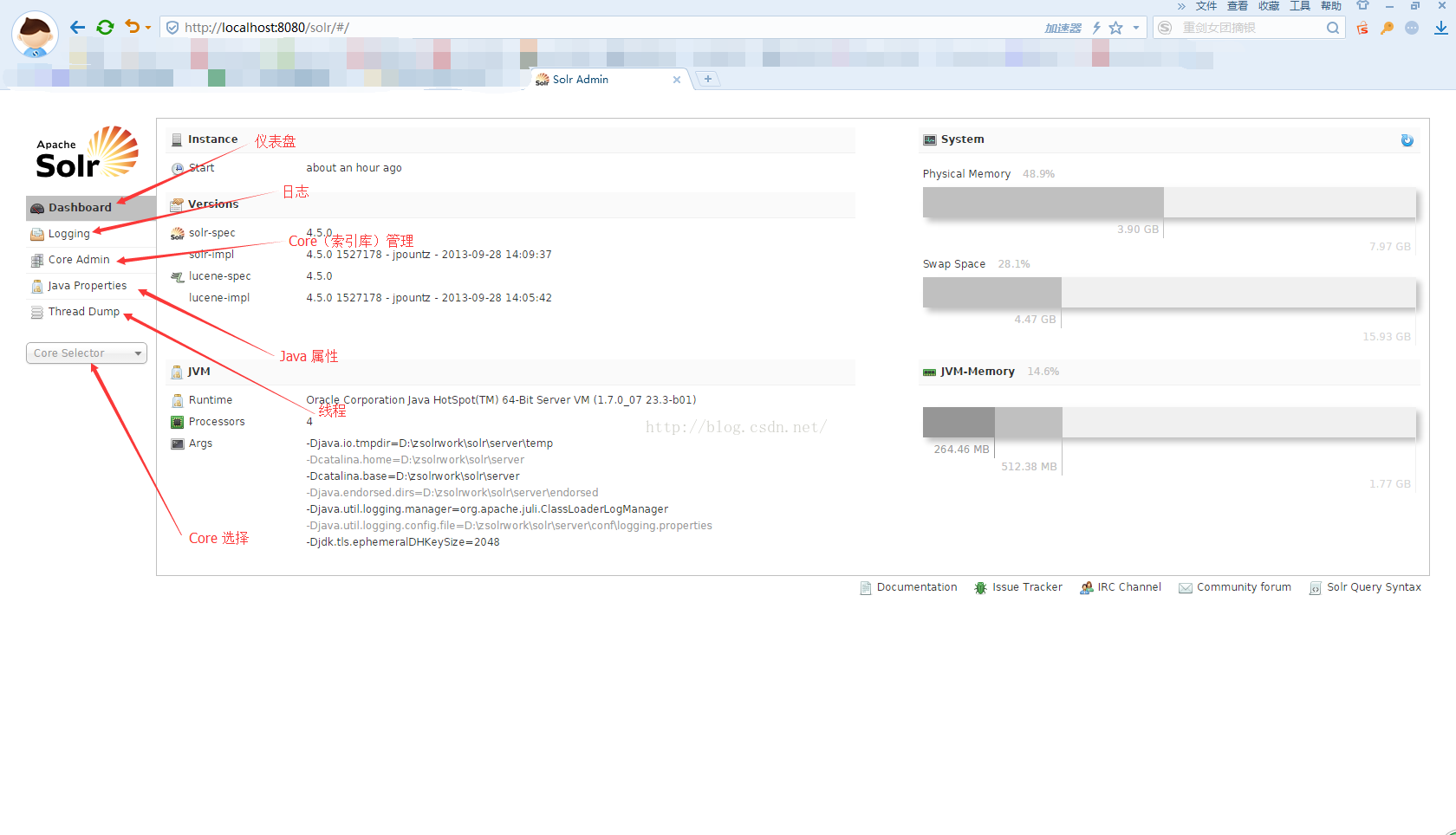
二、Dashboard(仪表盘):包含 solr 搭建路径、版本信息,还有系统内存、jvm 内存和 jvm 参数等信息。

三、日志:用来查看警告或异常的信息,黄色代表警告,红色代表异常

在这里我们可以看到 【Level】选项

在 【Level】 中可以看到 ALL、TRACE、DEBUG、INFO、WARN、ERROR、FATAL、OFF、UNSET 几个可选项。Level 是用来控制相关类日志的显示信息的内容,其中:
ALL:显示全部信息
INFO:除了正常信息,其余信息全部显示
WARN:显示警告信息
ERROR:显示异常信息
UNSET:移除之前设置的信息
其他信息不再赘述(但是本人设置了也没有看到什么效果,[汗].......)

四、索引库管理:Core 管理,索引库优化等。主要包括 Add Core(添加 Core)、Unload(卸载 Core)、Rename(重命名 Core)、Optimize(优化索引库)几个功能
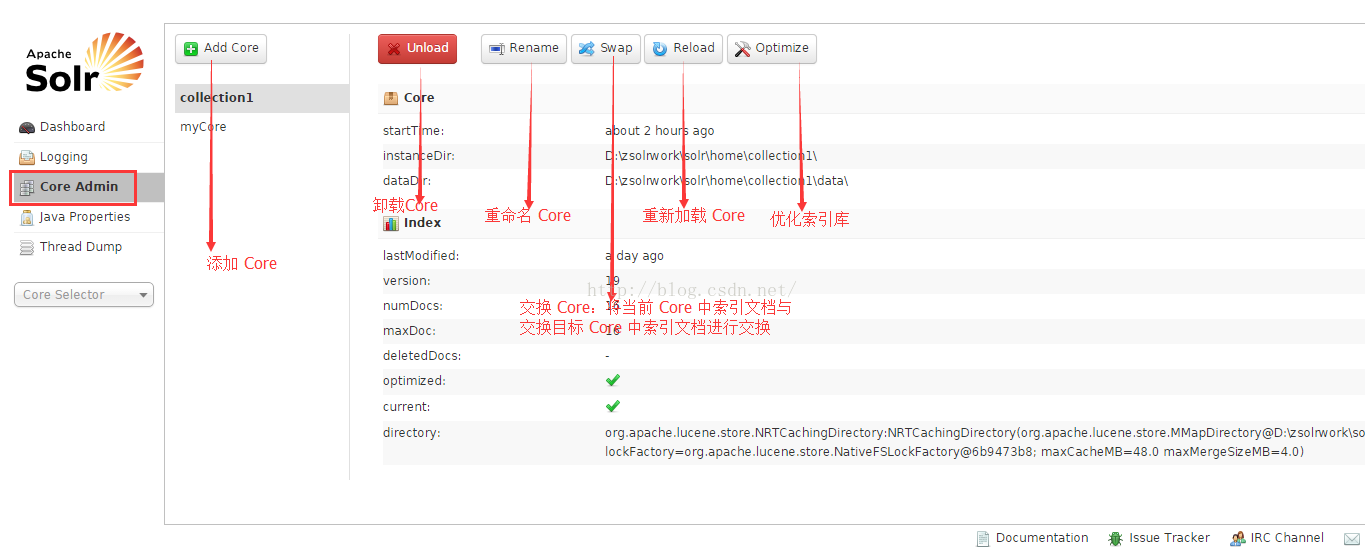
其中:
instanceDir:代表当前 Core 的根目录
dataDir:代表当前 Core 索引文件的存放目录
numDocs:代表当前 Core 索引文档数量。它可能大于 xml 文件个数,因为一个 xml 文件可能存在多个 <doc> 标签。
maxDoc:代表当前 Core 最大索引文档数量。它可能因为重复提交时 maxDoc 就会变大。
(关于 numDocs 和 maxDoc 具体意义我也不是很清楚......)
四、Select Core(选择 Core):选择相应的 Core 进行操作。
1、Overview(概览):选择 Core 的基本信息。

2、Analysis 分词器检验:用来校验所引用分词器的效果。其中 Field Value(Index) 代表需要分词的文本,Field Value(Query) 代表分词标准
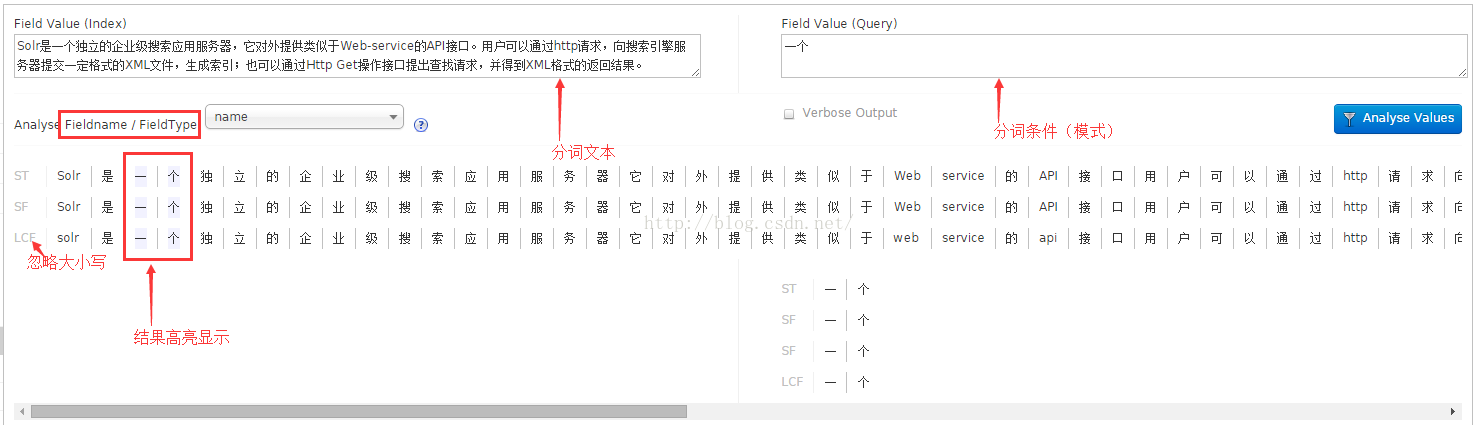
其中:
SF:StopFielter,代表停止词
LCF:LowerCaseFielter,代表忽略大小写
ST:(不知道)
五、Config 就是 solrconfig.xml 文件
六、Dataimport:是从数据库中导入索引文件
七、Document(从文件中导入数据):通过该界面,我们可以选择相应的文件向服务器中导入索引文件。

1、DocumentType:导入文件的形式:
File Upload:从文件中导入,即上传文件
JSON:在 Document(s)中写入特定格式的 JSON 文件
XML:在 Document(s)中写入特定格式的 XML 文件
2、Document(s):写入特定格式的 JSON 或 XML 文件
3、CommitWithin:提交的最大数量
4、Overwrite:是否覆盖(如果两个索引文件的 ID 相同,是否覆盖旧的索引文件)
5、Boot(权重):如果想对不同类型的文章,或者字段设置不同的权重,或者对不同的搜索词语设置权重。但是这样会消耗内存。
1)、添加 JSON 格式文件

2)添加 XML 文件

3)、添加物理文件

八、Query(查询、重要):查询索引文档
1、q:查询参数,格式 FieldName:FieldValue,查询忽略大小写,单词匹配。例如:name:solr(查找 name 中包含 solr 的全部数据)。
2、fq:过滤查询参数,在 q 的查询结果上进一步筛选结果。例如:id:1212(在 name 中包含 solr 的结果上查找 id 为 1212 的数据)。
3、sort:排序,格式:fieldName desc|asc [,fieldName desc|asc ]。例如:name desc 按 name 属性降序排列
4、start,rows:返回结果从第几行显示,一共显示多少行。分页中用到
5、fl:字段过滤,返回结果中显示的 Field 。例如: id,name :返回结果中只包含 id 和 name 字段值,其他字段不显示
6、Raw Query Parameters:组合查询条件,相当于多个 q
7、wt : 输出结果格式。
8、indent:返回结果是否缩进。通常调试 XML 结果用

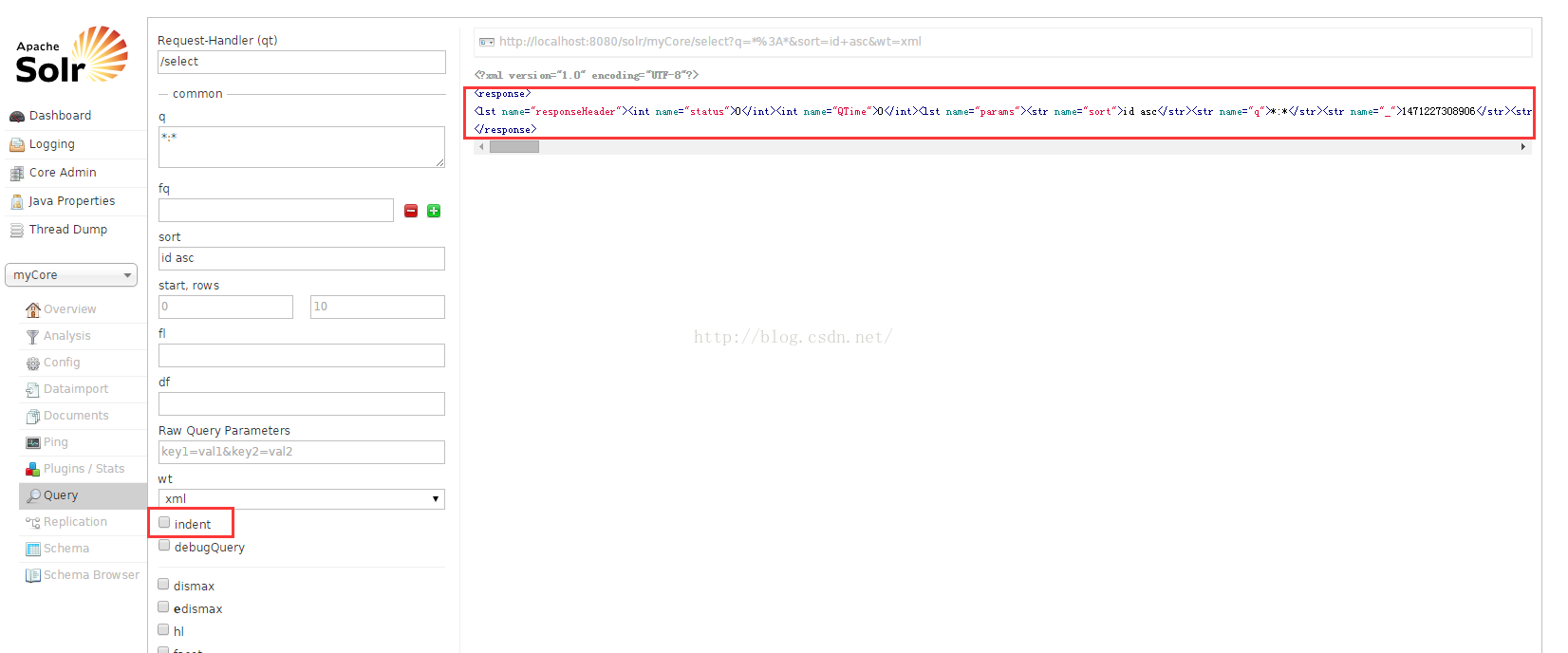
9、debugQuery:是否显示 Debug 信息。
10、dismax:它是基于 Lucene 的 DisjunctionMaxQuery 的扩展,用来取得文档最大打分(设置权重)
11、edismax:dismax 的加强版
12、hl:高亮显示
13、facet:Solr高级查询facet
14、spatial:空间查询
15、spellcheck:拼写检查
solr schema使用
- <?xml version="1.0" encoding="UTF-8" ?>
- 略...
- <!--
- 这是Solr的schema文件,应该命名为schema.xml,并且在solr home的conf目录下
- (如,默认在./solr/conf/schema.xml).
- 有关如何根据需要定制化该文件,请参照:
- http://wiki.apache.org/solr/SchemaXml 性能须知: 这里包含了很多实际应用不需要的可选项。 为改善性能,你可以:
- - 尽量将所有仅用于搜索,而不用于实际返回的字段设置stored="false";
- - 尽量将所有仅用于返回,而不用于搜索的字段设置indexed="false";
- - 去掉所有不需要的copyField 语句;
- - 为了达到最佳的索引大小和搜索性能,对所有的文本字段设置indexed="false",
- 使用copyField将他们拷贝到“整合字段”name="text"的字段中,使用整合字段进行搜索;
- - 使用server模式来运行JVM,同时将log级别调高, 避免输出所有请求的日志。
- -->
- <schema name="example" version="1.5">
- 略...
- <fields>
- <!-- fields各个属性说明:
- name: 必须属性 - 字段名
- type: 必须属性 - <types>中定义的字段类型
- indexed: 如果字段需要被索引(用于搜索或排序),属性值设置为true
- stored: 如果字段内容需要被返回,值设置为true
- docValues: 如果这个字段应该有文档值(doc values),设置为true。文档值在门
- 面搜索,分组,排序和函数查询中会非常有用。虽然不是必须的,而且会导致生成
- 索引变大变慢,但这样设置会使索引加载更快,更加NRT友好,更高的内存使用效率。
- 然而也有一些使用限制:目前仅支持StrField, UUIDField和所有 Trie*Fields,
- 并且依赖字段类型, 可能要求字段为单值(single-valued)的,必须的或者有默认值。
- multiValued: 如果这个字段在每个文档中可能包含多个值,设置为true
- termVectors: [false] 设置为true后,会保存所给字段的相关向量(vector)
- 当使用MoreLikeThis时, 用于相似度判断的字段需要设置为stored来达到最佳性能.
- termPositions: 保存和向量相关的位置信息,会增加存储开销
- termOffsets: 保存 offset 和向量相关的信息,会增加存储开销
- required: 字段必须有值,否则会抛异常
- default: 在增加文档时,可以根据需要为字段设置一个默认值,防止为空
- -->
- <!-- 字段名由字母数字下划线组成,且不能以数字开头。两端为下划线的字段为保留字段,
- 如(_version_)。
- -->
- <field name="id" type="string" indexed="true" stored="true"
- required="true" multiValued="false" />
- <field name="title" type="text_general" indexed="true"
- stored="true" multiValued="true"/>
- <field name="description" type="text_general" indexed="true" stored="true"/>
- <field name="author" type="text_general" indexed="true" stored="true"/>
- <field name="keywords" type="text_general" indexed="true" stored="true"/>
- <field name="category" type="text_general" indexed="true" stored="true"/>
- <field name="url" type="text_general" indexed="true" stored="true"/>
- <field name="last_modified" type="date" indexed="true" stored="true"/>
- <!-- 注意: 为了节省空间,这个字段默认不被索引, 因使用copyField被拷贝到了名为text的字段中
- 。用于内容返回和高亮。搜索时使用text字段
- -->
- <field name="content" type="text_general" indexed="false"
- stored="true" multiValued="true"/>
- <!-- 整合字段(catchall field), 包含其他可搜索的字段 (通过copyField实现) -->
- <field name="text" type="text_general" indexed="true"
- stored="false" multiValued="true"/>
- <!-- 保留字段,不能删除,否则报错 -->
- <field name="_version_" type="long" indexed="true" stored="true"/>
- </fields>
- <!-- 文档的唯一标识,可理解为主键,除非标识为required="false", 否则值不能为空-->
- <uniqueKey>id</uniqueKey>
- <!-- 拷贝需要索引的字段到整合字段中 -->
- <copyField source="title" dest="text"/>
- <copyField source="author" dest="text"/>
- <copyField source="description" dest="text"/>
- <copyField source="keywords" dest="text"/>
- <copyField source="content" dest="text"/>
- <copyField source="url" dest="text"/>
- <types>
- <!-- 字段类型定义 -->
- <fieldType name="string" class="solr.StrField" sortMissingLast="true" />
- <fieldType name="boolean" class="solr.BoolField" sortMissingLast="true"/>
- <fieldType name="int" class="solr.TrieIntField" precisionStep="0"
- positionIncrementGap="0"/>
- <fieldType name="float" class="solr.TrieFloatField" precisionStep="0"
- positionIncrementGap="0"/>
- <fieldType name="long" class="solr.TrieLongField" precisionStep="0"
- positionIncrementGap="0"/>
- <fieldType name="double" class="solr.TrieDoubleField" precisionStep="0"
- positionIncrementGap="0"/>
- <fieldType name="date" class="solr.TrieDateField" precisionStep="0"
- positionIncrementGap="0"/>
- 略...
- <!-- Thai,泰语类型字段 -->
- <fieldType name="text_th" class="solr.TextField" positionIncrementGap="100">
- <analyzer>
- <tokenizer class="solr.StandardTokenizerFactory"/>
- <filter class="solr.LowerCaseFilterFactory"/>
- <filter class="solr.ThaiWordFilterFactory"/>
- <filter class="solr.StopFilterFactory" ignoreCase="true"
- words="lang/stopwords_th.txt" />
- </analyzer>
- </fieldType>
- <!-- Turkish,土耳其语类型字段 -->
- <fieldType name="text_tr" class="solr.TextField" positionIncrementGap="100">
- <analyzer>
- <tokenizer class="solr.StandardTokenizerFactory"/>
- <filter class="solr.TurkishLowerCaseFilterFactory"/>
- <filter class="solr.StopFilterFactory" ignoreCase="false"
- words="lang/stopwords_tr.txt" />
- <filter class="solr.SnowballPorterFilterFactory" language="Turkish"/>
- </analyzer>
- </fieldType>
- <!-- Chinese,需要我们自己配置,整合mmseg4j就配置在这里 -->
- </types>
- <!-- 文档相似度判断依赖于文档相似度得分。 一个自定义的 Similarity 或 SimilarityFactory
- 可以在这里指定, 但是默认的设置已经适合大多数应用。可以参考:
- http://wiki.apache.org/solr/SchemaXml#Similarity
- -->
- <!--
- <similarity class="com.example.solr.CustomSimilarityFactory">
- <str name="paramkey">param value</str>
- </similarity>
- -->
- </schema>
##################################使用solr遇到一个问题 start############################
solr 在使用查询的时候,【q=city:new york】 的时候会命中包含new york的所有数据文档并返回。
但是使用中文【q=city:成都】 的时候会命中包含成和都的合集,实际上我们需要的是精确查找,查找资料发现,如果想只查找包含【成都】
这个词语的文档,我们需要这样做【q=city:"成都"】必须要添加上引号
##################################使用solr遇到一个问题 end############################
比较重要的几个配置
分词:
- <!-- IK分词 start-->
- <fieldType name="text_ik" class="solr.TextField">
- <analyzer type="index">
- <!--
- IKTokenizerFactory:继承 TokenizerFactory
- useSmart:是否启用 智能分词
- -->
- <tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" />
- <!--
- StopFilterFactory:停止分词,会根据stopwords.txt中配置的文件停止分词
- -->
- <filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
- </analyzer>
- <analyzer type="query">
- <tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" />
- <filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
- </analyzer>
- </fieldType>
- <!-- IK分词 end-->
同义词配置:
- <fieldType name="text_general" class="solr.TextField" positionIncrementGap="100">
- <analyzer type="index">
- <tokenizer class="solr.StandardTokenizerFactory"/>
- <filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
- <!-- in this example, we will only use synonyms at query time
- <filter class="solr.SynonymFilterFactory" synonyms="index_synonyms.txt" ignoreCase="true" expand="false"/>
- -->
- <filter class="solr.LowerCaseFilterFactory"/>
- </analyzer>
- <analyzer type="query">
- <tokenizer class="solr.StandardTokenizerFactory"/>
- <filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
- <filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
- <filter class="solr.LowerCaseFilterFactory"/>
- </analyzer>
- </fieldType>
评分权重配置(支持自定义):
- <similarity class="com.example.solr.CustomSimilarityFactory" />
配置默认查询字段
以query查询为例 默认查询的是field name="text"的字段,其他select或者自己定义的查询组件也是一样的道理
- <requestHandler name="/query" class="solr.SearchHandler">
- <lst name="defaults">
- <str name="echoParams">explicit</str>
- <str name="wt">json</str>
- <str name="indent">true</str>
- <!-- 默认查询字段 -->
- <str name="df">text</str>
- </lst>
- </requestHandler>
###########################修改schema.xml###################################
将solr发布到tomcat中,例如需要修改schema.xml,添加一个field,这个时候其实是不支持热发布的,需要重启tomcat
CopyField(本段内容直接从solr中文网copy而来):
|
1
|
<
copyField
source
=
"cat"
dest
=
"text"
maxChars
=
"30000"
/>
|
上例中,如果text字段有数据的话,cat字段的内容将被添加到text字段中。maxChars 参数,一个int类型参数,用于限制复制的字符数。
|
1
|
<
copyField
source
=
"*_t"
dest
=
"text"
maxChars
=
"25000"
/>
|
- <schema name="eshequn.post.db_post.0" version="1.1"
- xmlns:xi="http://www.w3.org/2001/XInclude">
- <fields>
- <!-- for title -->
- <field name="t" type="text" indexed="true" stored="false" />
- <!-- for abstract -->
- <field name="a" type="text" indexed="true" stored="false" />
- <!-- for title and abstract -->
- <field name="ta" type="text" indexed="true" stored="false" multiValued="true"/>
- </fields>
- <copyField source="t" dest="ta" />
- <copyField source="a" dest="ta" />
- </schema>
|
1
|
<
dynamicField
name
=
"*_i"
type
=
"sint"
indexed
=
"true"
stored
=
"true"
/>
|
建议在 schema.xml 定义一些基本的动态字段,以备扩展之用。















 134
134

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









