






谈清楚区别,说明白道理,从案例开始:
1 数据准备
用hdfs存放数据,且结合的hue上传准备的数据,我的hue截图:
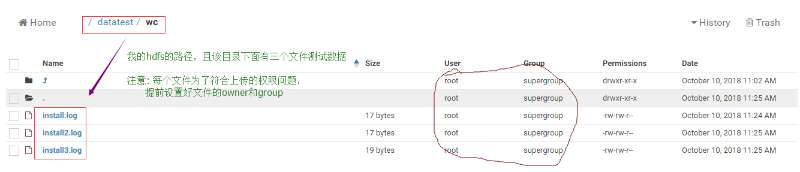

每个文件下的数据:
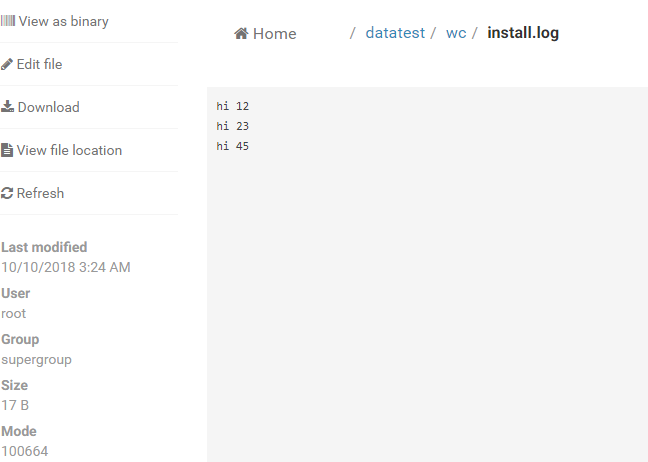
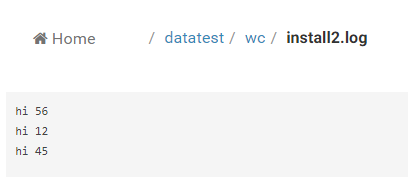
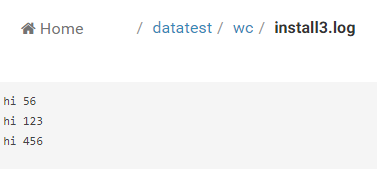
以上是3个文件的数据,每一行用英文下的空格隔开;
2 测试 sc.textFile()和sc.wholeTextFiles()的效果
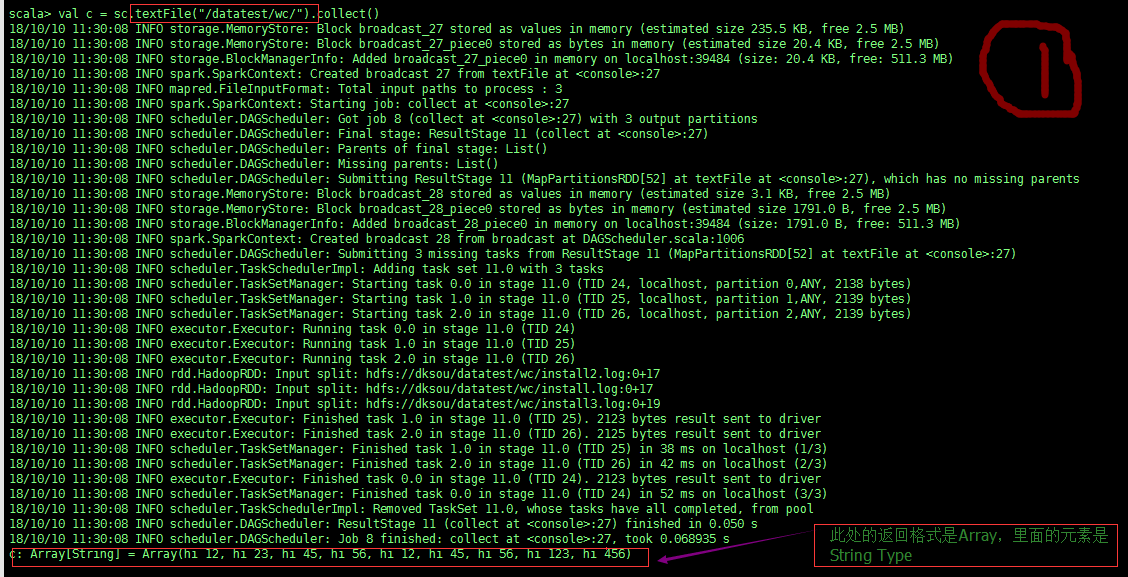
testFIle() 如图:
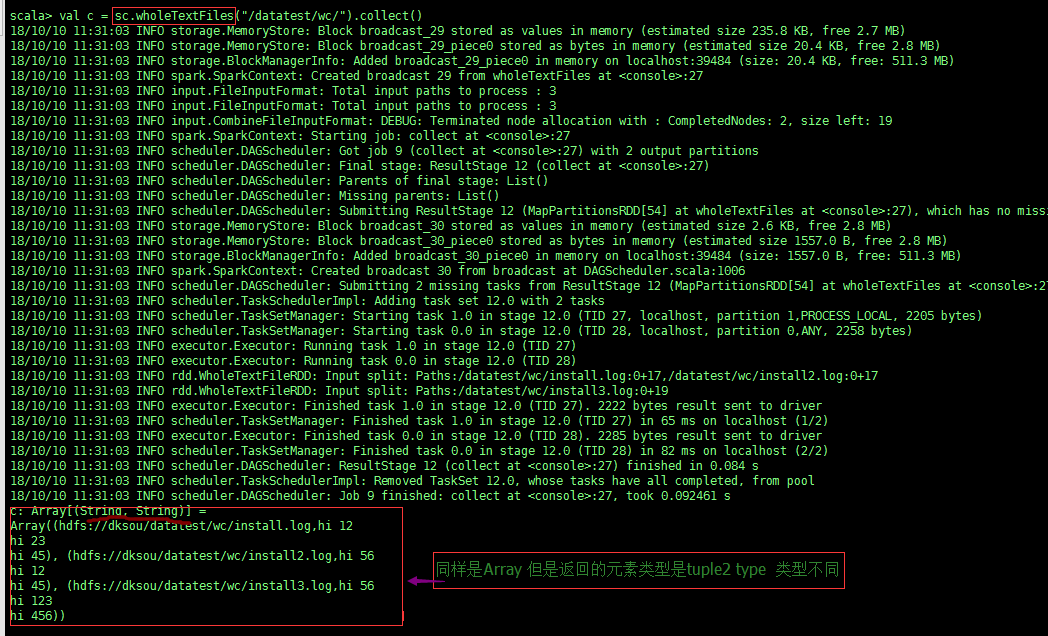
wholetextFiles() 如下图:
注意 一定要仔细观察红色方框圈起来的差异,经过以上两次截图中实验的对比,我们得出重要的结论:
sc.textFiles(path) 能将path 里的所有文件内容读出,以文件中的每一行作为一条记录的方式,
文件的每一行 相当于 List中以 “,”号 隔开的一个元素,因此可以在每个partition中用for i in data的形式遍历处理Array里的数据;
而使用 sc.wholeTextFiles()时:
返回的是[(K1, V1), (K2, V2)...]的形式,其中K是文件路径,V是文件内容,这里我们要注意的重点是:
官方一句话:''Each file is read as a single record'' 这句话,每个文件作为一个记录!这说明这里的 V 将不再是 list 的方式为你将文件每行拆成一个 list的元素,
而是将整个文本的内容以字符串的形式读进来,也就是说val = '...line1...\n...line2...\n'
这时需要你自己去拆分每行!而如果你还是用for i in val的形式来便利 val那么i得到的将是每个字符.
3 两种读取文件下与partition的数量关系
理论后总结,先上2张实用数据测试截图:


从上面的操作来看,总结如下:
用textFile时,它的partition的数量是与文件夹下的文件数量(实例中用3个xxx.log文件)相关,一个文件就是一个partition(既然3个文件就是:partition=3)。
wholeTextFiles的partition数量是根据用户指定或者文件大小来(文件内的数据量少 有hdfs源码默认确定的)确定,与hdfs目录下的文件数量无关! 所以说:wholeTextFile通常用于读取许多小文件的需求。
!!如有更好的意见,欢迎留言交换!!














 1012
1012











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









