






主要参考:
- Spark官方文档:http://spark.apache.org/docs/latest/programming-guide.html
- 炼数成金PPT:02Spark编程模型和解析
本文基本按照Spark官方文档顺序,结合PPT中的详细描述,以及个人理解组成,并且本文基于Java语言接口进行分析.如有错误之处,恳请大家指出.本人也是Spark新手上路,理解可能有偏差,望广大同仁理解.
Spark应用程序基本概念
| 基本元素 | 解释 |
|---|---|
| Application | 基于Spark的用户程序,包含了一个driver program和集群中多个executor |
| Driver Program | 运行Application的main()函数,并且创建SparkContext,通常用SparkContext代表Driver Program |
| Executor | 某Application运行在worker node上的一个进程,该进程负责运行Task,并且负责将数据存在内存或磁盘上.每个Application都有各自独立的executor(s) |
| Cluster Manager | 在集群上获取资源的外部服务(如:Standalone,Mesos,Yarn等) |
| Worker Node | 集群上任何可以运行Application代码的节点 |
| Task | 被送到某个executor上的工作单元 |
| Job | 包含多个task组成的并行计算,往往由Spark Action催生 |
| Stage | 每个Job会拆分成很多组task,每组任务成为stage,也可称为TaskSet |
| RDD | Spark的基本计算单元 |
基本组成如下图
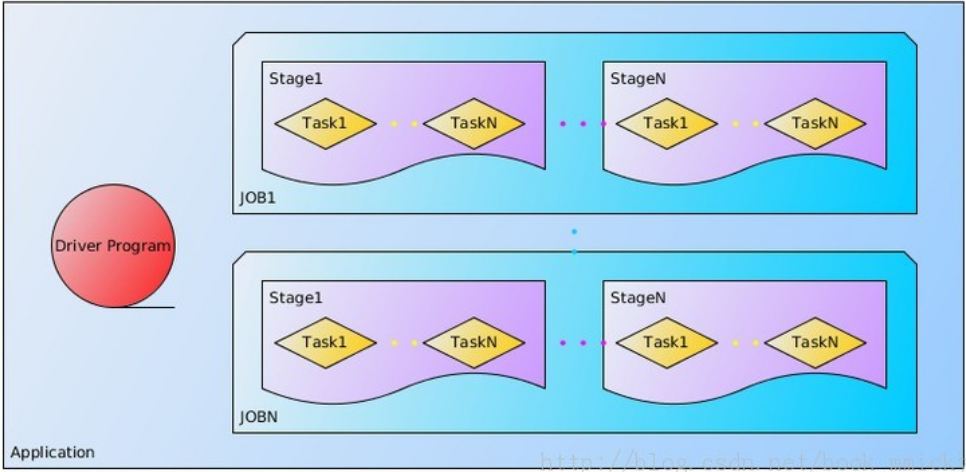
概述
总的来说,Spark applicaiton(应用程序)由一个driver program和若干在集群节点上运行的executors组成.RDD是Spark编程的核心,程序主要过程是读取数据生成RDD,各种RDD之间的转换,将RDD转换成所需或保存或显示等等.关于RDD可以参考论文Resilient Distributed Datasets: A Fault-tolerant Abstraction for In-Memory Cluster Computing
Spark中还有一个重要的概念就是shared variables,可以在并行的操作中使用到.当Spark在一系列不同的node上并行运行tasks时,会将在每个task中会被使用到的一系列变量复制成共享变量.共享变量一般在不同的tasks之间,以及tasks与driver program之间使用.共享变量主要有两种,一种是broadcast variables,另一种是accumulators.下文中将有进一步的介绍
一,初始化Spark
初始化Spark即构建一个JavaSparkContext对象,差不多也就是上面提到的driver program.
SparkConf conf = new SparkConf().setAppName(appName).setMaster(master);
JavaSparkContext sc = new JavaSparkContext(conf);使用appName参数设置application的名字,master参数一般是Spark,Mesos或者YARN的节点URL,或者用”local”代表本地模式运行.
二,Resilient Distributed Datasets(RDDs, 弹性分布式数据集)
有两种方式来生成一个RDD
1,使用本地集合类(Collection)并行化生成
在driver program中,使用JavaSparkContext对象的parallelize方法将Colleciton变成RDD
List<Integer> data = Arrays.asList(1, 2, 3, 4, 5);
JavaRDD<Integer> distData = sc.parallelize(data);关于parallelize函数,还有一种调用方式
sc.parallelize(data, 10)可以指定 将数据集划分的分片的数量,Spark对每个分片都会运行一个task进行处理.通常来说,Spark会根据用户集群的性能自动选择分片数.
2,使用外部存储系统(HDFS,HBASE或者其他Hadoop InputFormat)生成
使用SparkContext的textFile方法,Spark能够接收文件的URI参数(可以为本地文件,也可以为hdfs://,s3n://或其他URI)
JavaRDD<String> distFile = sc.textFile("data.txt");当如上,使用本地文件时,需要确保”data.txt”文件在其他worker node上同样路径下存在.可以将该文件复制到其他节点上,也可以使用网络的方式对文件进行分享.
使用textFile()方法可以将本地或HDFS文件转换成RDD,
支持整个文件目录读取,如
textFile("/my/directory")支持压缩文件读取,如
textFile("/my/directory/*.gz")支持通配符文件读取,如
textFile("/my/directory/*.txt")除了text文件之外,Spark还可以读取其他形式的数据
wholeTextFiles()方法可以读取一个目录下包含的若干小text文件,每个文件对应返回一个(文件名, 内容)对.
sequenceFilesK, V方法可以将SequenceFiles转换成RDD.K和V分别代表文件中key和values的类型.K和V必须是Hadoop中Writable接口的子类,如IntWritable和Text等
hadoopRDD()方法可以将其他Hadoop的InputFormats转化成RDD.
三,RDD操作
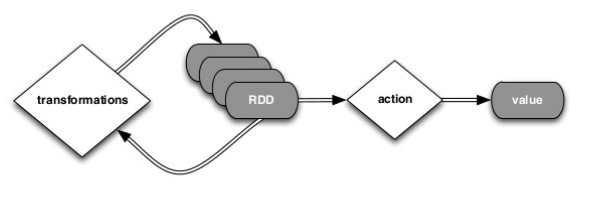
从上图可以看出,对RDD的操作主要有两种,transformations,和actions()
1,transformation
在一个已有的RDD基础上生成另外一个新的RDD.所有transformation都是延迟执行的,一个transformation操作并不是立即执行,只是记住需要对基础数据的transformation操作的过程,直到某个action需要对某个RDD进行计算.若某个RDD会被多次使用,可以调用persist(或者cache)方法保存到内存,或外部存储设备上.当下次调用时,速度会更加快
JavaRDD<String> lines = sc.textFile("data.txt");
JavaRDD<Integer> lineLengths = lines.map(s -> s.length());
int totalLength = lineLengths.reduce((a, b) -> a + b);第一行代码读取一个外部文件形成RDD,该操作只是有一个引用指向该文件,并不会立即执行.第二行通过map计算一行文本的长度,只是记住该map过程,并不是立即执行.直到第三行的reduce操作,Spark会将计算过程分配到各个节点去执行,每个节点运行各自的map过程和本地的reduce过程,只将最终结果返回给drive program.
如果要对lineLenths多次使用,可以添加
lineLengths.persist();在reduce操作之前,这个操作会在第一次计算时将lineLengths变量保存到内存中
Spark的transformation相关操作有
| transformation | 描述 |
|---|---|
| map(func) | 将源数据的每个元素传入函数func中进行计算,返回一个新的RDD |
| filter(func) | 使用func方法从源数据中选择一部分数据形成新的RDD |
| flatMap(func) | 与map类似,但是对每一个输入元素可能会生成0个或多个输出,所以func函数应该返回一个Seq而不是单个元素 |
| sample(withReplacement, fraction, seed) | 对数据的一部分fraction,使用一个随机数生成器seed,生成一个新的RDD |
| union(otherDataset) | 将源数据和新的数据合并到一个新的RDD |
| distinct([numTasks]) | 返回源数据中distinct的数据 |
| groupByKey([numTasks]) | 输入一系列的(K,V)对,返回(K,Seq[V])对 |
| reduceByKey(func,[numTasks]) | 输入一系列的(K,V1)对,返回(K,V2)对,V2是由V1经过func方法计算得到的 |
| sortByKey([ascending],[numTasks]) | 输入一系列的(K,V)对,根据K的值进行升序或降序排练.ascending是一个boolean值 |
| join(otherDateset, [numTasks]) | 当输入(K,V)和(K,W)时,输出(K,Seq[V],Sqe[W])tuples |
| catesian(otherDataset) | 当输入为T和U时,返回(T,U)对 |
2,actions
通过对一个RDD进行计算,返回一个值给driver program
对RDD数据集上运行计算后,将结果传给driver program或写入存储系统,可以触发Job
Actions相关操作
| action | 描述 |
|---|---|
| reduce(func) | 使用func函数计算输入数据,func对两个输入数据进行计算,生成一个计算结果.reduce过程可以和其他节点并行计算 |
| collect() | 将输入数据中所有元素返回成一个数组到driver program中,通常在filter操作,或者其他返回一个足够小的子数据集的操作过程后 |
| count() | 返回输入数据中元素的个数 |
| first() | 返回输入数据中的第一个元素,和take(1)功能相同 |
| take(n) | 返回前n个输入数据形成的数组,目前不支持并行计算,只能在driver program中来计算所有的元素 |
| takeSample(withReplacement, fraction, seed) | 使用一个随机数生成器seed,使用或者不是要replacement,生成输入数据的一个随机样本 |
| saveAsTextFile(path) | 根据给定的path,将数据保存至本地,或者分布式文件系统中 |
| saveAsSequenceFile(path) | 根据给定的path,将Hadoop Sequence数据保存到本地或分布式文件系统中. |
| countByKey() | 只对(K,V)形式的RDD有效,返回一个包含所有key的(K,Int)对的Map |
| foreach(func) | 对每个元素执行func函数 |
传递函数到Spark
Spark的很多功能都需要用户自己写具体实现的函数,如上面transformation和actions中某些参数func.
Spark中的函数,继承自 org.apache.spark.api.java.function
有两种方式来创建该函数:
1,用户自定义类继承Function接口
2,在Java8中,使用lambda expressions来定义一个实现
Spark中的作用域和生命周期
shared variables(共享变量)
1,Broadcast Variables(广播变量)
- 广播变量缓存到各个节点的内存中,而不是每个 Task
- 广播变量被创建后,能在集群中运行的任何函数调用
- 广播变量是只读的,不能在被广播后修改
- 对于大数据集的广播, Spark 尝试使用高效的广播算法来降低通信成本
使用方法:
2,Accumulators(累加器)
- 累加器只支持加法操作
- 累加器可以高效地并行,用于实现计数器和变量求和
- Spark 原生支持数值类型和标准可变集合的计数器,但用户可以添加新的类型
- 只有Driver Program才能获取累加器的值
使用方法:
未完待续~~~















 1430
1430

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









