






某网站新闻抓取
我一直是比较喜欢看新闻类的东西,喜欢了解前沿动态,正好学习了一些爬虫相关的知识,于是对某网站进行抓取,每天获取新闻了解世界科技最新动态
- 首先我们进行数据的准备
我发现他的标题都在一个返回的一串非标准html中,不是json,如图所示
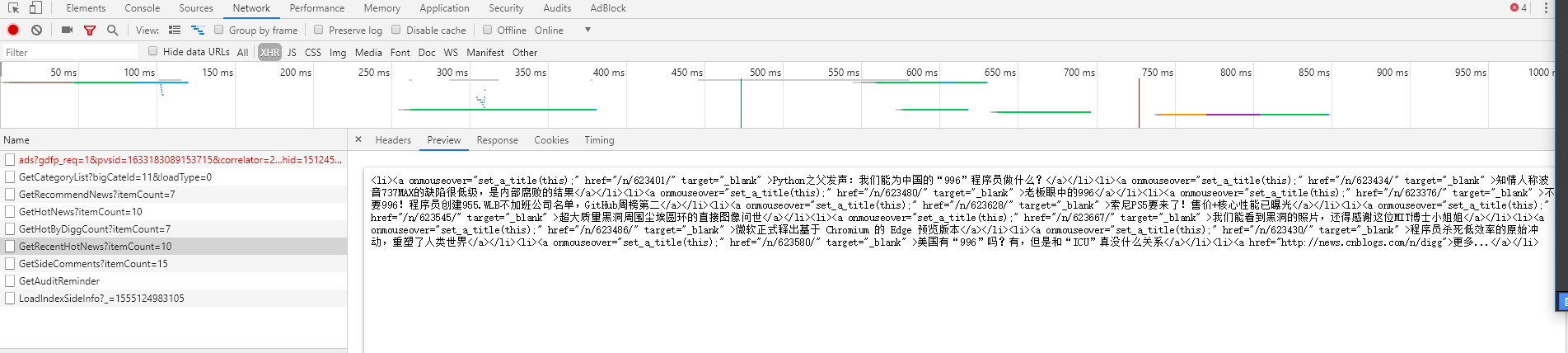
所以我们请求的首地址就是这一个地址,非原网址地址
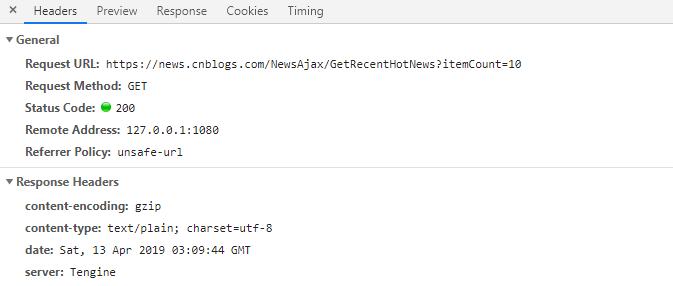
得到数据后我们直接使用re模块处理,findall提取标题和下一个请求的href

- 因为提取出来是很多个数据的列表,所以我们遍历列表来获取新闻页面的具体信息
在此之前我们需要先创建一个文件夹,用来保存获取到的新闻信息(注意,必须使用标准格式写法,否则会出错)

- 爬取详情页的数据依然使用re模块获取所有的新闻信息
如图所示,我们注意到所有的新闻信息均在一个< p >标签下,所以使用re.findall来获取

但是有个问题是我们获取到的数据在一个列表中,所以我们需要转化为一个字符串,每个< p >标签之间加上换行

最后就是数据的后期美化,因为里面夹杂了很多html的标签,所以我们需要替换掉

- 有一个特别需要注意的就是\u3000这个,这是一个是全角的空白符,但是我看了下网上的替换方式均有误,网上的写法 str.replace(u'\xa0', u' ')
我测试后发现这个写法是有错误的,我们只需要进行字符转义即可 new_body = new_body.replace("\u3000", '')
- 然后就是我们的文件保存
- 文件的名字在之前的new_title中,但是我们还需要构造一个索引,所以我们定义一个num去取标题索引,传入标题和新闻内容,每次所以加+1
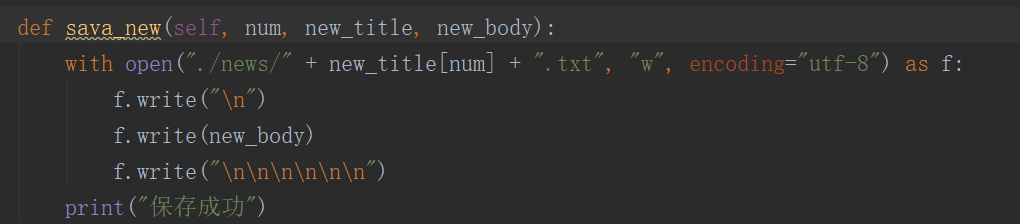
保存文件代码
最后,其实我们可以使用xpath写法,这样就可以省去繁琐的字符替换等等,我为了复习re所以选择了这种写法,也不想改版本了,其他新闻可以修改后面的itemCount=10值爬取所有的新闻,鉴于服务器的负载,我就不做了,有愿意的可以自行尝试
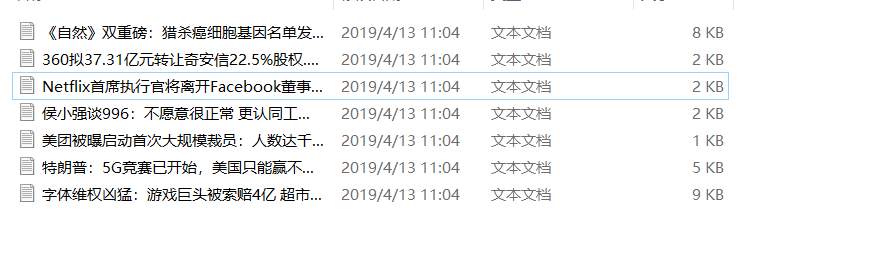
附上一张最后的成果图
此为本人原创所有,如有转载,附上原文链接即可,如有其他需要发电子邮件给我也可ajin_w@163.com
















 2563
2563











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









