






elasticsearch专栏:https://www.cnblogs.com/hello-shf/category/1550315.html
一、elasticsearch背后有趣的故事
许多年前,一个刚结婚的名叫 Shay Banon 的失业开发者,跟着他的妻子去了伦敦,他的妻子在那里学习厨师。 在寻找一个赚钱的工作的时候,为了给他的妻子做一个食谱搜索引擎,他开始使用 Lucene 的一个早期版本。直接使用 Lucene 是很难的,因此 Shay 开始做一个抽象层,Java 开发者使用它可以很简单的给他们的程序添加搜索功能。 他发布了他的第一个开源项目 Compass。后来 Shay 获得了一份工作,主要是高性能,分布式环境下的内存数据网格。这个对于高性能,实时,分布式搜索引擎的需求尤为突出, 他决定重写 Compass,把它变为一个独立的服务并取名 Elasticsearch。第一个公开版本在2010年2月发布,从此以后,Elasticsearch 已经成为了 Github 上最活跃的项目之一,他拥有超过300名 contributors(目前736名 contributors )。 一家公司已经开始围绕 Elasticsearch 提供商业服务,并开发新的特性,但是,Elasticsearch 将永远开源并对所有人可用。
据说,Shay 的妻子还在等着她的食谱搜索引擎…
二、elasticsearch简介
Elasticsearch 是一个开源的搜索引擎,建立在一个全文搜索引擎库 Apache Lucene™ 基础之上。 Lucene 可以说是当下最先进、高性能、全功能的搜索引擎库--无论是开源还是私有。但是 Lucene 仅仅只是一个库。为了充分发挥其功能,你需要使用 Java 并将 Lucene 直接集成到应用程序中。 更糟糕的是,您可能需要获得信息检索学位才能了解其工作原理。Lucene 非常 复杂。Elasticsearch 也是使用 Java 编写的,它的内部使用 Lucene 做索引与搜索,但是它的目的是使全文检索变得简单, 通过隐藏 Lucene 的复杂性,取而代之的提供一套简单一致的 RESTful API。然而,Elasticsearch 不仅仅是 Lucene,并且也不仅仅只是一个全文搜索引擎。 它可以被下面这样准确的形容:
1 一个分布式的实时文档存储,每个字段 可以被索引与搜索 2 一个分布式实时分析搜索引擎 3 能胜任上百个服务节点的扩展,并支持 PB 级别的结构化或者非结构化数据
2.1、elasticsearch功能
1,分布式的搜索引擎
es可作为一个分布式的搜索引擎,例如百度,淘宝的商品搜索,一般web系统的站内搜索,es都是不错的技术选型。
2,数据分析引擎
es在搜索的基础上提供了丰富的API支持个性化的搜索和数据分析功能,比如电商网站,我们可以查询最近几天的热销商品等。
3,对海量数据进行近实时的处理
es是一个分布式的搜索引擎,es通过集群和内部分片可以将海量数据分散到多台服务器上进行存储和检索,大大提高了其可伸缩性和容灾能力。
所谓近实时是一个相对的概念,一般的如果相应速度能达到秒级别,我们就称为其实近实时的。es的近实时包括两个方面:其一写入的数据在1s后就可以进行检索。其二其检索和分析响应速度可以达到秒级别。
2.2、elasticsearch的特点
1,分布式
es是一个分布式的搜索引擎,可以很好的进行数据的容灾迁移,动态扩容,负载均衡等分布式特性。
2,海量数据
es能处理PB级别的数据,因为es是一个分布式的架构,支持动态扩容,所以对于海量数据的处理和存储都不再是问题。
三、elasticsearch的几个基础概念
1,es中数据的基础概念
index:
索引(index)类似于关系型数据库里的“数据库”——它是我们存储和索引关联数据的地方。
提示:
事实上,我们的数据被存储和索引在分片(shards)中,索引只是一个把一个或多个分片分组在一起的逻辑空间。然而,这只是一些内部细节——我们的程序完全不用关心分 片。对于我们的程序而言,文档存储在索引(index)中。
剩下的细节由Elasticsearch关心 既可。
type:
type的概念类似于MySql中表的概念。
在应用中,我们使用对象表示一些“事物”,例如一个用户、一篇博客、一个评论,或者一封邮 件。每个对象都属于一个类(class),这个类定义了属性或与对象关联的数据。 user 类的对象 可能包含姓名、性别、年龄和Email地址。 在关系型数据库中,我们经常将相同类的对象存储在一个表里,因为它们有着相同的结构。 同理,在Elasticsearch中,我们使用相同类型(type)的文档表示相同的“事物”,因为他们的数 据结构也是相同的。 每个类型(type)都有自己的映射(mapping)或者结构定义,就像传统数据库表中的列一样。所 有类型下的文档被存储在同一个索引下,但是类型的映射(mapping)会告诉Elasticsearch不同 的文档如何被索引。 我们将会在《映射》章节探讨如何定义和管理映射,但是现在我们将依 赖Elasticsearch去自动处理数据结构。
document:
document是es的基本索引单元,document类似于MySql中的一行记录。document的数据是json格式。
id:
在MySql中我们使用主键表示一条记录的唯一性,在es中id就是这种概念。在es中id同样可以是自产生的,es自动生成的ID具备以下特点:自动生成的是 url安全的,base64编码,GUID,保证分布式下ID不冲突(全局唯一ID)。当然也可以我们自己来指定。
2,es在分布式下的几个概念
Cluster(集群):
相信熟悉分布式的小伙伴对这个Cluster都不会陌生,Cluster表示es的一个集群,所谓集群就是有好多es组合成的一个分布式下的es集群。
node(节点):
node就是es集群(Cluster)中的一个es节点就称为node。简单来说可以理解成一个es实例就是该集群中的一个节点。
3,es存储策略上的两个概念
shard(分片)和 replica:
为了将数据添加到Elasticsearch,我们需要索引(index)——一个存储关联数据的地方。实际 上,索引只是一个用来指向一个或多个分片(shards)的“逻辑命名空间(logical namespace)”. 一个分片(shard)是一个最小级别“工作单元(worker unit)”,它只是保存了索引中所有数据的一 部分。道分片就是一个Lucene实例,并且它本身就是一个完整的搜索引擎。我们的文档存储在分片中,并且在分片中被索引,但是我们的应用程序不会直接与它们通信,取而代之的是,直接与索引通信。 分片是Elasticsearch在集群中分发数据的关键。把分片想象成数据的容器。文档存储在分片中,然后分片分配到你集群中的节点上。当你的集群扩容或缩小,Elasticsearch将会自动在你的节点间迁移分片,以使集群保持平衡。 分片可以是主分片(primary shard)或者是复制分片(replica shard)。
你索引中的每个文档属于一个单独的主分片,所以主分片的数量决定了索引最多能存储多少数据。 理论上主分片能存储的数据大小是没有限制的,限制取决于你实际的使用情况。分片的最大容量完全取决于你的使用状况:硬件存储的大小、文档的大小和复杂度、如何索引 和查询你的文档,以及你期望的响应时间。
复制分片只是主分片的一个副本,它可以防止硬件故障导致的数据丢失,同时可以提供读请 求,比如搜索或者从别的shard取回文档。 当索引创建完成的时候,主分片的数量就固定了,但是复制分片的数量可以随时调整。 默认情况下,一个索引被分配5个主分片,一个主分片默认只有一个复制分片。
重点: shard分为两种: 1,primary shard --- 主分片 2,replica shard --- 复制分片(或者称为备份分片或者副本分片)
需要注意的是,在业界有一个约定俗称的东西,单说一个单词shard一般指的是primary shard,而单说一个单词replica就是指的replica shard。
另外一个需要注意的是replica shard是相对于索引而言的,如果说当前index有一个复制分片,那么相对于主分片来说就是每一个主分片都有一个复制分片,即如果有5个主分片就有5个复制分片,并且主分片和复制分片之间是一一对应的关系。
很重要的一点:primary shard不能和replica shard在同一个节点上。重要的事情说三遍:
primary shard不能和replica shard在同一个节点上
primary shard不能和replica shard在同一个节点上
primary shard不能和replica shard在同一个节点上
所以es最小的高可用配置为两台服务器。
四、elasticsearch的安装和开发工具
本人安装的是elasticsearch-6.6.2版本
开发工具:kibana-6.6.2(注意kibana的版本一定要和elasticsearch的版本一致)
另外本地还配置了另一个开发工具:elasticsearch-head
安装方式,大家去百度一下,有很多很详细的安装步骤,在这里就不在赘述了。
简单贴一张图关于如何在kibana中执行curl
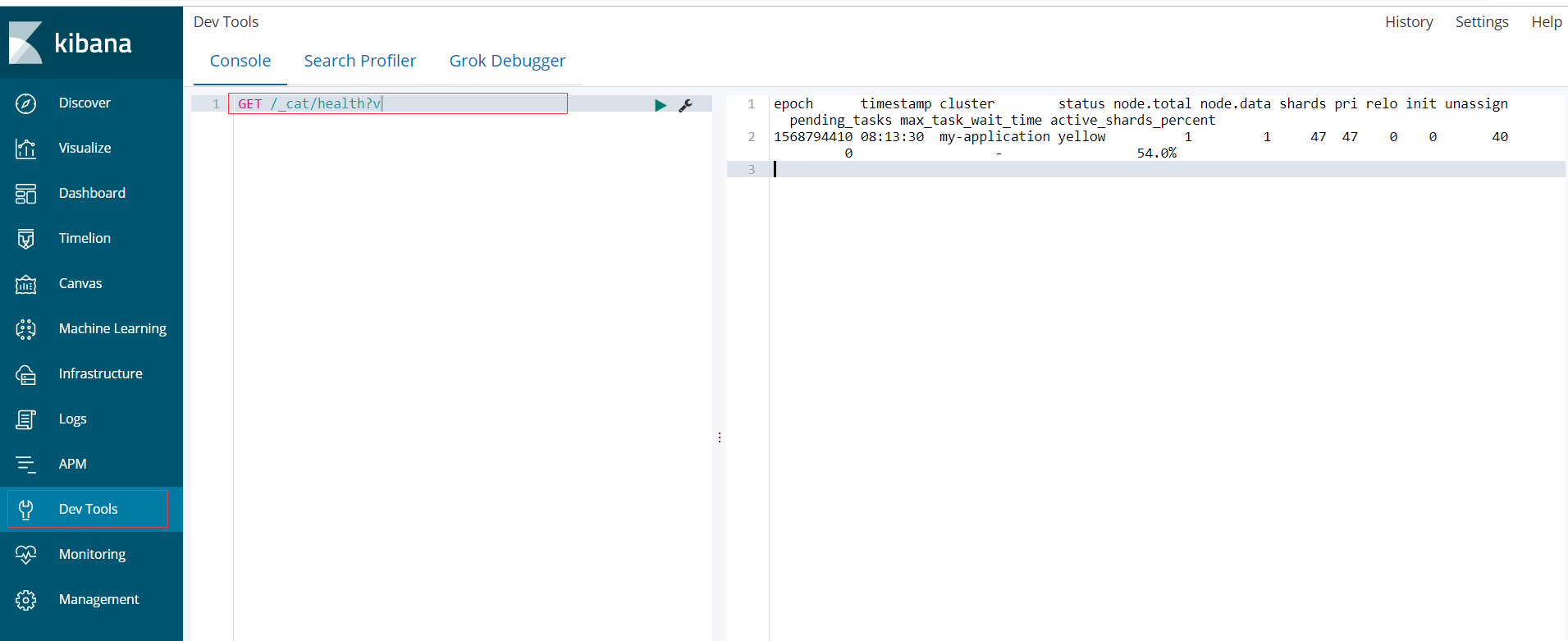
四、集群健康状态
Elasticsearch 的集群监控信息中包含了许多的统计数据,其中最为重要的一项就是集群健康,它在 status 字段中展示为 green 、 yellow 或者 red。
在kibana中执行:GET /_cat/health?v
1 epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent 2 1568794410 08:13:30 my-application yellow 1 1 47 47 0 0 40 0 - 54.0%
其中我们可以看到当前我本地的集群健康状态是yellow ,但这里问题来了,集群的健康状况是如何进行判断的呢?
green(很健康)
所有的主分片和副本分片都正常运行。
yellow(亚健康)
所有的主分片都正常运行,但不是所有的副本分片都正常运行。
red(不健康)
有主分片没能正常运行。
注意:
我本地只配置了一个单节点的elasticsearch,因为primary shard和replica shard是不能分配到一个节点上的所以,在我本地的elasticsearch中是不存在replica shard的,所以健康状况为yellow。
参考文献:
《elasticsearch-权威指南》
如有错误的地方还请留言指正。
原创不易,转载请注明原文地址:https://www.cnblogs.com/hello-shf/p/11393655.html














 2447
2447











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









