






目标:
大量爬取某网站内文本内容
适用于:网站列表内含有许多标题链接如:
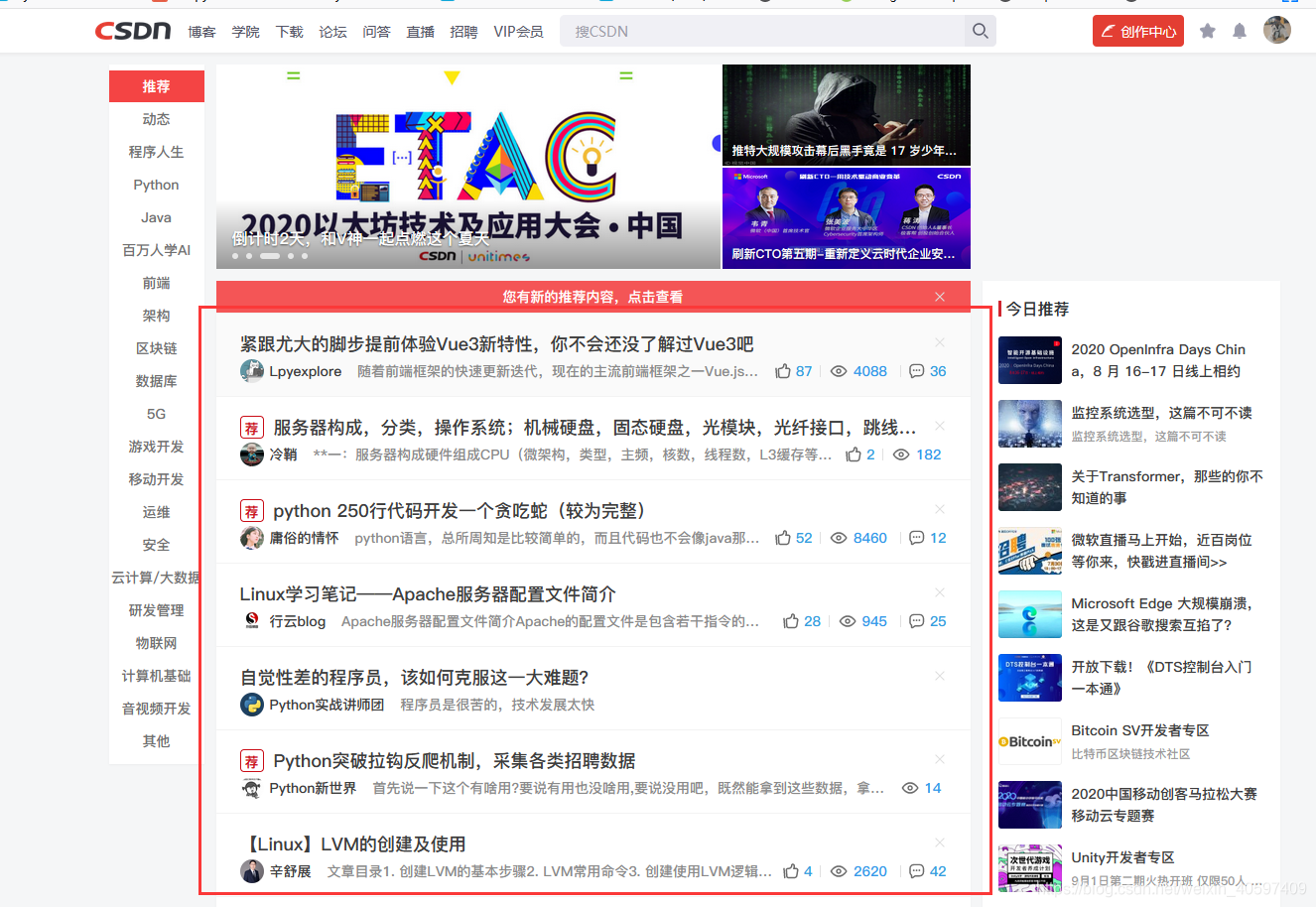
每个标题涵盖一个独有的链接的网站
所用技术:
requests-re-bs4库
# http://sciencechn.com/zx/zixun/
import requests
import re
from bs4 import BeautifulSoup
def getAllHtml(url):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0'}
try:
r = requests.get(url, headers=headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
print('{}爬取出错'.format(url)) #获得url 的 HTML源码 # 获得HTML源码
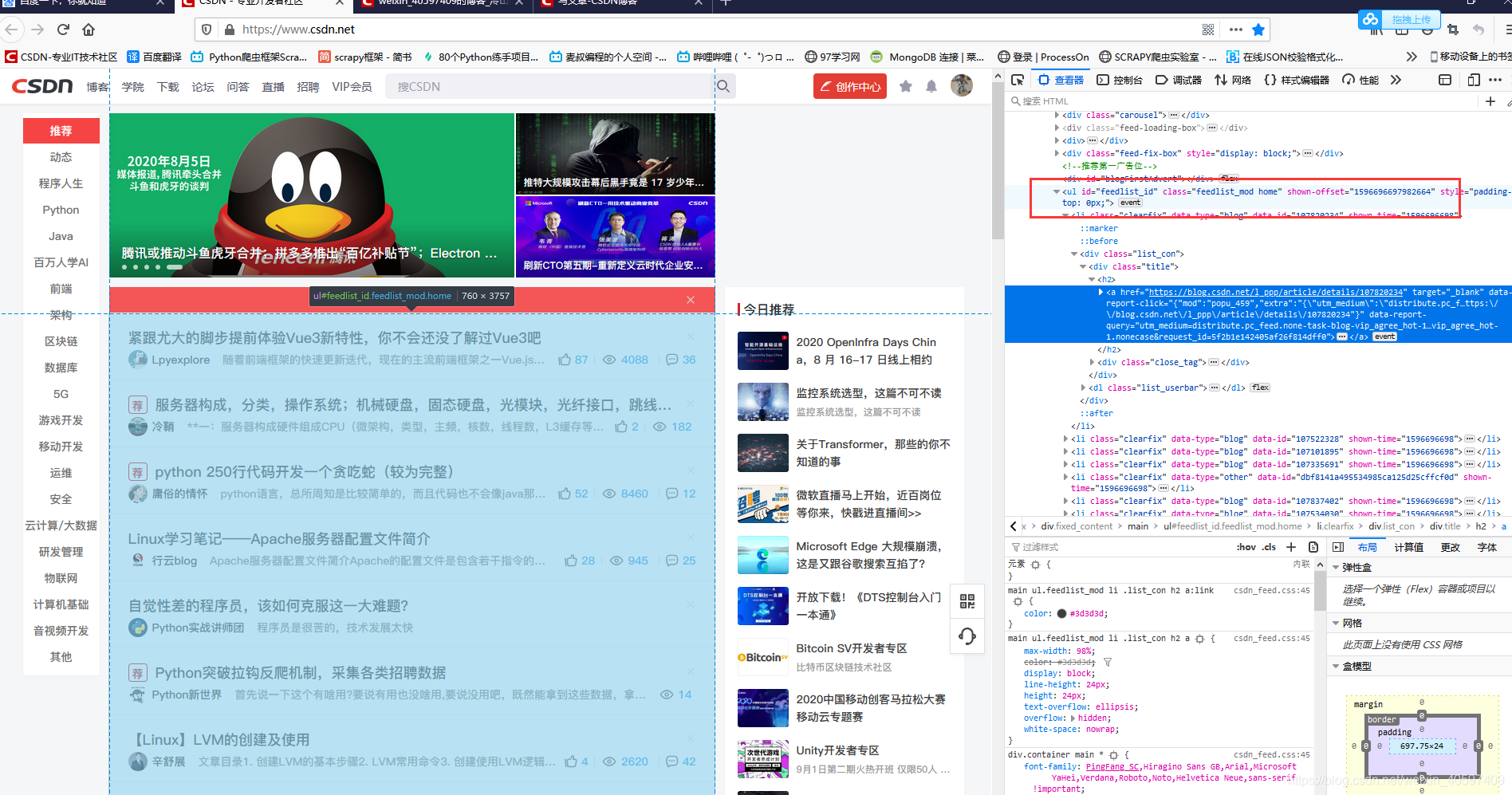
def getUrlList(text):
TitleUrl = []
soup = BeautifulSoup(text, 'html.parser')
titlessss = soup.find_all('li', class_="clearFix thinkTankTag")
for i in titlessss:
houzhuis = re.findall(r'/p/\d+\.html', str(i))
for houzhui in houzhuis:
wanzhengURL = 'https://www.iyiou.com' + houzhui
TitleUrl.append(wanzhengURL)
ttu = list(set(TitleUrl))
return ttu
def doSave(urls):
count = 1
for url in urls:
print('已完成{:.3f}'.format(count/len(urls)))
count += 1
r = getAllHtml(url)
soup = BeautifulSoup(r, 'html.parser')
biaoti = soup.find('h1')
bt = biaoti.text #标题
neirong = soup.find('div',id="post_description")
nr = neirong.text
try:
with open(r'D:\kejiwenben\YiOuZixun.txt', 'a+') as f:
f.write('\n\n\n\n-------------------------------------------------\n\n\n\n')
f.write('\n')
f.write(bt)
f.write('\n')
f.write(nr)
f.write('\n')
f.write('\n\n\n\n-------------------------------------------------\n\n\n\n')
except:
print('解析出错')
for i in range(1,862):
try:
print('第{}页'.format(i))
url = 'https://www.iyiou.com/yhkj/'+ str(i) +'.html'
text = getAllHtml(url)
urls = getUrlList(text)
doSave(urls)
except:
print('看你这代码写的真垃圾')
如下是本地txt文件
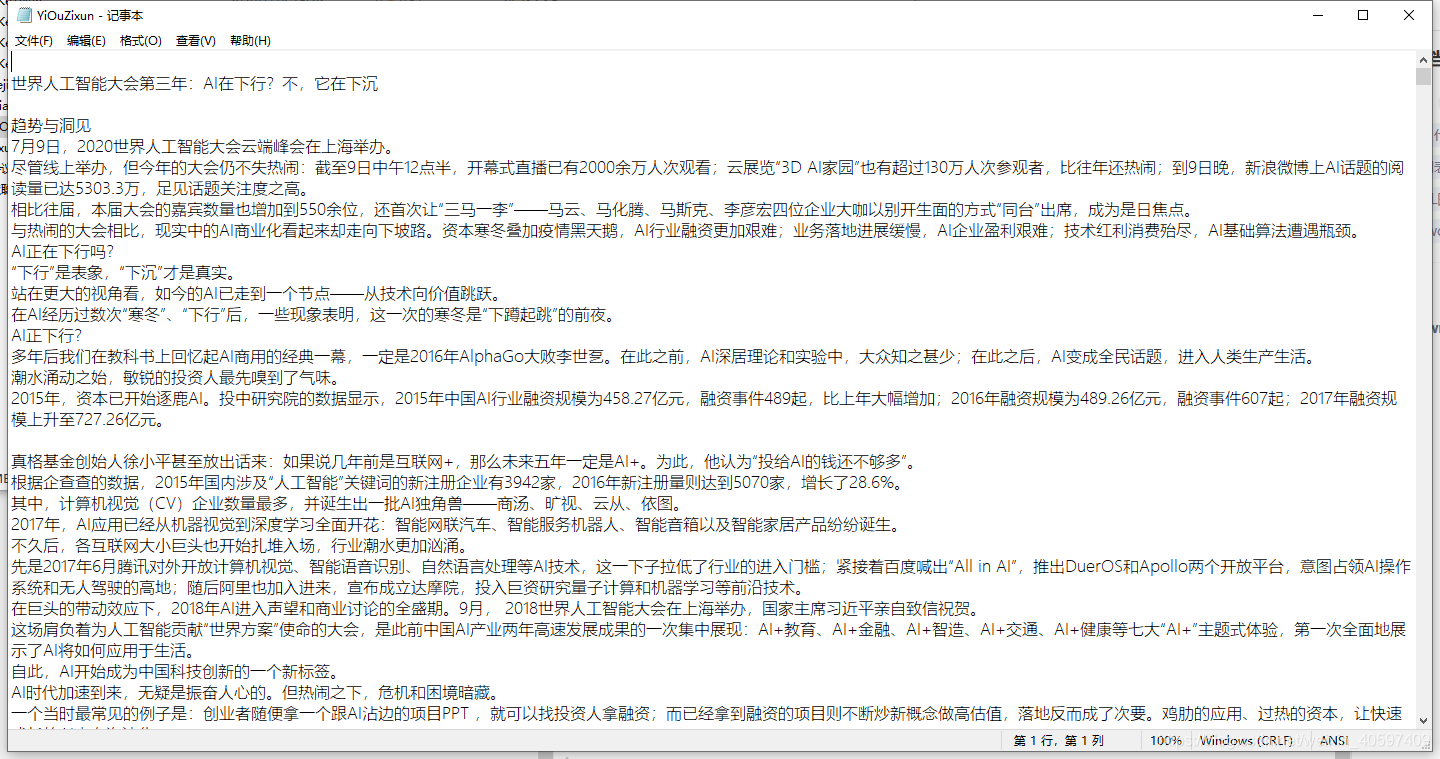














 2059
2059











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









