






2.1.10 C语言中的移位运算
对于x = [x3, x2, x1, x0], x << 2 得到的结果是 [x1, x0, 0, 0]. 右移位运算分为两种, 逻辑右移和算术右移, 逻辑右移是指右移K位, 左端补上K个0, 而算术右移是指左端补上K的x3(最高有效位).
实际上, C语言标准并没有明确定义应该使用哪种类型的右移. 对于无符号数, 右移必须是逻辑的, 对于有符号数则存在争议. (但事实上几乎所以的编译器/ 机器组合都会对有符号数据使用算术右移.)
当移位数量足够大时 : 比如 w >> k, w是32位数, 而k恰好大于或等于32, 其实结果是未定义的(C语言标准并没有对这种情况进行规定)... 许多机器上会用 k mod 位数, 也就是如果k是32, 就相当于不移动, k是33, 就移动1位... 练习题很简单就不写了...
2.2 整数表示
2.2.1 整型数据类型
C语言中支持多种整数数据类型来表述有限范围的整数(char, short, int, long, long long), 这些不同类型所分配的字节数根据机器的字长和编译器不用可能会不太一样, C语言标准只是给出了一个这些数据类型必须保证的取值范围, 而并不做明确要求.
2.2.2 无符号数的编码

2.2.3 补码编码

实际上C语言标准并没有要求使用补发的形式来表示有符号正数, 但几乎所有的机器都是这么做的. 这里给出反码和原码的定义, 只做了解 :

2.2.4 有符号数和无符号数之间转换
总结下来我感觉有如下几点 :
1. 对于相同字长的有符号数和无符号数而言, 互相转化, 他们的位模式(也就是每一位的值)是不变的, 变得只是解释方式...
2. 对于同一个向量x, 如果我们计算B2U(x)-B2T(x), 会发现他们的0到w-2位的解释方式相同, 每一位的权相同, 互相抵消, 对于第w-1位, B2U(x)的权解释为2w-1而B2T(x)则正好相反解释为-2w-1,所以可以发现 B2U(x)-B2T(x) = 2w * xw-1. 利用这个公式我们可以很轻松的得出结论 : T2U(x) = 2w * xw-1 + x (x是补码值).
2.25 C语言中的有符号数和无符号数
C语言支持有符号数和无符号数, 虽然C语言标准未做规定, 但是大多数数字都默认是有符号的, 例如12345或者是0x1A2B这样的常理, 通常被认为是有符号的, 要创建无符号数通常要加上'u' 或者 'U' 的后缀.
同时C语言对于有符号和无符号数的一些处理方式, 常常会导致一些奇怪的结果, 比如当同时将有符号数和无符号数进行运算时, 它默认转化有符号数为无符号数 : 那么在进行类似于 -1 < 0U 的比较时, 这个表达式的结果是0, 而按照正常逻辑应该是1.
另外一个指的注意的问题是在C语言的头文件 limits.h 的头文件中有如下一句话 :
#define INT_MIN (-INT_MAX -1) 为什么要这样麻烦的 -2147483647-1 而不是直接-2147483648呢? 原因就在于C语言编译器是识别到 2147483648 这个token的时候发现它的数值已经超过了int的范围, 已经默认将它识别为了long 或者 long long, 然后在进行取负操作的, 这样的话宏定义出来的值得类型不会是一个int, 所以不行.
2.26 扩展一个数字的位的表示
现在我们来考虑如何将较小的数字的位转换为一个更大的数据类型 (将较大的转化为较小的暂且不考虑), 对于无符号数而言, 只需要在扩展位上全部都补0就行了, 这种运算也称之为零扩展, 对于有符号数(补码数字)我们使用符号扩展, 也就是拓展位上全补上最高有效位的数字... 我们可以尝试着证明为什么这样做的结果是有效果的, 这里我们采用数学归纳法, 先证明对w位的补码数字, 扩展为w+1位时, 该补码数字值不变, 那么对于w+k, k为任意位时, 这个结论仍会成立...
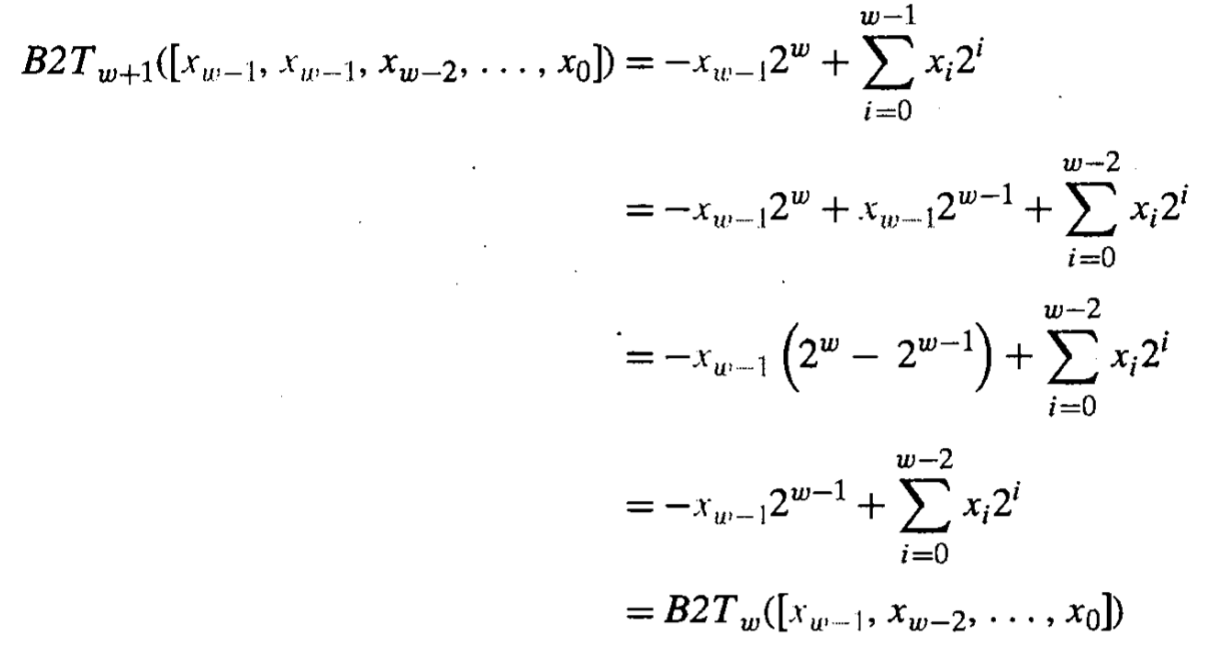
另外还有一点值得注意的地方 : 如果我们将一个一个short转化为一个unsigned时, 结果其实是不确定的, 因为你会发现如果short先转化为unsigned short再转为unsigned int的结果和先转化为int 在转化为unsigned int 得出的结果不同, 而C语言标准规定的规则应该属于后者... 所以 :
1 #include <stdio.h> 2 3 int main(void){ 4 short sx = -12345; 5 unsigned uy = sx; 6 printf("uy = %u\n", uy); // 结果应该是这样 : uy = 4294954951 而不是 53191...
7 return 0;
8 }
2.27 截断数字
现在我们来考虑较大的数字转化为较小的数字(这里的大小指的是表示他们的数的位的大小而不是数字的实际大小), 例如对于w位的数字要截断为k位, 这时我们通常将w位数字的高w-k位舍去, 以这样的方式进行转换. 所以对于无符号数而言, 将它截断到k位就相当于是 x mod 2k, 当然对于有符号而言, 其实位值仍然是低k位的位值, 只是解释方式不同而已.
2.28 关于有符号数与无符号数的建议
所以碰到有符号数和无符号数隐式转换时要特别小心, 比如在练习题中 :
对于length = 0, 如果第14行不将其转换为int的话, length-1的值作为无符号数在这里可以认为无限大, 这个for会无限循环...
1 #include<stdio.h> 2 3 float sum(float a[], unsigned length); 4 5 int main(void){ 6 float a[] = {1.2, 1.3, 1.4}; 7 printf("%f\n", sum(a, 0)); 8 printf("%u\n", 0u - 1); 9 } 10 11 float sum(float a[], unsigned length){ 12 int i = 0; 13 float re = 0; 14 for(; i <= (int)(length - 1); ++i){ 15 re += a[i]; 16 } 17 18 return re; 19 }
这里可能还是不太容易错, 书中的第二个例子非常好 :
如果我们想要写一个函数来判断两个字符串的长短, 极有可能写出下面这个longer() 的这种形式, 不幸的是这是错的, 因为strlen()的返回值是size_t类型, 这个类型实际上在<stdio.h> 是被定义成了unsigned int类型的, 单看strlen() 确实应该被定义成unsigned int类型, 毕竟它代表的是一个长度, 但是两者一结合就错了, 所以特别要小心...
1 #include<stdio.h> 2 #include<string.h> 3 4 int longer(char*s, char* t){ 5 return strlen(s) - strlen(t) > 0; 6 } 7 8 int main(void){ 9 printf("%d\n", longer("abc", "ab")); 10 printf("%d\n", longer("a", "ab")); 11 printf("%d\n", 1u - 2u); 12 printf("%d\n", 1u - 2u > 1000); 13 printf("%d\n", 1u > -1); 14 printf("%d\n", 1u + 1 > 0); 15 }














 809
809











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









