






基于场景的测试结果
本节介绍三种重要的工作流场景,包括性能注意事项和测试结果。
测试场景的部署拓扑
下图显示了本文档中所述用于所有测试的三个不同的部署拓扑。
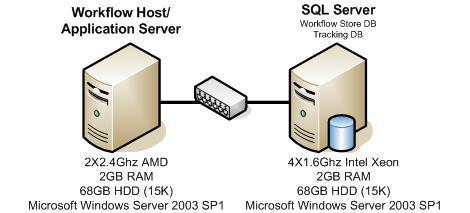
图
4
。用于宿主一体工作流测试的部署拓扑
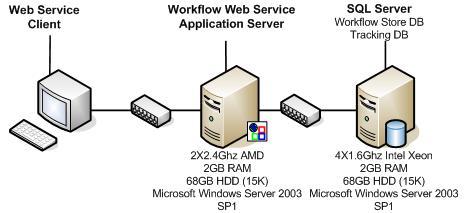
图
5
。用于标准
Web
服务工作流测试的部署拓扑
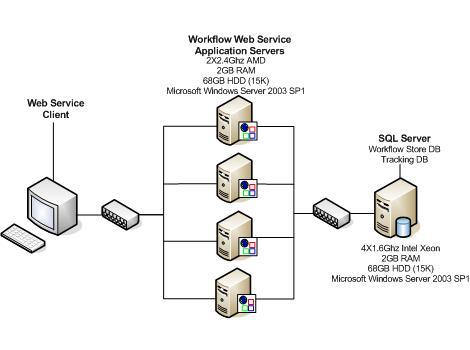
图
6
。用于群集
Web
服务工作流测试的部署拓扑
购物车
Web
服务场景
购物车是一个
ASP.NET Web
服务,电子商务网站可用它来管理用户的购物车。
Web
服务包括下列方法:
- Guid CreateUserBasket()
- Guid AddListItemToBasket itemId int, int quantity,decimal listPrice)
- Guid RemoveListItemFromBasket (Int itemId)
- decimal ReviewOrder ()
- decimal CheckoutOrder ()
一个工作流将用于实现购物车
Web
服务,在以下部分将讨论不同实现选项和它们的性能影响。
这个测试显示了下列关键的工作流性能特征:
- 通常在工作流建模时要考虑减小状态大小并提高性能
- AEC(活动执行上下文)持久化服务对性能的影响
- SqlWorkflowPersistenceService在群集部署时的注意事项
- 工作流状态机的性能特征
- 持久化的卸载/装载模式和保持工作流实例在内存中对性能的影响。
实现
1
第一个实现上
,
我们在每个购物车更新后有一个持久性点,下图显示了在这种情况下的流程:
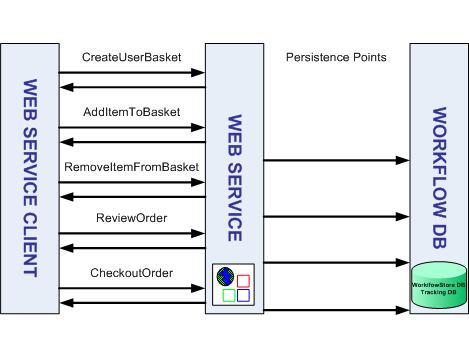
图
7
。持久化场景的数据流
此模型使我们可以长时间在内存中保持工作流,避免进程关闭发生数据丢失。
最好使用工作流服务,
当内存不足或在某一时刻实例空闲后卸载工作流实例。
下图显示了在工作流设计器中的工作流视图:
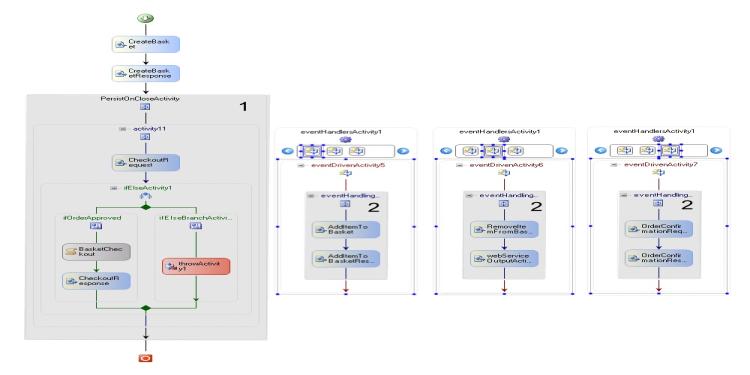
图
8
。购物车
Web
服务
(
实现
1)
工作流设计器视图
PersistOnCloseActivity
(
上图中活动
1)
是用
PersistOnCloseAttribute
属性修饰的自定义活动
[PersistOnClose]
public partial class Activity1: SequenceActivity
{
public Activity1()
{
InitializeComponent();
}
}
EventHandlingSequenceActivity
(
上图中的活动
2)
是一个自定义活动,实现如下:
[PersistOnClose]
public partial class EventHandlingSequence: SequenceActivity, IEventActivity
{
public EventHandlingSequence()
{
InitializeComponent();
}
#region IEventActivity Members
public IComparable QueueName
{
get { return ((IEventActivity)EnabledActivities[0]).QueueName; }
}
public void Subscribe(ActivityExecutionContext parentContext, IActivityEventListener<QueueEventArgs> parentEventHandler)
{
((IEventActivity)EnabledActivities[0]).Subscribe(parentContext, parentEventHandler);
}
public void Unsubscribe(ActivityExecutionContext parentContext, IActivityEventListener<QueueEventArgs> parentEventHandler)
{
((IEventActivity)EnabledActivities[0]).Unsubscribe(parentContext, parentEventHandler);
}
#endregion
}
在这个自定义活动中实现了
IEventActivity
接口,这
使其在内部可以反复执行(
re-execution
)
WebServiceInputActivity
活动。由于有
AEC
克隆,这时会有小小的性能下降。
实现
2
在此实现中,如图所示在
ListenActivity
活动
内部使用了一个
WhileActivity
活动来反复执行
WebServiceReceiveActivity
活动。由于在
WhileActivity
活动中需要进行更复杂的
AEC
克隆,所以这个实现的性能要低一些。
下图显示了工作流的实现:

图
9
。购物车
Web
服务场景
(
实现
2)
的工作流设计器视图
上述
1
和
2
两种实现在群集部署时只可以使用会话关联(
session affinity
)模式(即一个浏览器会话的所有请求由同一个工作流运行时来处理)。
实现
3
在购物车
Web
服务的这一实现中使用了与实现
1
相同的工作流模型,但是自定义活动中是强行持久化的,在工作流实例变为空闲时将被运行时卸载。为此,
SqlWorkflowPersistenceService.UnloadOnIdle
属性被设置为
true
。
下图显示了这时场景的流程:
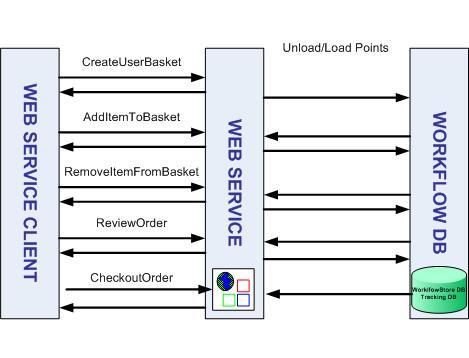
图
10
。在
UnloadOnIdle
属性设置为
true
时的场景数据流
在这种情况下,当会话的首个请求收到时,工作流实例状态才从数据库中装载。与以前实现相比,这种设计具有更高的性能开销,但更易于实现,并且在群集部署时无需应用会话关联(
session affinity
)。
以下
SqlWorkflowPersistenceService
配置通常用于这种情况:
<add type="System.Workflow.Runtime.Hosting.SqlWorkflowPersistenceService, System.Workflow.Runtime, Version=3.0.00000.0, Culture=neutral, PublicKeyToken=31bf3856ad364e35" unloadOnIdle="true" OwnershipTimeoutSeconds="60" />
实现
4
可以购物车
Web
服务实现为具有三个状态的工作流状态机:

图
11
。购物车
Web
服务方案
(
实现
4)
工作流设计器视图
在
ModifyBasketState
中由每个事件来驱动的活动,与顺序工作流实现相同的逻辑,并且包括
PersistOnClose
属性的自定义活动。
如稍后的性能结果所示,与顺序工作流的情况相比,因为包括用
SetState
活动切换到新的状态,工作流将有更多的活动,从而为这种实现带来了更多的性能开销。
购物车场景的性能测试结果
本节给出了购物车方案的不同实现的性能测试结果。
在客户端计算机上运行一个测试程序调用
Web
服务完成以下操作模拟多个用户的并发访问(最高到
50
个并发用户)。
|
调
用
方
法
|
每个会话里调用方法的次数
|
|
CreateUserBasket
|
1
|
|
AddListItemToBasket
|
2
|
|
RemoveListItemFromBasket
|
1
|
|
ReviewOrder
|
1
|
|
CheckoutOrder
|
1
|
在每个用户会话会调用六个
Web
服务。
下表显示的是上述每个不同实现和配置时持久点和每个实例装载
/
卸载的次数:
|
实现
|
持久点
|
装载点
|
卸载点
|
|
实现
1
和
2
|
6*
|
0
|
0
|
|
实现
3
|
6*
|
5
|
5
|
|
实现
4
|
6*
|
0
|
0
|
*
包含在工作流完成时要删除工作流实例数据的持久点。
下表给出的是在按第二种配置拓朴(图
5
)部署时的吞吐量和总的
CPU
使用率。
|
实
现
|
每秒
Web
服务请求数
|
工作流服务器
CPU
使用率
|
SQL
服务
CPU
使用率
|
|
实现
1
|
168.3
|
92.9
|
10.8
|
|
实现
2
|
113.4
|
93.9
|
9.2
|
|
实现
3
|
92.7
|
92.8
|
9.0
|
|
实现
4
|
114.8
|
94.3
|
8.1
|
下表显示为四种不同的实现时工作流状态持久化时的最大值。
|
实
现
|
工作流状态持久化最大值
|
|
实现
1
|
9.59 KB
|
|
实现
2
|
10.47 KB
|
|
实现
3
|
8.63 KB
|
|
实现
4
|
12.63 KB
|
这四种实现都可以部署在(图
6
)所示的群集配置拓朴中,下图给出了在群集时通过增加服务器数量能达到的吞吐量。

图
12
。购物车
Web
服务群集部署时的测试结果
文档评审场景
在文档评审场景中,需要控制一个有多人需要独立提交评审反馈的文档批准
/
评审过程,它支持动态地添加新的评审参与者和授权者。
下面的工作流设计器视图反映了这种场景的情况。
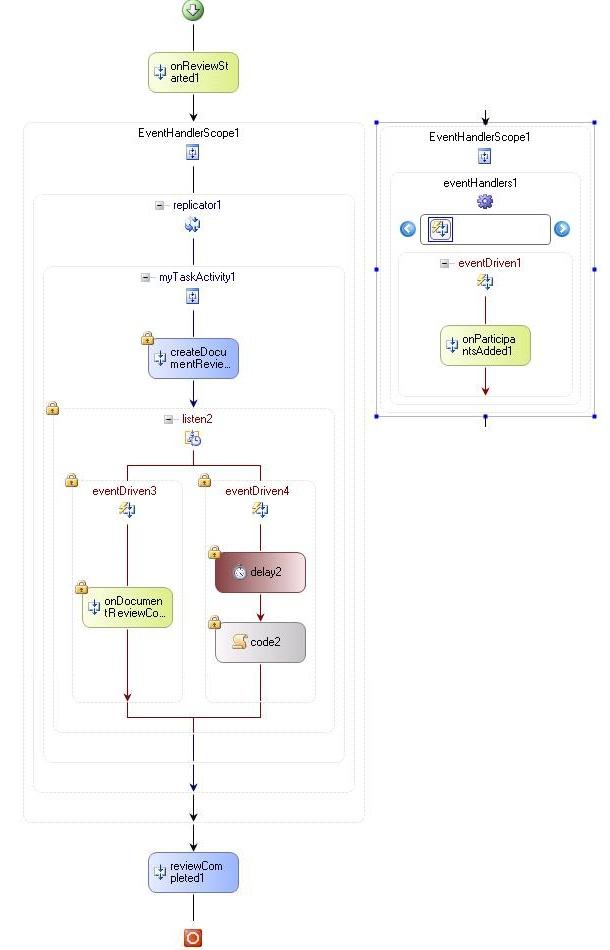
图
13
。文档评审场景的工作流设计器视图
上面图中的
ReplicatorActivity
(replicator1)
按评审参与者的个数创建多个任务活动,然后并行而不是顺序地执行它们。因此,文档评审中的多个参与者,极大地增加了工作流状态,从而带来更高的序列化和持久性开销。
这个测试显示了以下关键的工作流性能特征:
- 在中等规模的单位工作流实例状态需要频繁地装载/卸载的场景中,工作流的吞吐量特征。
- 用不同设置添加SQLTrackingService 对性能的影响。
文档评审场景的性能测试结果
测试模拟了有三个参与者的一次文档评审:文档所有者发出一个消息
(DocumentReviewStarted)
并等待另外三个参与者的反馈
(DocumentReviewCompletion)
。每个参与者在规定的时间内完成评审,评审完成后,
文档所有者会收到通知。
在此场景中,缺省的
SqlWorkflowPersistenceService
被使用,
并且工作流运行时配置为当工作流实例空闲时立即被卸载。测试程序是一个简单的控制台程序,同时充当工作流的宿主程序。只有在工作流实例装载到内存,执行完成,并成功卸载后,测试程序才会发送
DocumentReviewCompletion
消息。
在工作流实例创建后会在启动它之前发送
DocumentReviewStarted
消息
,这样可以减少一个卸载点:
WorkflowInstance inst = this._container.CreateWorkflow(typeof(DLC.Workflow1));
// Raise DocumentReviewStarted event before starting the workflow instance. this._docImpl.RaiseOnReviewStarted(onReviewStartedEventArgs);
inst.Start();
下表是在测试场景部署拓扑一节的(图
4
)中描述的部署下测试吞吐量的结果。
|
测试名称
|
每秒消息数
|
每秒工作流执行次数
|
每秒装载
/
卸载点数
|
工作流
CPU
占用
|
SQL
的
CPU
占用
|
|
文档评审
(
3
个参与者
)
|
76.2
|
19.05
|
57.13
|
93.9
|
7.05
|
|
文档评审
(
3
个参与者)
+
缺省
SQL
跟踪设置
|
61.2
|
15.3
|
45.9
|
92
|
32.5
|
|
文档评审
(
3
个参与者)
+
非批处理模式
SQL
跟踪设置
|
55.2
|
13.8
|
41.31
|
87.8
|
41.25
|
带
WF Rules Engine
的员工级别评定场景
员工级别评定是一个依据一个规则集基于几个输入参数确定员工级别的一个测试场景。
一个
RuleSet
通常可看作一些断言式的契约,其中规则的顺序应该是与结果无关的。下面是一个例子,演示了如何根据条件使用规则集来确定一个候选人是否符合工作岗位的条件。
|
规则
|
条
件
|
|
R01
|
IF Experience == "low" THEN Position="Intern"
|
|
R02
|
IF Experience == "fair" THEN Position="Junior"
|
|
R03
|
IF Experience == "good" THEN Position="Senior"
|
|
R04
|
IF Education == "incomplete" THEN Experience="low"
|
|
R05
|
IF Education == "good" AND YearsWorked > 5 THEN Experience="good"
|
|
R06
|
IF Education == "good" AND YearsWorked <= 5 THEN Experience="fair"
|
|
R07
|
IF Education == "high" AND YearsWorked > 2 THEN Experience="good"
|
|
R08
|
IF Education == "high" AND YearsWorked <= 2 THEN Experience="fair"
|
|
R09
|
IF Degree == "PhD" THEN Education="high"
|
|
R10
|
IF Degree == "Bachelors" OR Degree == "Masters" THEN Education="good"
|
|
R11
|
IF Degree == "None" THEN Education="incomplete"
|
假定一个候选人有硕士学位(学位==硕士)并且已在某个行业工作
3
年(工作经验==
3
年),其它情况未知。如果你从按
R01
到
R11
的顺序跟踪规则集的执行,你将会看到下列顺序。
R01
是假,不执行
R02
是假,不执行
R03
是假,不执行
R04
是假,不执行
R05
是假,不执行
R06
是假,不执行
R07
是假,不执行
R08
是假,不执行
R09
是假,不执行
R10
是真,此时设置
Education
属性为
"good"
,这将会反转执行顺序以便重新计算依赖于
Education
属性的条件,规则集的执行将返回到
R04
R04
重计算仍是假,不执行
R05
重计算仍是假,不执行
R06
重计算是真,设置
Experience
属性为
"fair"
,又将反转执行顺序去计算那些依赖于
Experience
属性的条件,这里将反转到
R01
R01
重计算仍是假,不执行
R02
重计算是真,设计
Position
属性为
"Junior"
R03
重计算仍是假
R04, R05, R06
因为已经计算过被跳过
R07
重计算仍是假,不执行
R08
重计算仍是假,不执行
R09
和
R10
因为已经计算过被跳过
R11
是假,不执行
此时,
RuleSet
已计算出候选人的教育程度属性是
"good"
,经验属性是
"fair"
,应该能够获得
" Junior "
职位,看到了,经过了
21
步才计算出这个结果。
RuleSet
的问题是一些规则
会在没有足够的信息之前进行计算,因此当需要的信息可用之后,这些规则将被重计算(
re-evaluated
)。
可以指派优先级给规则,以对在其执行顺序进行一些控制。具有较高的优先级值的规则将具有较低的优先级值的规则之前执行。在以下示例,给
RuleSet
分配了优先级以最小化(此时甚至是消除了)过早的规则计算。
|
优先级
|
规则
|
条件
|
|
2
|
R09
R10
R11
|
IF Degree == "PhD" THEN Education="high"
IF Degree == "Bachelors" OR Degree == "Masters" THEN Education="good"
IF Degree == "None" THEN Education="incomplete"
|
|
1
|
R04
R05
R06
R07
R08
|
IF Education == "incomplete" THEN Experience="low"
IF Education == "good" AND YearsWorked > 5 THEN Experience="good"
IF Education == "good" AND YearsWorked <= 5 THEN Experience="fair"
IF Education == "high" AND YearsWorked > 2 THEN Experience="good"
IF Education == "high" AND YearsWorked <= 2 THEN Experience="fair"
|
|
0
|
R01
R02
R03
|
IF Experience == "low" THEN Position="Intern"
IF Experience == "fair" THEN Position="Junior"
IF Experience == "good" THEN Position="Senior"
|
现在,执行规则时将按优先级顺序执行,而不是从上到下。优先级为
2
规则被首先执行,然后是优先级为
1
的规则,最后才是优先级为
0
的规则。
RuleSet
执行顺序如下所示:
R09
是假,不执行
R10
是真,设置
Education
属性为
"good"
,这将反转执行顺序去重计算那些依赖于
Education
属性的条件,然而因为之前没有依赖的规则,所以继续执行到
R11
R11
是假,不执行
R04
是假,不执行
R05
是假,不执行
R06
是真,设置
Experience
属性为
"fair"
,这将反转执行顺序去重计算那些依赖于
Experience
属性的条件,然而因为之前没有依赖的规则,所经继续执行到
R07
R07
是假,不执行
R08
是假,不执行
R01
是假,不执行
R02
是真,设置
Position
属性为
"Junior"
R03
是假,不执行
此时,每个规则都已计算,每个依赖项也已被满足。现在这个基于优先级的
RuleSet
与原来
RuleSet
提供了相同的结果:候选人的教育程度属性是
"good"
,经验属性是
"fair"
,应该能够获得
" Junior "
职位。但是,这次只计算了
11
步,而且没有规则被重复计算。
还有,这个
RuleSet
已不再需要反转执行顺序了,
RuleSet
被
按优先级顺序执行并得到了相同的结果。为此,要将
RuleSet
的
ChainingBehavior
属性设置为
RuleChainingBehavior.none
。
由于避免了依赖项的重计算,性能也得到改善。因为如果规则不是按优先级而是按任意顺序执行,将无法计算出正确的结果,所以此时优先级的值变得非常重要。
职位级别分配的测试结果
通过使用
RulesEngine
类按“基于顺序”和“基于优先级”的不同配置循环运行上述
RuleSe
100
将并测量执行时间,表中的第
3
列是
100
次的平均执行时间。
|
基于顺序
(1)
|
基于优先级
(2)
|
平均执行时间
(ms)
|
|
Yes
|
No
|
235.5
|
|
Yes
|
Yes
|
192.7
|
|
No
|
Yes
|
111.1
|
(1)
基于顺序:一个规则的动作可能会导致重新计算相关的依赖规则
(2)
基于优先级:规则具有不同的优先级来控制它们被计算的顺序















 140
140











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









