






集群分布式查询
elasticsearch的查询分成两个阶段:
- scatter phase:分散阶段,coordinating node会把请求分发到每一个分片
- gather phase:聚集阶段,coordinating node汇总data node的搜索结果,并处理为最终结果集返回给用户分片存储原理
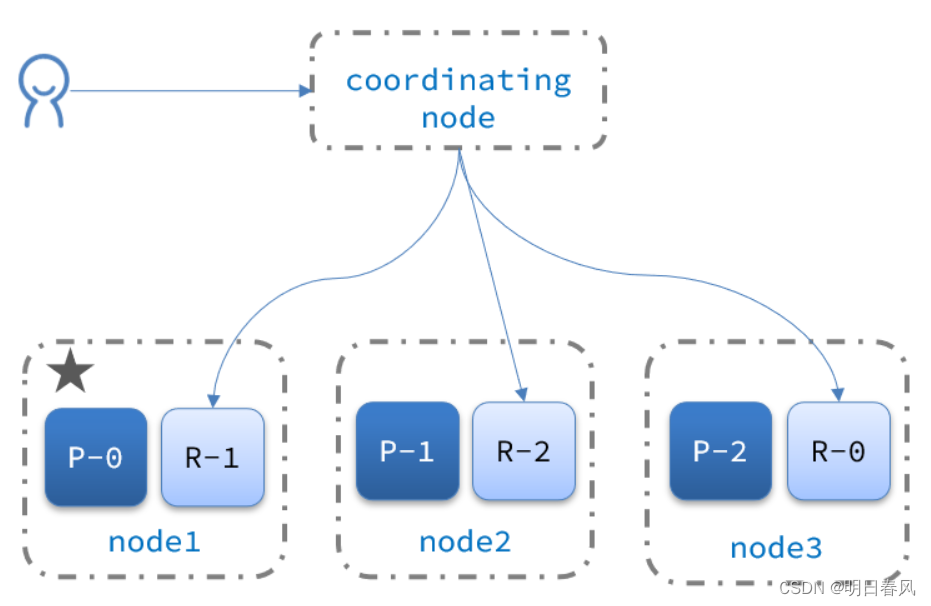
集群分布式存储
当新增文档时,应该保存到不同分片,保证数据均衡,那么coordinating node如何确定数据该存储到哪个分片呢?
分片存储原理:
elasticsearch会通过hash算法来计算文档应该存储到哪个分片:

说明:
- _routing默认是文档的id
- 算法与分片数量有关,因此索引库一旦创建,分片数量不能修改!
新增文档的流程如下:
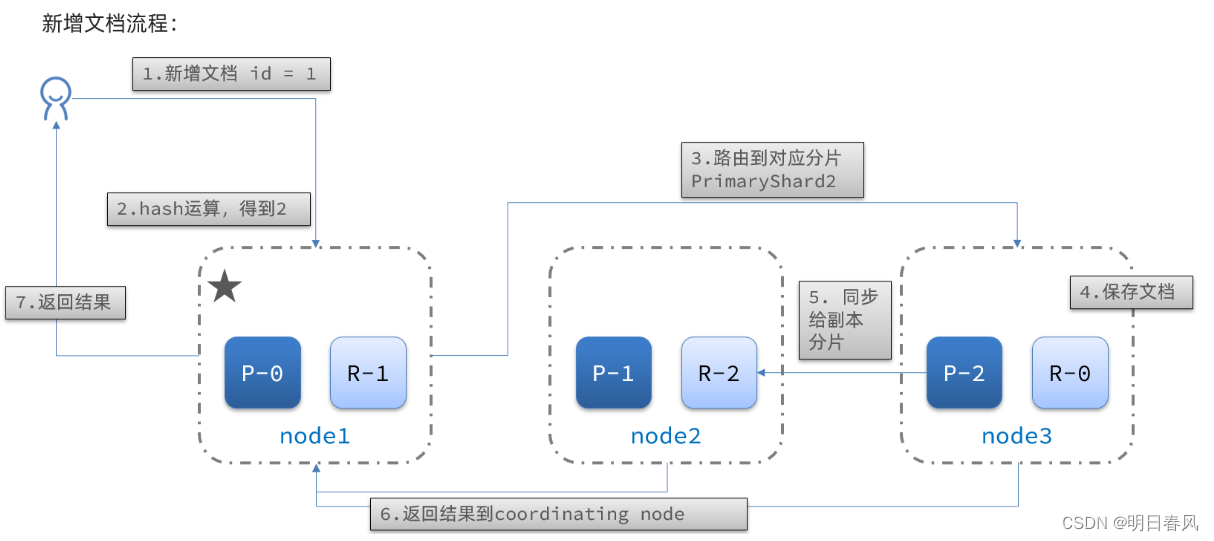
解读:
1)新增一个id=1的文档
2)对id做hash运算,假如得到的是2,则应该存储到shard-2
3)shard-2的主分片在node3节点,将数据路由到node3
4)保存文档
5)同步给shard-2的副本replica-2,在node2节点
6)返回结果给coordinating-node节点














 2272
2272











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









