






Q1: Assuming that we train the neural network with the same amount of training examples, how to set the optimal batch size and number of iterations? (where batch size * number of iterations = number of training examples shown to the neural network, with the same training example being potentially shown several times)
It has been observed in practice that when using a larger batch there is a significant degradation in the quality of the model, as measured by its ability to generalize. Large-batch methods tend to converge to sharp minimizers of the training and testing functions -- and that sharp minima lead to poorer generalization. In contrast, small-batch methods consistently converge to flat minimizers. Large-batch methods are almost invariably attracted to regions with sharp minima and that, unlike small batch methods, are unable to escape basins of these minimizers.
When the slope is too steep, the gradient descent step can actually move uphill. Make a second-order Taylor series approximation to the cost function f(x):

Take the gradient descent step,
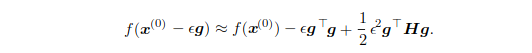
Q2: why is optimization so important?
Cost functions in deep learning may be approximated to well-studied functions in convex optimization or linear programming locally. For example, we optimize functions that may have many local minima that are not optimal and many saddle points surrounded by very flat regions.
Q3_1: Why does input normalization help?
normalization (shifting inputs to zero-mean and unit variance) is often used as a pre-processing step to make the data comparable across features. If we don't perform normalization, the cost function may be like a very elongated bowl and the SGD might need a lot of steps to oscillate back and forth.
Q3_2: Why does batch normalization help?
Perform normalization to the values even deep in some hidden layer in the neural networks. Batch normalization makes the neural network much more robust to the choice of hyper-parameters and will also enable you to much more easily train even very deep networks.
Q4: why do we need orthogonalization in neural network training?
With acknowledgment to Week 1, Course 2, deeplearning.ai

Q5_1: why do we use logistic regression?
If we use a linear regression model to do classification, the error has only a finite number of possibilities and the normalized error assumption in linear regression will not be applicable. The classification also requires linear regression values to fall between 0 and 1.
Q5_2: Derive multinomial regression
Thanks to https://en.wikipedia.org/wiki/Multinomial_logistic_regression

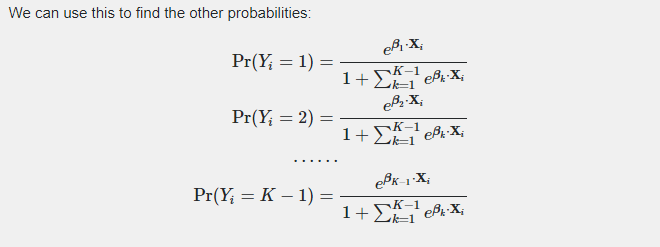
Q6: why is gradient descent with momentum usually better than the plain gradient descent?
The gradient descent with momentum performs a weighted average of recently computed gradients and removes oscillation, so it approaches the optimal point faster.
Q7: The difference between max pooling and average pooling?
we perform pooling to increase invariance, reduce computation complexity (as 2*2 max pooling/average pooling reduces 75% data) and extract low-level features from the neighbourhood.
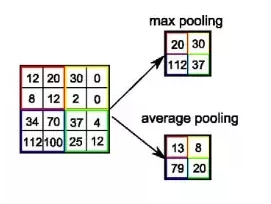
Max pooling extracts the most important features like edges whereas, average pooling extracts features smoothly. In global average pooling, a tensor with dimensions h×w×d is reduced in size to have dimensions 1×1×d.
Q8: why do we use learning rate decay?
If you were to slowly reduce your learning rate, then during the initial phases while your learning rate is still large, you can still have relatively fast learning. But as the lr gets smaller, the steps you take will be slower and smaller. So you end up oscillating in a tighter region around the minimum rather than wandering away even as training goes on and on. But in pytorch, there isn't a good way to implement this currently (Apr. 2nd, 2018). If you create a new optimizer, the previous momemtum (or other states) will be discarded and you can see an increase in the loss when you construct a new optimizer to decay the learning rate although the cost of constructing a new one is negligible.
Q9: why do we use weight decay?
To avoid over-fitting, it is possible to regularize the cost function. An easy way to do that is by introducing a zero mean Gaussian prior over the weights, which is equivalent to changing the cost function to
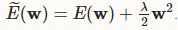
And the new step will be

The new term coming from the regularization causes the weight to decay in proportion to its size.
Q10: what is a deconvolutional layer?
Deconvolution Layer is a very unfortunate name and is simply padding more zeros. For example, if we process a 2*2 patch that is padded with 2 zeros both on the left and on the right with a 3*3 kernel and stride 1, the patch becomes [(2+2*2-3)/1+1]=4. for visualizations see https://datascience.stackexchange.com/questions/6107/what-are-deconvolutional-layers














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









